redis3.0深入详解(1)
4月1日,redis3.0-stable正式发布。引入了久违的cluster模式,同时进行了多处优化。本文,从源码级别对3.0和2.8.19进行对比,详细解释优化细节。由于能力及时间有限,只会对我已经读过的源码部分进行对比,同时不涉及cluster相关内容。
1. Embedded String
减少由于cache miss带来的内存读取,进一步提升缓存命中率,在某些场景下,大幅提升速度。
1)2.8
redis中,所有对象通过robj表示,包括key和value:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
由type指定类型,泛型指针ptr指向具体的对象。对于字符串,ptr直接指向该字符串对应的内存。由于通过间接指针关联,一般情况下,robj和字符串不在连续内存中,读取字符串时,需要两次内存操作。

2)3.0
redis3.0中,如果字符串长度小于39,则会使用ebeded string,将robj和字符串分配在一块连续内存中。由于局部性原理,在读取时,robj和字符串内容都会读到cache中,从而只要一次内存读取即可。
//
// 分配一块内存,容纳robj, sds header, 字符串和'\0'
//
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr)+len+1);
struct sdshdr *sh = (void*)(o+1);
o->type = REDIS_STRING;
o->encoding = REDIS_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
o->lru = LRU_CLOCK();
sh->len = len;
sh->free = 0;
if (ptr) {
//
// 拷贝字符串内容
//
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
长度限制在39的原因是,redis使用jemalloc,会以64字节为一个内存块进行分配。robj(16字节),sds的头部(16字节)和字符串结尾的’\0'会占用25字节。
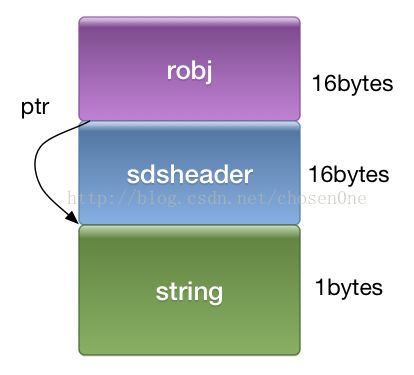
redis中所有的key都是字符串类型,所以这个优化会大幅提升redis的cache命中率。
在实际使用时,可以尽量将key的大小限制在39字节内,充分利用cache,提升性能。
2. AOF Rewrite
在完成rewrite的最后一个步骤中,redis主进程需要将rewrite期间的增量aof diff追加到aof文件中,这是一个比较重的磁盘io操作,会阻塞事件循环,增加延迟,造成服务抖动。
1)2.8
rewrite的流程:
- 主进程fork子进程,由子进程进行rewrite,主进程继续服务请求。同时主进程会初始化一个aof rewrite buffer,用于收集rewrite期间的增量aof diff。
- 子进程完成rewrite后,主进程会wait子进程并对其进行收割。此时,启动rewrite时的数据集已经生成一份aof文件,接下来主进程需要把aof rewrite buffer追加到该aof文件的最后。
由于rewrite过程比较漫长,累积的aof rewrite buffer会比较大,主进程进行追加写操作,会产生磁盘操作,阻塞事件循环,此时的redis是不能服务的,会影响业务。
2)3.0
父子进程间建立pipe进行通信。在子进程进行rewrite期间,父进程会不断的通过pipe向子进程发送aof diff,子进程会不停的收集到aof rewrite buffer中。当子进程完成rewrite后。会通知父进程停止发送aof diff。然后子进程将收集到的aof rewrite buffer追加到重写后的aof文件的最后。
父进程完成对子进程收割后,会把剩余的rewrite buffer追加到aof文件(这个rewrite buffer相对要小一些)。
改进点:
- 大部分的磁盘操作由子进程完成,父进程只需进行小数据量的磁盘操作
- aof rewrite buffer的输出会被打散到每个命令的处理过程中,降低延迟,不会造成大的抖动
3. LRU近似算法改进
如果配置了maxmemory,在每个命令处理过程中,如果占用内存超过maxmemory,redis会根据LRU算法踢出一些key,以释放内存。redis采用的LRU算法是近似的,并没有维护一个LRU链,以精确的表示先后顺序。
在robj中,由属性lru表示该对象最后被访问的时间。同时,全局变量redisServer.lruclock表示当前的lru时钟,在serverCron(每毫秒执行一次)中会不停更新lruclock。当对象被创建或者被访问时,用lruclock更新该对象的lru属性。
#define REDIS_LRU_BITS 24
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;2)2.8
lruclock的计算方法:
server.lruclock = (server.unixtime/REDIS_LRU_CLOCK_RESOLUTION) &
REDIS_LRU_CLOCK_MAX;
在freeMemoryIfNeed函数中会进行lru踢出的逻辑。
for (k = 0; k < server.maxmemory_samples; k++) {
sds thiskey;
long thisval;
robj *o;
//
// 随机选择一个kv对
//
de = dictGetRandomKey(dict);
thiskey = dictGetKey(de);
/* When policy is volatile-lru we need an additional lookup
* to locate the real key, as dict is set to db->expires. */
if (server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_LRU)
de = dictFind(db->dict, thiskey);
o = dictGetVal(de);
//
// 获取其lru值
//
thisval = estimateObjectIdleTime(o);
//
// 选择最久没有访问的key
//
/* Higher idle time is better candidate for deletion */
if (bestkey == NULL || thisval > bestval) {
bestkey = thiskey;
bestval = thisval;
}
}
3)3.0
lruclock计算方法:
(mstime()/REDIS_LRU_CLOCK_RESOLUTION) & REDIS_LRU_CLOCK_MAX;
为了提升LRU近似算法的准确性,redisDb中增加一个属性eviction_pool,表示一个要踢出的key的候选池。
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;
#define REDIS_EVICTION_POOL_SIZE 16
struct evictionPoolEntry {
unsigned long long idle; /* Object idle time. */
sds key; /* Key name. */
};
struct evictionPoolEntry *pool = db->eviction_pool;
while(bestkey == NULL) {
//
// 填充eviction_pool,在第一次时随机选择16个key填充,
// 之后每次调用时,只需要填充一个key
//
evictionPoolPopulate(dict, db->dict, db->eviction_pool);
/* Go backward from best to worst element to evict. */
for (k = REDIS_EVICTION_POOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
de = dictFind(dict,pool[k].key);
/* Remove the entry from the pool. */
sdsfree(pool[k].key);
/* Shift all elements on its right to left. */
memmove(pool+k,pool+k+1,
sizeof(pool[0])*(REDIS_EVICTION_POOL_SIZE-k-1));
/* Clear the element on the right which is empty
* since we shifted one position to the left. */
pool[REDIS_EVICTION_POOL_SIZE-1].key = NULL;
pool[REDIS_EVICTION_POOL_SIZE-1].idle = 0;
/* If the key exists, is our pick. Otherwise it is
* a ghost and we need to try the next element. */
if (de) {
bestkey = dictGetKey(de);
break;
} else {
/* Ghost... */
continue;
}
}
}
改进点:
- 精度改为毫秒,更精确
- 避免每次lru踢出时,需要多次迭代选择踢出对象
4. INCR命令
1)2.8
redis为了节省内存,对于可以整数化的字符串直接以long型存储(只占8个字节)。并且redis有一个整数常量池,对于在[0, 10000]内的整数,直接引用常量池中的对象。
oldvalue = value;
if ((incr < 0 && oldvalue < 0 && incr < (LLONG_MIN-oldvalue)) ||
(incr > 0 && oldvalue > 0 && incr > (LLONG_MAX-oldvalue))) {
addReplyError(c,"increment or decrement would overflow");
return;
}
// value是原来的值,加上增量
value += incr;
// 根据value,创建一个新的string类型的robj,
// 如果命中常量池,并不会创建新的对象,只有大于10000的才会创建。
new = createStringObjectFromLongLong(value);
// 需要一次hash查找,添加新对象或覆盖原有对象
if (o)
dbOverwrite(c->db,c->argv[1],new);
else
dbAdd(c->db,c->argv[1],new);2)3.0
3.0对大于10000,不命中常量池的场景做了优化,可以避免hash查找,以及对象创建。
// 计算新的值
value += incr;
if (o && o->refcount == 1 && o->encoding == REDIS_ENCODING_INT &&
(value < 0 || value >= REDIS_SHARED_INTEGERS) &&
value >= LONG_MIN && value <= LONG_MAX)
{
// 如果该对象的encoding是REDIS_ENCODING_INT,并且不在常量池的范围内
// 同时引用计数小于1,则直接更改对象的值
new = o;
o->ptr = (void*)((long)value);
} else {
// 命中常量池,或者引用计数不唯一,按照以前的方式
new = createStringObjectFromLongLong(value);
if (o) {
dbOverwrite(c->db,c->argv[1],new);
} else {
dbAdd(c->db,c->argv[1],new);
}
}
之所以只有引用计数为1时才进行优化,是避免与其他逻辑共享对象,造成不一致(比如key,重新编码后,hash查找会失败)。