中文分词
分词,是自然语言处理的第一步!
中文分词技术的类型并没有比较严谨的学术定义,仅从方式方法上,大致归纳为下表的四类:
| 中文分词技术 | |||||
| 规则分词 | 正向最大匹配法 | 逆向最大匹配法 | 双向最大匹配法 | ||
| 统计分词 | 语言模型 | 深度学习 | |||
| 混合分词 | SVM模型 | 隐马尔科夫模型 | 条件随机场 | ||
| 理解分词 | 知识图谱 | ||||
规则分词
自定义词典,记作dict,记录dict中最长一词的字符数个数,记作m。如dict中最长一词是“乌兹别克斯坦”,即m=6。
预切分的文字,记作text,在text中取m个字符与dict中的词进行逐一匹配:
如果匹配成功,则切分出来,再切分余下未切分的文字,直到全部切完;
如果没有匹配到,则m=m-1再与dict的词进行匹配,如果还是没有匹配到,则再m=m-1,直到有字/词被切分出来,或者m=0。
正向最大匹配(Maximum Match Method,MM法)
从左至右,依次取m个字符。
假设有dict,文件名为data.uft8,内容如下:
- 南京市
- 南京市长
- 长江大桥
- 人民解放军
- 大桥
则m=5
以text='南京市长江大桥' 为例
| m | 搜索 | dict匹配 |
| m=5 | 南京市长江 | X |
| m=4 | 南京市长 | O |
| m=5 因余字符数<5 取余字符数,3 m=3 |
江大桥 | X |
| m=2 |
江大 | X |
| m=1 | 江 | O |
| m=5 因余字符数<5 取余字符数,2 m=2 |
大桥 | O |
| m=5 因余字符数<5 取余字符数,0 m=0 |
将每个切分出来的字/词按照由上至下的顺序摘选出来,即“南京市长/江/大桥”。
逆向最大匹配(Reverse Maximum Match Method,RMM法)
从右至左,依次取m个字符。
假设dict和text同上,代码如下:
# coding=utf-8
class RMM(object):
def __init__(self, dic_path):
self.dictionary = set()
self.maximum = 0
with open(dic_path, 'r', encoding = 'utf-8') as f:
for line in f:
line = line.strip()
if not line:
continue
self.dictionary.add(line)
if len(line) > self.maximum:
self.maximum = len(line)
def cut(self, text):
result = []
index = len(text)
while index > 0:
for size in range(self.maximum, 0, -1):
piece = text[(index - size):index]
if piece in self.dictionary:
result.append(piece)
index -= size
break
if piece is None:
index -= 1
return result[::1]
def main():
text = '南京市长江大桥'
tokenizer = RMM('./data.utf8')
print(tokenizer.cut(text))
main()双向最大匹配(Bi-direction Matching Method)
比较MM法和RMM法的结果,取切分最少的作为结果。
如MM法的“南京市长/江/大桥”和RMM法的“南京市/长江大桥”,则取RMM法。
根据SunM.S.和Benjamin K.T.(1995)的研究表明:
| 中文分词 | |
| MM和RMM的结果是一致的 | 90% |
| MM或RMM的结果不一致,但必有一种是正确的 | 9% |
| MM和RMM的结果是一致的,但是都是错误的 MM或RMM的结果不一致,但二者都不对 |
<1% |
统计分词
语言模型
长度为m的字符串,确定其概率分布 ![]() ,每个
,每个 ![]() 到
到 ![]() 表示文本中的各个词语。
表示文本中的各个词语。
![]()
以“You are my sunshine”为例:
![]()
每增加一个字/词,计算量都翻一倍。
优化方案:n元模型(n-gram model),其中
- n=1 为 一元模型(unigram model)
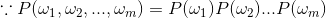
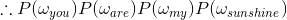
- n=2 为 二元模型(bigram model)
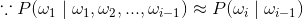
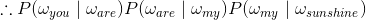
- n=3 为 三元模型(trigram model)
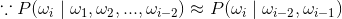
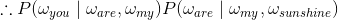
当 n 越大,模型包含的词序信息越丰富,同时计算量也随之增大。
![]()
长度越长的文本序列出现的概率会越少,为避免分子/分母为零的情况出现,通常预先使用平滑算法做特征工程。如:
- 高斯(Gauss)平滑
- 拉普拉斯(Laplace)平滑
深度学习(deep learning)
用CNN、LSTM等深度学习网络自动发现一些模式和特征,然后结合CRF、softmax等分类算法进行分词预测。
- 优势:解放了维护词典的人力成本。
- 劣势:其效果依赖训练语料的质量,计算量对于规则分词要大很多。
混合分词
混合分词 = 规则分词 + 统计分词
SVM模型
1. 预处理模块
将文字分割成词串(以两字词串为例),如:
'我爱北京天安门,天安门上太阳升' = '我爱' , '爱北' , '北京' , '京天' , '天安' , '安门','天安' , '安门' , '门上' , '上太' , '太阳' , '阳升'
2. 词频统计模块
统计每个字和词语相应出现的频率:
- 我 1
- 爱 1
- 北 1
- 京 1
- 天 2
- 安 2
- 门 2
- 上 1
- 太 1
- 阳 1
- 升 1
- 我爱 1
- 爱北 1
- 北京 1
- 京天 1
- 天安 2
- 安门 2
- 门上 1
- 上太 1
- 太阳 1
- 阳升 1
3. SVM处理模块
主要解决歧义型字段问题,歧义型字段包括两类:
- 交叉型歧义:可以切在A处,也可以切在B处。如“乒乓球 / 拍卖完了”、“乒乓球拍 / 卖完了”
- 组合型歧义:可以切开,也可以不切开。如“他具有非凡的 / 才能,只有他 / 才 / 能 / 做到”
将上述两类歧义问题转化为“在字段XYZ中,XY可以构成词语,YZ也可以构成词语,如何正确地分割”问题。
对于歧义字段XYZ:a1...axb1...byc1...cz(x>0,y>0,z>0)存在两种切分方案:
![]() 正向切分
正向切分
![]() 逆向切分
逆向切分
其中,w11,w12,w13,w21,w22均为词,pt1和pt2分别对应byc1和axb1之间的位置。
将每个歧义字段表示成一个二维向量
- Ipt1表示正向切分断点处byc1两个字的互信息值。
- Ipt2表示逆向切分断点处axb1两个字的互信息值。
互信息(Mutual Information):体现信息A与信息B之间的紧密程度,AB必须是邻近的汉字字符串。
![]() , 其中
, 其中 ![]() ,
, ![]() ,
, ![]() , n = 词频总和。
, n = 词频总和。
- 如果
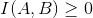 ,即
,即 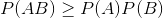 ,表示AB间是正相关,当I(A,B)大于给定的阈值,则可以认为AB是一个词。
,表示AB间是正相关,当I(A,B)大于给定的阈值,则可以认为AB是一个词。 - 如果
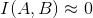 ,即
,即 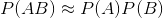 ,表示AB间是不相关的。
,表示AB间是不相关的。 - 如果
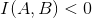 ,即
,即 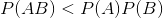 , 表示AB间是互斥的,则可以认为AB基本不会是一个词。
, 表示AB间是互斥的,则可以认为AB基本不会是一个词。
* SVM-KNN分类器:等价于每个类只选择一个代表点的1NN分类器。
最终取字,从 [i] 到 [i+1] ,存入词典:
![]()
4. 词典生成模块
将切分后的词语存储到自定义词典中,通过词典的进行分词。
隐马尔科夫模型
隐马尔科夫模型(HMM,Hidden Markov Model) :
- 一阶马尔科夫 —— 现状态仅依赖于前一个状态,即“齐次马尔科夫假设”,是HMM中较常使用的假设
- N阶马尔科夫 —— 现状态依赖于前N个状态
每个字在构造成词语时都在该词语中占据着一个确定的位置,即“词位”。
| 缩写 | 全称 | 含义 | 案例 |
| B | Beginning | 词首 | 1. 看S 2. 幻B 视E 3. 钢B 铁M 侠E 4. 美B 国M 队M 长E 5. 鹰B 眼E |
| M | Middle | 词中 | |
| E | Ending | 词尾 | |
| S | Single | 单独成词 |
根据贝叶斯公式,得 ![]()
- o 表示“词位”,即 B,M,E,S 【HMM 的 隐含状态】
 表示“字符串”,即 钢铁侠,美国队长 等【HMM 的 可观察状态】
表示“字符串”,即 钢铁侠,美国队长 等【HMM 的 可观察状态】
HMM有三种概率:
- 初始状态概率(initial state probabilities) :初始时每一项隐含状态的概率
- 发射概率(emission probabilities) :P( λ | o )
- 转移概率(transition probabilities) :P( o )
![]() 为常数项,暂且忽略。
为常数项,暂且忽略。
![]() 只对贝叶斯公式的分子
只对贝叶斯公式的分子 ![]() 作马尔科夫假设,其中
作马尔科夫假设,其中 ![]() 称为“发射概率 / 似然值”,
称为“发射概率 / 似然值”, ![]() 称为“转移概率 / 先验概率”。
称为“转移概率 / 先验概率”。
![]()
![]() 这里作“齐次马尔科夫假设”(每个输出只与上一输出有关),得到
这里作“齐次马尔科夫假设”(每个输出只与上一输出有关),得到
![]()
![]()
![]() 等价于
等价于 ![]()
用 Veterbi(维特比) 算法求解发射概率的最大概率与转移概率的积,即 ![]()
如果最优路径经过了点 ![]() ,那么从初始点到点
,那么从初始点到点 ![]() 的路径必然是最优路径,因为使用的是“齐次马尔科夫假设(即一阶马尔科夫模型)” —— 点
的路径必然是最优路径,因为使用的是“齐次马尔科夫假设(即一阶马尔科夫模型)” —— 点 ![]() 只影响前后两点:
只影响前后两点: ![]() 和
和 ![]()
代码如下(需先下载 trainCorpus.txt_utf8【已经分好词的训练集词典】 和 hmm_model.pkl【训练集词典中计算好的概率模型】):
- 链接: https://pan.baidu.com/s/1g7DzRKElpo8w5fJXHh8Kmg
- 提取码: cymu
# coding=utf-8
import os
import pickle
class HMM(object):
def __init__(self):
self.load_para = False #是否需要重新加标注好的数据集
self.model_file = './hmm_model.pkl' #标注好的数据集地址
self.state_list = ['B', 'M', 'E', 'S'] #设定的四个状态值
def try_load_model(self, trained):
if trained:
with open(self.model_file, 'rb') as f:
self.A_dic = pickle.load(f)
self.B_dic = pickle.load(f)
self.Pi_dic = pickle.load(f)
self.load_para = True
else:
self.A_dic = {} #转移概率
self.B_dic = {} #发射概率
self.Pi_dic = {} #初始概率
self.load_para = False
def train(self, path):
self.try_load_model(False)
Count_dic = {}
def init_parameters():
for state in self.state_list:
self.A_dic[state] = {s: 0.0 for s in self.state_list}
self.Pi_dic[state] = 0.0
self.B_dic[state] = {}
Count_dic[state] = 0
def makeLabel(text):
out_text = []
if len(text) == 1:
out_text.append('S')
else:
out_text += ['B'] + ['M'] * (len(text) - 2) + ['E']
return out_text
init_parameters()
line_num = -1
words = set()
with open(path, encoding='utf8') as f:
for line in f:
line_num += 1
line = line.strip()
if not line:
continue
word_list = [i for i in line if i != ' ']
words |= set(word_list)
linelist = line.split()
line_state = []
for w in linelist:
line_state.extend(makeLabel(w))
assert len(word_list) == len(line_state)
for k, v in enumerate(line_state):
Count_dic[v] += 1
if k == 0:
self.Pi_dic[v] += 1 #每句话第一个字的状态,用于计算初始概率
else:
self.A_dic[line_state[k - 1]][v] += 1
self.B_dic[line_state[k]][word_list[k]] = \
self.B_dic[line_state[k]].get(word_list[k], 0) + 1.0 #计算发射概率
self.Pi_dic = {k: v * 1.0 / line_num for k, v in self.Pi_dic.items()}
self.A_dic = {k: {k1: v1 / Count_dic[k] for k1, v1 in v.items()}
for k, v in self.A_dic.items()}
self.B_dic = {k: {k1: (v1 + 1) / Count_dic[k] for k1, v1 in v.items()}
for k, v in self.B_dic.items()}
with open(self.model_file, 'wb') as f:
pickle.dump(self.A_dic, f)
pickle.dump(self.B_dic, f)
pickle.dump(self.Pi_dic, f)
return self
def viterbi(self, text, states, start_p, trans_p, emit_p):
V = [{}]
path = {}
for y in states:
V[0][y] = start_p[y] * emit_p[y].get(text[0], 0)
path[y] = [y]
for t in range(1, len(text)):
V.append({})
newpath = {}
neverSeen = text[t] not in emit_p['S'].keys() and \
text[t] not in emit_p['M'].keys() and \
text[t] not in emit_p['E'].keys() and \
text[t] not in emit_p['B'].keys()
for y in states:
emitP = emit_p[y].get(text[t], 0) if not neverSeen else 1.0
(prob, state) = max(
[(V[t - 1][y0] * trans_p[y0].get(y, 0) * emitP, y0)
for y0 in states if V[t - 1][y0] > 0])
V[t][y] = prob
newpath[y] = path[state] + [y]
path = newpath
if emit_p['M'].get(text[-1], 0) > emit_p['S'].get(text[-1], 0):
(prob, state) = max([(V[len(text) - 1][y], y) for y in ('E', 'M')])
else:
(prob, state) = max([(V[len(text) - 1][y], y) for y in states])
return (prob, path[state])
def cut(self, text):
if not self.load_para:
self.try_load_model(os.path.exists(self.model_file))
prob, pos_list = self.viterbi(text, self.state_list, self.Pi_dic, self.A_dic, self.B_dic)
begin, next = 0, 0
for i, char in enumerate(text):
pos = pos_list[i]
if pos == 'B':
begin = i
elif pos == 'E':
yield text[begin: i + 1]
next = i + 1
elif pos == 'S':
yield char
next = i + 1
if next < len(text):
yield text[next:]
hmm = HMM()
hmm.train('./trainCorpus.txt_utf8')
text = '人最宝贵的是生命,生命对于每个人只有一次……当回忆往事的时候,不会因为虚度年华而悔恨,也不会因为碌碌无为而羞愧……'
res = hmm.cut(text)
print("测试:",text)
print("效果:",str(list(res)))条件随机场
条件随机场(CRF,Conditional Random Fields)
我爱北京天安门,SSBEBME,我/S 爱/S 北/B 京/E 天/B 安/M 门/E
- HMM:P = P(s到s)*P('我'到s)* P(s到b)*P('爱'到s)* ...*P()
- MEMM:P = P(s到s|'我'到s)*P('我'到s)* P(s到b|'爱'到s)*P('爱'到s)*...*P()
- CRF:P= F(s到s,'我'到s)....F is a function.
| HMM | P( λn 到 On ) * P( o ),状态概率 * 转移概率 | 计算状态分布 |
| MEMM | P( λ | o ) * P( o ),发射概率 * 转移概率 | 计算局部联合概率 |
| CRF | F( λn 到 On, On 到 On ),状态概率和转移概率的函数 | 全局归一化后计算联合概率 |
神经网络分词(deep learning:CNN、LSTM等)
理解分词
模拟人对句子的理解,从语义的角度,通过分词系统、句法语义和总控三部分来识别词语并处理歧义现象。
- ……中国 / 人……
- ……中 / 国人……
知识图谱
(中文)知识图谱(KG,Knowledge Graph):由于汉语言知识的笼统、复杂性,难以将各种字/词信息组成其可直接读取的形式,因此目前基于理解的分词技术还处于学术探索阶段,真正落地的项目/产品极少,业界多在炒概念。See more:
http://www.openkg.cn/
基于Python语言的中文分词工具(jieba v.s pyltp)对比
| 功能 | - | jieba | pyltp |
| 分句 | 分句 | O | |
| 分词 | 全模式 | O | |
| 分词 | 精准模式 | O | O |
| 分词 | 搜索引擎模式 | O | |
| 新词发现 | 新词发现 | O | |
| 自定义词典 | 词语 | O | O |
| 自定义词典 | 词频 | O | |
| 自定义词典 | 词性 | O | O |
| 关键词抽取 | TF-IDF算法的关键词抽取 | O | |
| 关键词抽取 | TextRank算法的关键词抽取 | O | |
| 词性标注 | 词性标注 | O | |
| 命名实体识别 | 命名实体识别 | O | |
| 依存句法分析 | 依存句法分析 | O | |
| 语义角色标注 | 语义角色标注 | O | |
| 其它功能 | 其它功能 | 并行分词 | 个性化分词 |
| 返回词语在原文的起止位置 | |||
| 自定义分词器 | |||
| 调整词典 | |||
| 调整词频和显示 |