GARCH模型
GARCH模型的定义
ARCH模型的实质是使用残差平方序列的q阶移动平移拟合当期异方差函数值,由于移动平均模型具有自相关系数q阶截尾性,所以ARCH模型实际上只适用于异方差函数短期自相关系数。
但是在实践中,有些残差序列的异方差函数是具有长期自关性,这时使用ARCH模型拟合异方差函数,将会产生很高的移动平均阶数,增加参数估计的难度并最终影响ARCH模型的拟合精度。
为了修正个问题,提出了广义自回归条件异方差模型, 这个模型简记为GARCH(p,q).
GARCH模型实际上就是在ARCH的基础上,增加考虑异方差函数的p阶自回归性而形成,它可以有效的拟合具有长期记忆性的异方差函数。ARCH模型是GARCH模型的一个特例,p=0的GARCH(p,q)模型。
AR-GARCH模型
对序列拟合GARCH模型有一个基本要求:零均值,纯随机,异方差序列。
有时回归函数不能充分提取原序列中的相关信息,可能具有自相关性,而不是纯随机的,这时需要对序列拟合自回归模型,再考察自回归模型的方差奇性,如果异方差,对它拟合GARCH模型。这样构造的模型为AR(m)-GARCH(p,q).
分析拟合1979年12月31日至1991年12月31日外币对美元日兑换率序列:
w<-read.table("D:/R-TT/book4/4R/data/file23.csv",sep=",",header = T)
x<-ts(w$exchange_rates,start=c(1979,12,31),frequency = 365)
plot(x)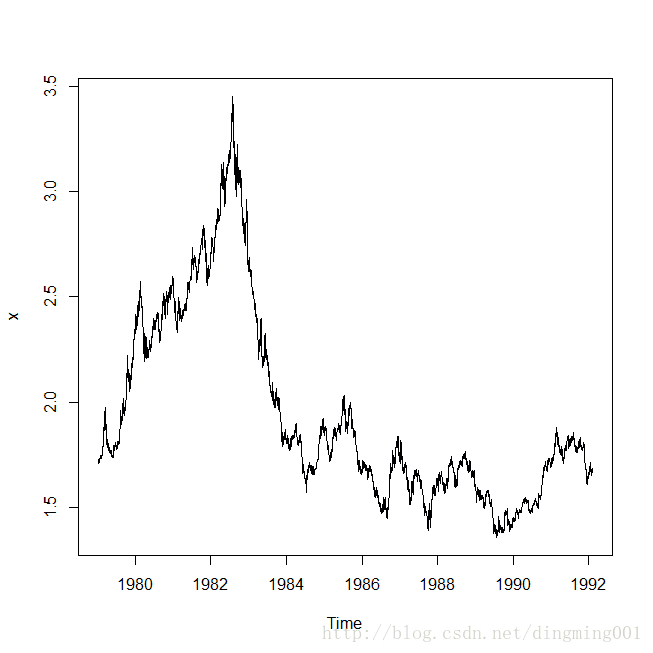
外币对美元日兑换率序列时序图
对差分序列性质的考察
plot(diff(x))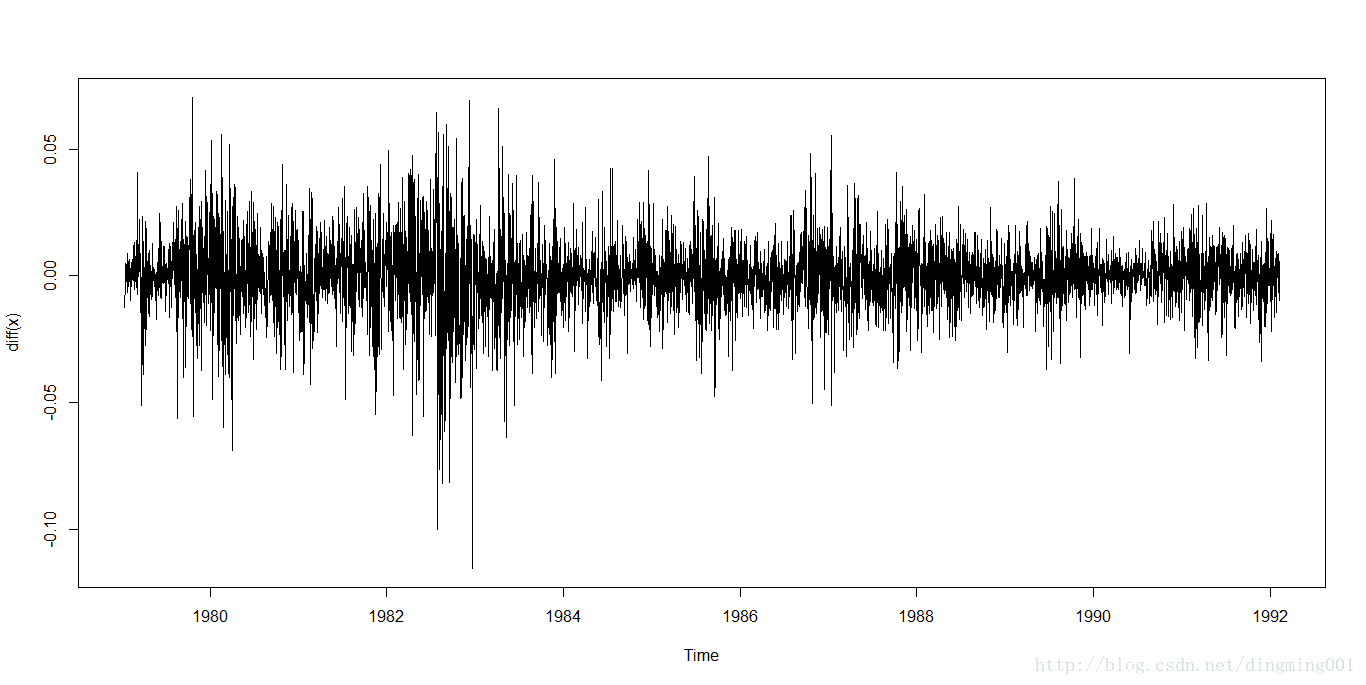
外币对美元日兑换率序列1阶差分时序图
外币对美元日兑换率序列1阶差分自相关图
acf(diff(x))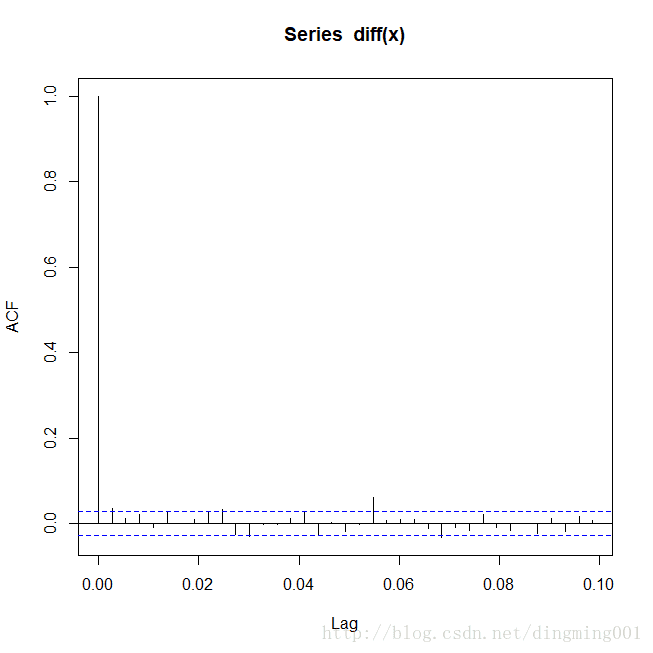
外币对美元日兑换率序列1阶差分自相关图
pacf(diff(x))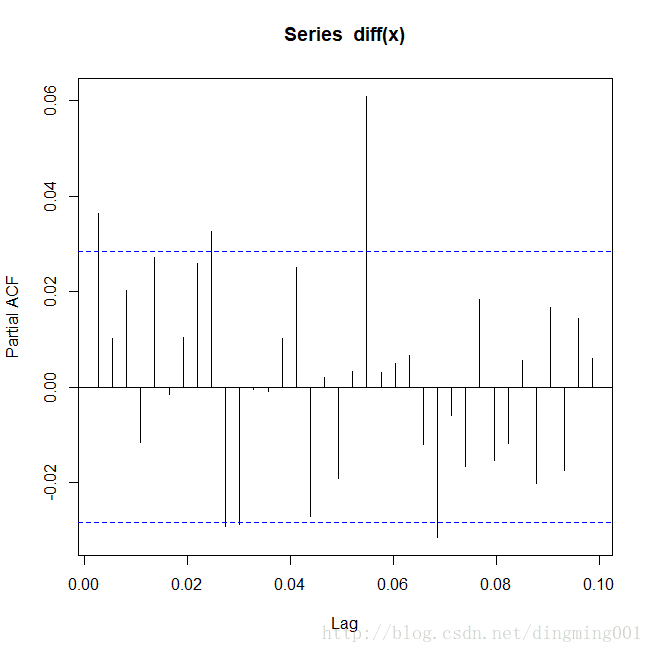
外币对美元日兑换率序列1阶差分偏自相关图
序列时序图显示序列非平稳,有明显的趋势特征,差分后序列时序图显示趋势消除,但是有明显的集群效应,所以分析该序列需要同时提取水平相关信息与波动相关信息。
水平信息的提取是考察差分后的自相关性与偏相关性,拟合ARIMA(0,1,1)。
- 水平相关信息提取
#水平相关信息提取,拟合ARIMA(0,1,1)模型
x.fit<-arima(x,order = c(0,1,1))
x.fit
Call:
arima(x = x, order = c(0, 1, 1))
Coefficients:
ma1
0.0357
s.e. 0.0143
sigma^2 estimated as 0.0002007: log likelihood = 13545.61, aic = -27087.22> #残差白噪声检验
> for (i in 1:6) print(Box.test(x.fit$residual,type = "Ljung-Box",lag=i))
Box-Ljung test
data: x.fit$residual
X-squared = 0.0005354, df = 1, p-value = 0.9815
Box-Ljung test
data: x.fit$residual
X-squared = 0.55102, df = 2, p-value = 0.7592
Box-Ljung test
data: x.fit$residual
X-squared = 2.6528, df = 3, p-value = 0.4483
Box-Ljung test
data: x.fit$residual
X-squared = 3.3062, df = 4, p-value = 0.5079
Box-Ljung test
data: x.fit$residual
X-squared = 6.8276, df = 5, p-value = 0.2338
Box-Ljung test
data: x.fit$residual
X-squared = 6.8306, df = 6, p-value = 0.3368
该拟合模型的残差白噪声检验显示该模型显著成立,利用该拟合模型可以预测列未来的水平。
#水平预测,并绘制预测图
library(forecast)
x.fore<-forecast(x.fit,h=365)
plot(x.fore)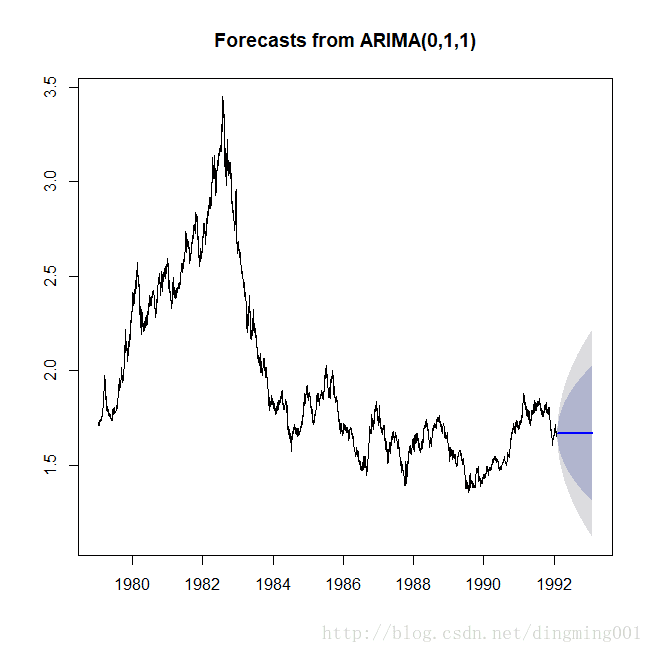
外币对美元日兑换率序列日预测图
- 波动相关信息提取
波动信息的提取首先是考察ARIMA(0,1,1)模型的残差平方序列的异方差特征。
#条件异方差检验(Portmanteau Q检验)
for (i in 1:6) print(Box.test(x.fit$residual^2,type = "Ljung-Box",lag=i))
Box-Ljung test
data: x.fit$residual^2
X-squared = 82.803, df = 1, p-value < 2.2e-16
Box-Ljung test
data: x.fit$residual^2
X-squared = 237.9, df = 2, p-value < 2.2e-16
Box-Ljung test
data: x.fit$residual^2
X-squared = 343.33, df = 3, p-value < 2.2e-16
Box-Ljung test
data: x.fit$residual^2
X-squared = 490.84, df = 4, p-value < 2.2e-16
Box-Ljung test
data: x.fit$residual^2
X-squared = 602.1, df = 5, p-value < 2.2e-16
Box-Ljung test
data: x.fit$residual^2
X-squared = 841.96, df = 6, p-value < 2.2e-16波动信息的提取首先是考察ARIMA(0,1,1)模型的残差平方序列的异方差特征,Portmanteau Q检验显示残差序列显著方差非齐性,且具有长期相关性,所以构造GARCH(1,1)模型,并根据该模型的拟合结果绘制波动的95%置信区间。
#拟合GARCH(1,1)模型
r.fit<-garch(x.fit$residual,order=c(1,1))
summary(r.fit)
Call:
garch(x = x.fit$residual, order = c(1, 1))
Model:
GARCH(1,1)
Residuals:
Min 1Q Median 3Q Max
-4.83074 -0.58407 0.02616 0.58758 4.54060
Coefficient(s):
Estimate Std. Error t value Pr(>|t|)
a0 2.133e-06 3.014e-07 7.077 1.48e-12 ***
a1 7.623e-02 5.456e-03 13.972 < 2e-16 ***
b1 9.144e-01 6.015e-03 152.009 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Diagnostic Tests:
Jarque Bera Test
data: Residuals
X-squared = 319.23, df = 2, p-value < 2.2e-16
Box-Ljung test
data: Squared.Residuals
X-squared = 0.28019, df = 1, p-value = 0.5966`#绘制波动置信区间
r.pred<-predict(r.fit)
plot(r.pred)
外币对美元日兑换率序列残差波动置信区间
GARCH衍生模型
GARCH模型给出了对波动性进行描述的方法,为大量的金融序列提供了有效的分析方法,它是迄今为至最常用的、最便捷的异方差序列拟合模型。但是,大量的使用经验表明,它也存在一些不足。
一是它对参数的约束非常严格,无条件方差必须非负的要求,导致以参数非负的约束条件,同时有条件方差必须平稳的要求,要求参数有界。参数的约束条件一定程序上限制了GARCH模型的适用范围。
二是它对正负扰动的反应是对称,扰动项是真实值与预测值之差。如果扰动项为正,说明真实值比预测值大,对于投资者而言就是获得超预期收益。如果扰动项为负,说明真实值比预测值小,对于投资者而言就是出现超预期亏损。
为了拓展GARCH模型使用范围、提高GARCH模型的拟合精度,统计学家从不同的角度出发,构造了多个GARCH模型的衍生模型。
1.指数GARCH模型(EGARCH)

2.方差无穷GARCH模型(IGARCH)

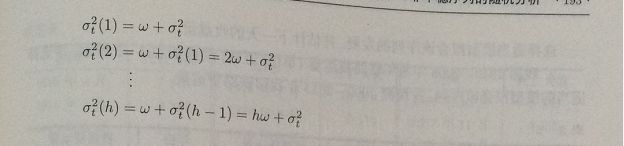
3.依均值GARCH模型(GARCH-M)