来源:Scrapy安装、爬虫入门教程、爬虫实例(豆瓣电影爬虫)
该例子中未使用代理和模拟浏览器,所以会导致403Forbidden,以下已优化。
代码放在附件中。
采用settings.py的方式进行设置user agent和proxy列表
http://www.tuicool.com/articles/VRfQR3U
http://jinbitou.net/2016/12/01/2229.html (本文采用这种方式模拟浏览器和使用代理)
网站的反爬虫策略:
http://www.cnblogs.com/tyomcat/p/5447853.html
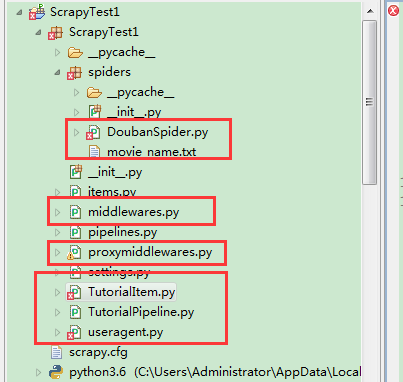
1、在Item中定义自己要抓取的数据(也可新建TutorialItem文件):
from scrapy.item import Item,Field
class TutorialItem(Item):
movie_name = Field()
movie_director = Field()
movie_writer = Field()
movie_roles = Field()
movie_language = Field()
movie_date = Field()
movie_long = Field()
movie_description = Field()
2、然后在spiders目录下编辑Spider.py那个文件(自己新建了DoubanSpider.py文件)
注意数据的获取:
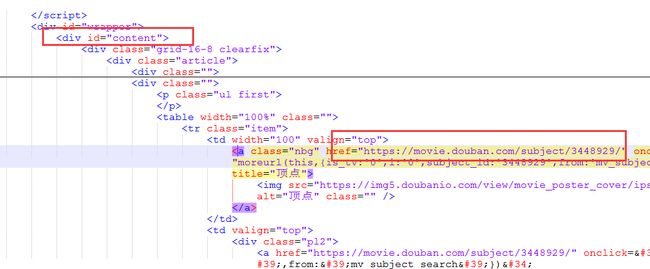
hxs = HtmlXPathSelector(response)
movie_link = hxs.select('//*[@id="content"]/div/div[1]/div[2]/table[1]/tr/td[1]/a/@href').extract()
#coding=utf-8
import sys
#reload(sys)
#pythonĬ�ϻ�������ʱascii
#sys.setdefaultencoding("utf-8")
from scrapy.spider import BaseSpider
from scrapy.http import Request
from scrapy.selector import HtmlXPathSelector
from ScrapyTest1.TutorialItem import TutorialItem
import re
import os
class DoubanSpider(BaseSpider):
name = "douban"
allowed_domains = ["movie.douban.com"]
start_urls = []
def start_requests(self):
print("=======================",os.getcwd())
file_object = open('F:\workspace-jxc\ScrapyTest1\ScrapyTest1\spiders\movie_name.txt','r')
try:
url_head = "http://movie.douban.com/subject_search?search_text="
for line in file_object:
self.start_urls.append(url_head + line)
for url in self.start_urls:
yield self.make_requests_from_url(url)
finally:
file_object.close()
#years_object.close()
def parse(self, response):
#open("test.html",'wb').write(response.body)
hxs = HtmlXPathSelector(response)
#movie_name = hxs.select('//*[@id="content"]/div/div[1]/div[2]/table[1]/tr/td[1]/a/@title').extract()
movie_link = hxs.select('//*[@id="content"]/div/div[1]/div[2]/table[1]/tr/td[1]/a/@href').extract()
#movie_desc = hxs.select('//*[@id="content"]/div/div[1]/div[2]/table[1]/tr/td[2]/div/p/text()').extract()
print("+++++++++++++++++:",movie_link)
if movie_link:
yield Request(movie_link[0],callback=self.parse_item)
def parse_item(self,response):
hxs = HtmlXPathSelector(response)
movie_name = hxs.select('//*[@id="content"]/h1/span[1]/text()').extract()
movie_director = hxs.select('//*[@id="info"]/span[1]/span[2]/a/text()').extract()
movie_writer = hxs.select('//*[@id="info"]/span[2]/span[2]/a/text()').extract()
#爬取电影详情需要在已有对象中继续爬取
movie_description_paths = hxs.select('//*[@id="link-report"]')
print("==============================")
print(movie_name,movie_director,movie_writer)
print("==============================")
movie_description = []
for movie_description_path in movie_description_paths:
movie_description = movie_description_path.select('.//*[@property="v:summary"]/text()').extract()
#提取演员需要从已有的xPath对象中继续爬我要的内容
movie_roles_paths = hxs.select('//*[@id="info"]/span[3]/span[2]')
movie_roles = []
for movie_roles_path in movie_roles_paths:
movie_roles = movie_roles_path.select('.//*[@rel="v:starring"]/text()').extract()
#获取电影详细信息序列
movie_detail = hxs.select('//*[@id="info"]').extract()
item = TutorialItem()
item['movie_name'] = ''.join(movie_name).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';')
#item['movie_link'] = movie_link[0]
item['movie_director'] = movie_director[0].strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') if len(movie_director) > 0 else ''
#由于逗号是拿来分割电影所有信息的,所以需要处理逗号;引号也要处理,否则插入数据库会有问题
item['movie_description'] = movie_description[0].strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') if len(movie_description) > 0 else ''
item['movie_writer'] = ';'.join(movie_writer).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';')
item['movie_roles'] = ';'.join(movie_roles).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';')
#item['movie_language'] = movie_language[0].strip() if len(movie_language) > 0 else ''
#item['movie_date'] = ''.join(movie_date).strip()
#item['movie_long'] = ''.join(movie_long).strip()
#电影详情信息字符串
movie_detail_str = ''.join(movie_detail).strip()
#print movie_detail_str
movie_language_str = ".*语言: (.+?)
(\S+?).*"
movie_long_str = ".*片长:
3、编辑pipelines.py文件,可以通过它将保存在TutorialItem中的内容写入到数据库或者文件中
(自己新建了TutorialPipeline.py文件)
注意新建的pipeline.py文件需要在settings.py中配置:
ITEM_PIPELINES = {
'ScrapyTest1.TutorialPipeline.TutorialPipeline': 1,
}
import json
import codecs
class TutorialPipeline(object):
def __init__(self):
print("Pipeline-111111111111111111111")
self.file = codecs.open('data.dat',mode='wb',encoding='utf-8')
def process_item(self, item, spider):
print("Pipeline-222222222222222222222")
print("dict(item):=======================",dict(item))
line = json.dumps(dict(item)) + '\n'
self.file.write(line)
return item
4、爬虫开始
win-》CMD-》 scrapy crwal douban
执行爬虫。