《收获,不止Oracle》读书笔记
本笔记真的是笔记,是在看书过程中记录到笔记本上的一些点,比较零散。
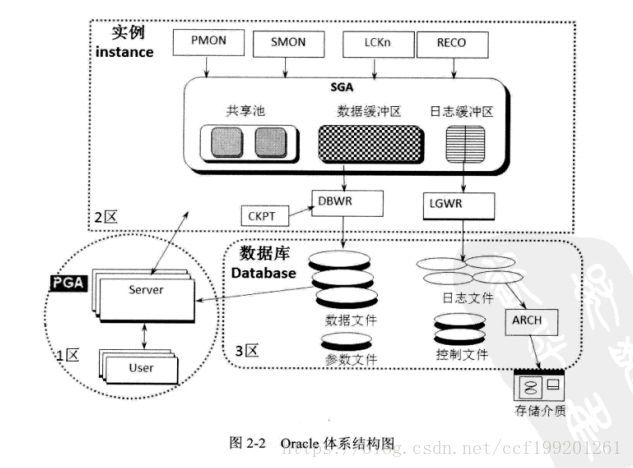
1、Oracle体系结构图:
图片来自:https://www.cnblogs.com/cccddd/p/7338543.html
① Oracle由实例和数据库组成,上半部的直角方框为实例instance,下半部的圆角方框为数据库databases。
② 实例是由一个开辟的内存区SGA(System Global Area)和一系列后台进程组成的,其中SGA最主要被划分为共享池(shared pool)、数据缓冲区(db cache)和日志缓冲区(log buffer)三类。后台进程包括PMON、SMON、LCKn、RECO、CKPT、DBWR、LGWR、ARCH等系列进程。
③ 数据库是由数据文件、参数文件、日志文件、控制文件、归档文件等系列文件组成的,其中归档日志最终可能会被转移到新的存储介质中,用于备份恢复使用。
④ PGA(Program Global Area)区,这也是一块开辟出来的内存区,和SGA最明显的区别在于,PGA不是共享内存,是私有不共享的,S理解为共享的首字母。用户对数据库发起的无论查询还是更新的任何操作,都是在PGA先预处理,然后接下来才进入实例区域,由SGA和系列后台进程共同完成用户发去的请求。
PGA起到的具体作用,也就是前面说的预处理,是什么呢?主要有三点:第一,保存用户的连接信息,如会话属性、绑定变量等;第二,保存用户权限等重要信息,当用户进程与数据库建立会话时,系统会将这个用户的相关权限查询出来,然后保存在这个会话区内;第三,当发起的指令需要排序的时候,PGA正是这个排序区,如果在内存中可以放下这个排序的尺寸,就在内存PGA区内完成,如果放不下,超出的部分就在临时表空间中完成排序,也就是在磁盘中完成。
⑤ 用户的请求发起经历的顺序一般如下:1区 -> 2区 -> 3区;或者1区 -> 2区。
后台进程介绍:
PMON:进程监视器,当其他进程出错时进行处理
SMON:系统监视器,重点工作在于instance recovery 除此之外,还有清理临时表空间、回滚段表空间和合并空闲空间
LCKn:仅适用于RAC数据库,最多可有10个进程,用于实力间的封锁
RECO:用于分布式数据库的恢复
CKPT:用于触发DBWR从数据缓冲区写出数据到磁盘
DBWR:负责将数据缓冲区中的数据写出到磁盘文件中
LGWR:负责将日志缓冲区的日志数据写出到REDO文件中
ARCH:负责磁盘日志文件的归档,转存到其他存储介质中
2、Oracle逻辑结构:
表空间(tablespace):系统表空间、回滚段表空间、临时表空间、用户表空间。
段(segment)、区(extent)、
块(block):数据块的组成
① 数据块头:包含标准内容和可变内容
② 表目录区:数据所在的表信息
③ 行目录区:存放插入的行的地址
④ 可用空间区:块中的空余空间
⑤ 行数据区:存储具体的行信息或索引信息
1)、在建表空间时需要预先规划好表空间的大小,如果段的扩展导致表空间不够而需要表空间去扩大,那么开销是很大的,但如果预先分配过多空间,也是一种浪费,因此我们需要根据实际应用去平衡。
2)、delete操作是无法释放空间的,即没办法回收block块,在delete之后只是block中无数据,可block依然存在,在后续的insert时将填充delete的空block,因此普通的堆表无法满足有序插入有序读出(不适用 order by)。
3、Oracle表分类
1)、普通堆表
不足:
表更新有日志开销
表delete操作不能释放空间
表记录太大检索较慢
索引回表读开销很大
有序插入难有序读出
2)、全局临时表
分类:基于session、基于事务
优点:高效删除记录,退出session或commit结束事务,记录就删除;不同会话独立,避免锁竞争,利于并行
3)、分区表
分类:range分区(范围分区),list分区(列表分区),hash分区(散列分区),组合分区
分区表的特性:
① 高效的分区消除
② 强大的分区操作:分区truncate消除数据比较快速,并不同于delete,可释放空间;分区数据转移;分区切割想分就分,可将某个分区切割成多个分区,以达到增加分区数量的目的;分区合并想合就合;分区的增删非常简单
③ 分区索引类型:全局索引;局部索引
④ 分区表相关陷阱:对分区进行truncate操作之后,全局索引失效,局部索引正常,为了避免全局索引失效,在对分区进行删除、转移、切割、合并、增加等操作时,可在命令后加“update global indexes”关键字;有索引效率反而更低;无法应用分区条件
4)、索引组织表:在create table的语句之后增加 organization index 关键字
优点:不需要回表查询主键之外的列,性能更高
缺点:更新操作代价较高
4、索引
1)、创建索引有哪些操作
① 建索引先排序:将需要建索引的列和rowid取出排好序放在内存中
② 列值入块成索引:依次将内存中的顺序存放的列的值和对应的rowid存进Oracle空闲的Block块中,形成索引块
③ 填满一块接一块:当块1被填满时,会接着填到其他空闲块,如块2,此时会有另外一件重要的事情发生,会产生一个 茎块B1用来管理块1和块2
④ 同级两块则会产生上层块来管理下级块,直到root根节点
2)、索引结构的三大特点
① 索引高度较低
② 索引存储列值及能定位到行数据在数据表中的位置的rowid
③ 索引本身有序
3)、应用索引三大特性进行查询优化
① 索引高度较低的妙用:由于索引结构导致高度较低,因此在表数据量相差甚远的情况下,运用索引,查询速度会相差无 几,都会比较快,此种情况仅限于查询结果比较少的情况,如果需要返回表中的绝大部分数据,那用索引反而会更慢,不 如全表扫描,原因是索引也是快,如果一个索引3层,100万数据,那么就需要300万次IO,因此性能会下降
② 分区索引的设计误区:如果在分区表中查询时不能使用到分区条件,那么建立分区索引是根据分区个数创建的,如果查 询没有使用分区条件,就会去所有索引块中查找,那么此时的索引高度将变得极高,IO次数变多,性能下降
③ count(*) 优化:索引不能存储空值,索引列必须设置成不能为空,可以用 where object is not null 解决;当表中字段很 少,比如只有一个字段,那此时使用索引会比全表扫描更慢,因为索引中存储了字段以外的rowid数据,总体来说比原表 数据更大了
④ sum/avg 优化:允许为空的列仍然不能使用索引
⑤ max/min 优化:能使用允许为空的列的索引;执行计划只有两次逻辑读,这是因为索引的结构导致的结果,max只要去 最右边的最后一列查询,min则去最左边第一列查询即可,因为索引是有序的;select min(object_id),max(object_id) from t 不能使用索引,因为object_id列属性允许为空,select min(object_id),max(object_id) from t where object_id is not null 可以使用索引,但是 INDEX FAST FULL SCAN 类型索引,select max,min from(select max(object_id) max from t) a, (select min(object_id) min from t) b 能使用索引,并是 INDEX FULL SCAN(MIN/MAX)类型索引,逻辑读比第二种少了非 常多
⑥ 索引回表与优化:应尽量不要使用 select * from t,这样会导致全表扫描操作;善用联合索引,联合索引字段不宜超过3 个;(聚合因子:表和索引两者的列的排序相似度),如果表的插入顺序和索引列的顺序基本一致,那么从索引回表查找 数据块将会更容易,这就是聚合因子底对查询优化的帮助
⑦ order by 排序优化:在 order by 列上加索引,能有效提升查询效率
⑧ distinct 优化:索引能消除 distinct 触发的排序,提升效率
⑨ 索引全扫描和快速全扫描:INDEX FULL SCAN 和 INDEX FAST FULL SCAN 在如count(*) 和 sum 这种不需要排序的 查询时使用快速全扫描,而在涉及排序语句时,就要权衡利弊了,也许使用全速全扫描,也许使用非快速扫描,由oracle 优化器计算出成本值决定
⑩ union 合并优化:在使用union时索引是不能消除排序的,因为这是两个结果集的筛选
4)、不得不说的主外键设计
① 外键上的索引与性能:外键上建索引能对连接查询有很大的性能提升
② 外键索引与锁的避免:在外键上建立索引不但能提升查询性能,还能有效避免锁竞争
③ oracle支持级联删除,需慎用
5)、联合索引
① 在等值查询情况下,组合索引的列无论哪一列在前,性能都一样
② 组合索引的列,当一列是范围查询,一列是等值查询的情况下,等值查询列在前,范围查询列在后,这样的索引才能提 高性能
分析:因为索引有序,当两个查询列都为等值时,遍历索引块的次数一样,当一列为范围时,如果该列在前那么遍历将不 会那么容易停下,相反,等值列在前时,将很快停止遍历,也即是遍历列更少,当然会更快
③ 设计需考虑单列的查询:如果单列的查询列和联合索引的前置列一样,那单列可以不建索引,直接利用联合索引来进行 检索数据
6)、数据更新会受到索引影响,因此在需要插入数据时,应该先使索引失效,在数据插入完成之后,重新创建索引
7)、创建索引的过程会引发大量排序和锁竞争
8)、可以通过监控索引来蚌段索引是否被使用过,从而删除根本用不到的索 加监控命令:alter index 索引名 monitoring usage;撤销命令:alter index 索引名 nomonitoring usage
9)、位图索引
① 位图索引在进行count(*)统计操作时性能比B树索引快近100倍,并且位图索引可以保存空值
② 位图索引的适用场景需要满足以下两个条件:位图索引列大量重复
10)、函数索引:create index idx_upper_obj_name on t(upper(object_name))
5、表的连接:嵌套循环、哈希连接、排序合并
1)、在嵌套循环连接中,驱动表返回多少条记录,被驱动表就返回多少记录
2)、在hash连接中,驱动表和被驱动表都只会访问0次或1次
3)、排序合并连接和hash连接一样,两张表都只会访问0次或1次,合并连接根本就没有驱动和被驱动的概念
4)、嵌套循环连接要特别注意驱动表的排序,小的结果集先访问,大的结果集后访问,才能保证被驱动表的访问次数降到最低,从而提升性能
5)、嵌套循环连接和hash连接有驱动顺序,驱动表的顺序不同将影响表连接的性能,而排序合并连接没有驱动的概念,无论那张表在前都无妨
6)、嵌套循环连接和hash连接不需要排序,而排序合并则需要排序,在取字段时,尽可能少的取字段,排序需要消耗内存
7)、hash连接不支持不等值连接 "<>"、">" 和 "<" 的连接方式,也不支持like的连接方式;排序合并连接不支持"<>"的连接条件,也不支持like的连接,但支持 ">" 之类的连接条件;嵌套循环无限制
8)、最适合嵌套循环连接的场景
① 两表关联返回的记录不多,几遍两张表的记录奇大无比,也是非常迅速的
② 遇到一些不等值查询导致哈希和排序合并连接被限制使用时,不得不使用嵌套循环连接
*****连接查询优化*****:驱动表的限制条件所在列加索引;被驱动表的连接条件所在列加索引
9)、哈希连接与索引
① 索引的连接条件起不到快速检索的作用,但是限制条件列如果有合适的索引,可以快速检索少量记录,还是可以提升性 能的
② 哈希连接需要在PGA中的HASH_AREA_SIZE中完成,因此增大HASH_AREA_SIZE也是优化哈希连接的一种有效途 径,一般在内存自动管理的情况下只要加大PGA区大小即可
10)、排序合并与索引:排序合并连接上的连接条件虽然没有检索的作用,却有清除排序的作用