Spring Data Jpa入门详解
讲解内容——
(一)Spring Data Jpa方法详解
- Repositoy
- CrudRepository
- PagingAndSortingRepository
- QueryByExampleExecutor
- JpaRepository
(二)自定义方法详解
- 定义查询方法
- 定义注解式查询方法
- 方法名还是注解?
(三)表相关注解
(四)级联注解
首先创建user表(建议自己创建表,而不是使用我定义的表,好随时变动)
CREATE TABLE `user` (
`id` int(11) NOT NULL ,
`username` varchar(16) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
`nickname` varchar(12) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL ,
`create_time` datetime NULL DEFAULT NULL ,
PRIMARY KEY (`id`)
)
ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci
ROW_FORMAT=DYNAMIC
;
创建User对象
package com.dfyang.jpastudy.entity;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import java.util.Date;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
private String username;
private String nickname;
private Date createTime;
// 省略 get、set
}
结构图
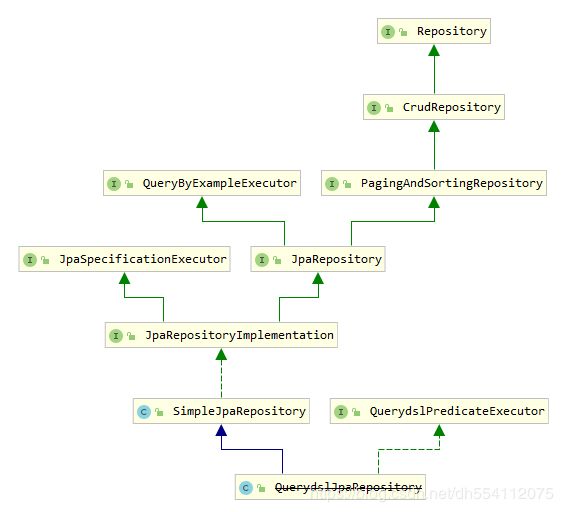
(一)Spring Data Jpa方法详解
(1.1)Repositoy
先来介绍一下Repository接口,Repository是Spring Data里面做数据库操作的最底层的父类。主要是起一个标识作用,好让Spring能够发现其子类或实现类。
@Indexed
public interface Repository<T, ID> {
}
(1.2)CrudRepository
Repository的实现类,提供基本的CRUD操作。

(1.3)PagingAndSortingRepository
继承CrudRepository接口,并新增了两个方法,排序查询所有,分页查询所有。

1)排序——Sort
Sort默认是按升序排列,如果我们需要查询所有user,并按id的升序排列。
Iterable<User> iterable = userDao.findAll(Sort.by("id"));
// 由于返回的是Iterable类型,如果需要返回List类型,需要进行强转。
List<User> userList = (List<User>) iterable;
如果我们需要按照id降序排列,又或者按id降序nickname升序。
Sort.Order:提供3个静态方法 (1)desc:降序 (2)asc:升序 (3)by:默认升序【也就是与asc一样】
Sort.Order orderByIdDesc = Sort.Order.desc("id"); // 按id降序
Sort.Order orderByNicknameAsc = Sort.Order.asc("nickname"); // 按nickname升序
Iterable<User> iterable = userDao.findAll(Sort.by(orderByIdDesc, orderByNicknameAsc));
也可以直接new出来
Sort.Order order = new Sort.Order(Sort.Direction.DESC, "id");
2)分页——Pageable
一般是通过Pageable的子类创建分页参数。
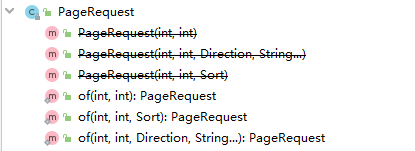
由于直接new创建Pageable不推荐,所以这里通过of进行创建。
// 1)最简单也最常用的就是直接使用页码(从0开始)及每页的条数进行创建。
Page<User> userPage = userDao.findAll(PageRequest.of(0, 10));
// 2)也可以同时进行排序
Page<User> userPage = userDao.findAll(PageRequest.of(0, 10, Sort.by("nickname")));
// 3)第3种与第二种效果一样,同样是分页同时排序,这里不介绍,使用第二种即可
Page对象分析

一般常用到的也就下面这些

最常见的分页作用——
![]()
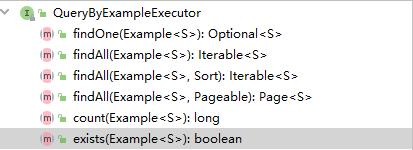
(1.4)QueryByExampleExecutor
该接口支持根据实体对象进行查询,对非null属性进行条件查询——因此适合做and连接的多条件查询。
修改UserDao,继承QueryByExampleExecutor
public interface UserDao extends PagingAndSortingRepository<User, Long>, QueryByExampleExecutor<User> {
}

对于用and连接的条件查询,使用这种方式更加方便,直接创建一个对象,设置属性即可。
User user = new User();
user.setId(45);
List<User> userList = (List<User>) userDao.findAll(Example.of(user));
// Example.of(new User())表示没有任何条件
从一个示例来介绍一下匹配规则
User user = new User();
user.setNickname("张三1");
user.setUsername("b1");
ExampleMatcher exampleMatcher = ExampleMatcher.matchingAll()
.withMatcher("nickname", ExampleMatcher.GenericPropertyMatchers.contains())
.withMatcher("username", ExampleMatcher.GenericPropertyMatchers.startsWith());
Example<User> example = Example.of(user, exampleMatcher);
List<User> userList = (List<User>) userDao.findAll(example);
return userList;
1)首先我们需要创建一个ExampleMatcher对象,ExampleMatcher提供了3种方法。
(1)matchingAll():满足所有匹配条件
(2)matchingAny():满足其中一个匹配条件
(3)matching():matchingAll()的简写
注意:这里为了方便理解,将 ExampleMatcher 视为匹配 规则 ,将 withMatcher() 等操作视为往规则中追加 条件。
2)我们来看看ExampleMatcher为我们提供了哪些条件。

3)最后我们来总结一下QueryByExampleExecutor的使用之处
当我们需要查询and连接的条件时,如
select * from user where nickname = ‘张三0’ and id = 22
当我们需要查询and连接的条件进行精准时,如
select * from user where nickname like concat(’%’, ‘张三’, ‘%’) and id = 22
常用的就是:开头、结尾、包含、忽略大小写、正则,只需记住这些即可。
(1.5)JpaRepository
Jpa继承自PagingAndSortingRepository和QueryByExampleExecutor,也就是拥有分页、排序、按实体对象查询等功能。
从下面可以看到,JpaRepository将返回Iterator改为了List,并增加了flush手动刷新到数据库方法。

(二)自定义方法详解
(2.1)定义查询方法
定义查询方法支持5种格式(前4个用法一样,个人习惯,记住一个即可,当然别人写的要认得来):
(1)find…by(2)read…by(3)query…by(4)get…by(5)count…by
可能会好奇为什么都有一个by,那不是后面必须要跟条件,那么如果不跟条件那不就只能使用Spring Data Jpa给我们定义好的方法吗?
只要By后面不跟属性就表示没有条件,下面这个方法就等价于findAll()
List<User> findAllBy();
1)以标准格式开头
查询所有:findBy、findAllBy、findUsersBy (个人习惯,记住一个即可,当然别人写的要认得来)
查询单个:findUserByoo
注意:如果使用findBy而返回类型为User,在spring启动时并不会报错,而是会在执行该方法时报错,因此需要注意。
2)and和or连接的条件
条件跟在By后面,使用驼峰式进行区分,并在参数中一一对应。
List<User> findByNickname(String nickname);
User findUserByUsernameAndNickname(String username, String nickname);
List<User> findByUsernameOrNickname(String username, String nickname);
// where username = xx and nickname = xx or id = xx
List<User> findUserByUsernameAndNicknameOrId(String username, String nickname, Integer id);
3)Distinct在By前
List<User> findDistinctByNickname(String nickname);
4)条件修饰符放在字段后面
List<User> findByNicknameStartingWith(String nickname);
List<User> findByUsernameStartingWithOrNicknameEndingWith(String username, String nickname);
字段修饰符列表 (放在属性后面) 后面的更新对部分字段进行了简写,这里并未列举出来。
图片来源:《Spring Data JPA从入门到精通》——张振华


5)排序修饰符放在属性后面,排序修饰符后面跟要排序的字段
List<User> findByNicknameOrderByCreateTime(String nickname);
List<User> findByNicknameOrderByCreateTimeDesc(String nickname);
6)对查询结果进行排序或分页可直接在参数添加Sort或Pageable对象
List<User> findByNicknameStartingWith(String nickname, Sort sort);
Page<User> findByNicknameStartingWith(String nickname, Pageable pageable);
注意:不能在参数上同时加上Pageable和Sort参数,Pageable本身自带排序功能。
List<User> list1 = userDao.findByNicknameStartingWith("张三", Sort.by("createTime"));
Page<User> list2 = userDao.findByNicknameStartingWith("张三", PageRequest.of(0, 10, Sort.by("createTime")));
7)使用Top和First限制查询结果(个人习惯,记住一个即可,当然别人写的要认得来)
后面可以跟数字,表示查询前几条数据,不加表示查询一条。
List<User> findTop5ByNicknameStartingWith(String nickname, Sort sort);
List<User> findFirst5ByNicknameStartingWith(String nickname, Sort sort);
8)查询部分字段而不是全部
定义一个接口,接口中写入我们想要属性的get方法。
package com.dfyang.jpastudy.essential;
public interface UserEssential {
String getUsername();
String getNickname();
}
在返回结果进行限制即可。
List<UserEssential> findAllBy();
在上面我们只从查询介绍了其语法,其他的由于语法一样这里就不介绍了,可自行尝试。

(2.2)定义注解式查询方法
这里有用到JPQL(Java持久性查询语言),一种面向对象的查询语言,用于对持久实体执行数据库操作。没有必要专门学习,从实践中学习即可。
1)创建一个新的接口UserAnnotationDao
User u取别名,select u就是查询所有,查询部分就是u.nickname,?1表示第一个参数,?2则是第二个参数
package com.dfyang.jpastudy.dao;
import com.dfyang.jpastudy.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import java.util.List;
public interface UserAnnotationDao extends JpaRepository<User, Integer> {
//select * from user where nickname = ?1
@Query("select u from User u where u.nickname = ?1")
List<User> findByNickname(String nickname);
@Query("select u from User u where u.nickname like %?1%")
List<User> findByNicknameContains(String nickname);
}
2)@Query同样支持使用原生sql,只需设置nativeQuery属性为true
使用原生sql,无法在参数上直接加Sort对象,可以加Pageable对象,并在Pageable种进行排序。
否则会抛异常:InvalidJpaQueryMethodException: Cannot use native queries with dynamic sorting
@Query(value = "select * from user where nickname like ?1%", nativeQuery = true)
Page<User> findByNicknameStartsWith(String nickname, Pageable pageable);
@Query(value = "select * from user where nickname like ?1% order by ?2 desc", nativeQuery = true)
List<User> findByNicknameStartsWithOrderByCreateTime(String nickname, String createTime);
3)可以使用@Param指定参数名称代替?1…(名称对应的话@Param可省略)
@Query("select u from User u where nickname = :nickname")
List<User> findByNickname(@Param("nickname") String nickname);
4)使用@Modifying执行更新/删除操作
注意这里加上了@Transaction注解,如果不加会报异常(也可以加在service层或controller)
javax.persistence.TransactionRequiredException: Executing an update/delete query
@Transactional
@Modifying
@Query("delete from User u where u.nickname = :nickname")
void removeByNickname(String nickname);
(2.3)方法名还是注解?
QueryLookupStrategy.Key有3个值:
1)CREATE:使用方法名,方法名不符合规则,启动报错。
2)USE_DECLARED_QUERY:使用声明式,启动时没有找到将抛异常。
3)CREATE_IF_NOY_FOUND:默认,先使用声明式,后使用方法名
@EnableJpaRepositories(queryLookupStrategy = QueryLookupStrategy.Key.CREATE_IF_NOT_FOUND)
public interface UserAnnotationDao extends JpaRepository<User, Integer> {
}
(三)表相关注解
@Entity——在类上加上该注解,JPA才认为该类是数据库表对应的实体类。
@Entity
public class User {
// ...省略
}
@Table——表名,如果表名与实体类名不一致,必须声明。
eg.表名:t_user,类名:User
@Entity
@Table(name = "user")
public class User {
// ...省略
}
@Id——主键,一个实体类中必须声明一个。
@GeneratedValue——主键生成策略,包含如下4种策略
- TABLE:通过表产生主键
- SEQUENCE:通过序列产生主键
- IDENTITY:数据库ID自增长
- AUTO:JPA自动选择合适的策略(默认)
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Basic——表面该属性映射到数据库表字段
fetch:加载模式 (1)LAZY懒加载(2)EAGER渴望
懒加载是在用到时才查询数据库。
@Basic(fetch = FetchType.EAGER, optional = false)
private String username;
@Transient // 这个注解表明不会序列化以及持久化
private String version;
.@Column——字段名

@Temporal——映射到表日期字段的类型
- DATE:只有日期
- TIME:只有时间
- TIMESTAMP:日期+时间
@Temporal(value = TemporalType.TIMESTAMP)
private Date createTime;
@Enumerated——枚举映射
EnumType.ORDINAL:对应数据库字段为整形
EnumType.STRING:对应数据库字段为字符串
![]()
创建枚举
public enum SexEnum {
MALE("男"),
FEMAIL("女")
;
private String value;
SexEnum(String value) {
this.value = value;
}
}
User对象添加属性
@Enumerated(EnumType.STRING)
private SexEnum sex;
(四)级联注解
创建部门表和雇员表
CREATE TABLE `department` (
`department_id` int(11) NOT NULL ,
`department_name` varchar(32) NOT NULL ,
PRIMARY KEY (`department_id`)
)
CREATE TABLE `employee` (
`employee_id` int(11) NOT NULL ,
`employee_name` varchar(32) NOT NULL ,
`department_id` int(11) NOT NULL ,
PRIMARY KEY (`employee_id`)
)
首先来看看关联查询需要什么,首先需要要关联的表,然后是要关联的表在该表的字段,以及要关联的表在关联表的字段。

而关联查询需要的信息就封装在@JoinColumn注解中

创建部门类
@Entity
public class Department {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "department_id")
private Integer departmentId;
private String departmentName;
// 省略get、set
}
创建雇员类
注意这里有两个注解:
1)@JsonIgnoreProperties:如果不加会报异常
InvalidDefinitionException: No serializer found for class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor and no properties discovered to create BeanSerializer (即使没有开启懒加载依旧会报错,网上查阅跟hibernate管理对象会加上hibernateLazyInitializer有关,暂时未过多了解)
2)@OneToOne:表示1对1映射
@Entity
@JsonIgnoreProperties(value={"hibernateLazyInitializer","handler","fieldHandler"})
public class Employee implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer employeeId;
private String employeeName;
@OneToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "department_id", referencedColumnName = "department_id")
private Department department = new Department();
// 省略get、set
}
——执行jpa方法自行测试。
下面具体看一下@OneToOne,其实也就cascade和fetch常用。

注意:上面的是单向级联,也就是雇员中包含部门。如何双向级联,也就是部门中同样包含雇员。
使用上面的mappedBy属性即可。

一般不推荐使用,即使使用也推荐懒加载,使用不当很可能导致内存溢出。因此彼此都有对方的引用。

剩下的@OneToMany、@ManyToOne、ManyToMany类似,这里略过。
@OrderBy——对级联查出来的数据进行排序(@OneToMany、@ManyToMany)
eg.@OrderBy(“create_time DESC”)
@JoinTable——添加关联表(常与@ManyToMany连用)
@EntityGraph、@NamedEntityGraph——用来解决级联的N+1问题
N+1问题:比如A级联B、B级联C,或者A同时级联了B和C,那么如果我们只需要查询B中的数据,那么同时也会将C中的数据也查出来。假如有N个关联关系完成了级联,如果再加入一个关联关系,就变成了N+1个级联——这就造成了很大的资源浪费,可以开启懒加载,在用到时再查询。也可以使用上面的注解。
后面这几个注解没有详解了,建议自行学习一下。
如有错误的地方,欢迎指正!