TCP拥塞控制算法纵横谈-Illinois和YeAH
周五晚上,终于下了雨,所以也终于可以乱七八糟多写点松散的东西了...
So,我只能从现成的东西入手了...分类学是一个贯通古今的学科,也蕴含在实在太多的方法论中,从中我们可以得出二元论,多元论等等,比如人不是神,神不是人,耶稣既是神,也是人等等,但是总是有另外的声音,这个声音一直抵制着分类,说分类只是方便了人们的后天学习,却阻碍了前瞻。我是赞同的,其实,我也非常抵制分类,我不喜欢把灵活的东西放入人为构建的框架之中。其实消除了分类,我们可以免去很多灾难,比方说你我都能理解的那些宗教战争,民族自决,仇富导致的犯罪,贪欲带来的侵犯...同时,消除分类之后,自然科学也会被促进,甚至融合社会学科,比方说量子力学,博弈论,混沌学...如今,跨界正是另一个视角的反分类学案例,事实证明,跨界带来的成功案例非常多,正是因为跨界让事情变得简单了。So,对于TCP而言,也是一样。
之前的一篇文章《 QVegas-一个升级版的TCP Vegas拥塞算法》中,我给出了QVegas这个非常简陋但足以表达核心思想的一个TCP拥塞控制算法,本文中,我通过几个现成的算法来表达相同的思想。
其实这些算法根本就不是什么新奇的东西,如果不是囿于成见,对待设计拥塞控制算法问题上,每个人的思路几乎都是一样的。正是那些成型的模式,那些教科书被奉为金科玉律,才让我们习惯于将算法分为什么“基于丢包的”,“基于时延的”,“混合的”...如果你要设计一个东西而不是仅仅学会一样东西,那么千万注意,要避开分类!
为什么要避开分类,因为但凡分类都会在类别之间树立屏障,正是这些屏障让一个算法分属了不同的类别,这十分突出地表现在民族和政治问题上,阿尔萨斯,洛林,苏台德区,捷克,希腊,斯拉夫...这都是血的教训。结论是什么,结论就是没有任何屏障可以正确的将事物分类。
正确的做法便是抛弃一切的类别,从本源入手。
正确的做法要么是自己识别拥塞迹象并悬崖勒马般地退让,靠自觉收敛,要么就是依靠控制论里的收敛法则来被动收敛,也就是靠惩罚来收敛。无他。但考虑到自觉收敛这件事确实是看人品的,所以为了保证TCP的绝对收敛,惩罚是必须的,是无条件的。怎么个惩罚法则呢?很简单,MD(乘性减窗)法则。请注意,Linux直到4.8内核都没有开放可以逃避惩罚的接口。
是Google在4.9内核引入BBR的时候才破坏了游戏规则!
基于AIMD的TCP收敛算法被视为经典的“TCP拥塞控制算法”,几乎成了一切TCP拥塞控制算法的根基,这也是事实。但是再次重申,以我的观点来看,简单的AIMD算法并不能控制拥塞,它只是基本原则。
起初,最简单的Reno是一切算法的基础,后来逐步发展进化促成了NewReno,BIC,CUBIC这些变种。但无论哪一个具体的此类算法,都对拥塞没有任何概念,我之前说过,也正是这个发展进化的过程,在一定程度上促进了路由器的缓存越来越大,形成了网络界封闭的安迪-比尔定律。但这又说明什么呢?难道应该把这些算法全部抛弃吗?
不可能抛弃!但这并不是全部。我们需要AIMD的原因是为了收敛,为了全局的公平性AIMD应该包含在所有的拥塞控制算法中,现在的问题是,如果想形成一个完整的拥塞控制算法,AIMD之外我们还需要加入些什么呢?
盗用Illinois的一个图,来自其Wiki页面: https://en.wikipedia.org/wiki/TCP-Illinois
按照这个思路,我们可以看到从上到下的三个图之进化过程。首先,我们可以把第一个图看成是标准的Reno,这一点没有异议,中间的那个图呢,可以看作的畸形版的CUBIC,也还合理,那么下面的那个图谁都可以看出是明显优于上面两个图的,它叫什么?它就是Illinois。
Illinois是怎么做到的呢?
其实很简单,Illinois在AIMD之外考虑了拥塞。所以它成了一个完整的拥塞控制算法,感知了拥塞,并主动回避了拥塞。仔细观察Illinois的窗口-时间曲线,你会发现曲线的斜率在逐渐减小,最终在突破可用BDP的时候越发趋于平缓,这样做的效益是什么?说白了就是Illinois通过RTT的变化主动探测了拥塞的发生,当拥塞尚未发生的时候,窗口增长得快些,而在探测到拥塞将要发生或者已经发生的时候,窗口增长得慢些。
从窗口-时间图上来看,在可用BDP之下,窗口曲线的凹增长向左挤压了Bandwidth lost的区域,在突破可用BDP之后,窗口曲线的凹增长向下压缩了Packet lost区域,就好像Illinois知道可用BDP这个位置似的。注意,Illinois和CUBIC完全不同,CUBIC并不控制拥塞,只为收敛,所以它的窗口曲线会呈现对称的凸凹曲线,CUBIC的曲线在效率明显低于Illinois,因为它的下半段是凹增长的,和Illinois类似,它挤压了Bandwidth lost区域,然而它的上半段是凸的,相当于放大了Packet lost区域,这么做也是无奈之举,由于CUBIC并不感知拥塞,为了公平收敛,其对称的三次凸凹曲线是唯一合理的选择。事实证明,CUBIC的收敛性非常好,虽然它的带宽利用率比较低。
再回到Illinois,我们发现,即使是Illinois也没有想办法减少RTT lost区域,这也无可厚非,毕竟它并不准备主动退避,它依靠的还是被动的惩罚,即MD的过程。So,既然Illinois不会减少RTT lost区域,那么它也是诸多实时连接的噩梦!好在它也有保证公平性。值得注意的是,Buffer found意味着RTT lost!
既然知道了Illinois的窗口曲线走向的细节,下一个问题就是,Illinois是如何做到的?
也不难,它通过采集RTT的变化情况,不断地调整Reno曲线的斜率,造就成了一条动态的不断下凹的曲线(这点是与CUBIC截然不同的,CUBIC仅仅根据AIMD原则来上凸下凹,而Illinois则是通过实际采集的RTT来指导曲线的斜率走向)。
不管怎样,Illinois和CUBIC的基本原则都是AIMD,只是依托的手段不同,对于Illinois而言,其alpha,beta是动态调整的,调整的具体公式就不复制粘贴了,请看: https://en.wikipedia.org/wiki/TCP-Illinois,至于说为什么这样,请更进一步: http://tamerbasar.csl.illinois.edu/LiuBasarSrikantPerfEvalArtJun2008.pdf。
首先看一下内核的help:
YeAH-TCP is a sender-side high-speed enabled TCP congestion control
algorithm, which uses a mixed loss/delay approach to compute the
congestion window. It's design goals target high efficiency,
internal, RTT and Reno fairness, resilience to link loss while
keeping network elements load as low as possible.
很明显,它是一个mixed算法。更进一步,Yeah表达了以下的愿望:
1.在未检测到拥塞的时候,窗口快速增长;
2.在检测到拥塞将要发生或者已经发生的时候,窗口慢速增长;
3.在检测到拥塞将要发生或者已经发生的时候,排掉自己排队的数据包。
注意,上述的2和3显得有点矛盾,其实一点都不矛盾,我的QVegas也是这么做的,其实在将窗口分离成了“基于丢包的分量”和“基于时延的分量”这两个分量之后,2和3确实是两码事,上述2中窗口的增量针对“基于丢包分量”,而2中的窗口增量则针对“基于时延分量”。
现在,我来展示一下TCP Yeah算法的简要流程,标准的流程请参考yeah Paper《 YeAH-TCP: Yet Another Highspeed TCP》,不标准的实现请参考Linux源码,tcp_yeah.c,我给出的是基于Linux实现的算法:
以上就是AI过程。根据AIMD原则,只要发现拥塞就要执行MD,问题是如何发现拥塞!Yeah算法中,MD并非仅仅在“发现丢包”的时候执行,而是平铺到整个过程中,只要发现有拥塞迹象,就马上降窗。问题的关键是,MD一定要比AI猛,这就是罪与罚的原则,如果不懂,建议看看小说《 罪与罚》。
另外值得注意的是,注意到AI过程中reno,fast计数器的增加过程,其实reno这个计数器表示的就是reno窗口分量的大小,因为在标准的Reno AIMD中,每一个RTT窗口就会增加1,而Yeah的Update动作也是按照RTT驱动的,即每一个RTT完成一次Update。
针对于Linux的实现,这个MD过程是“万不得已”的时候才执行的,只要是丢包,哪怕是由于线路噪声造成的丢包,也会执行,这是Linux拥塞控制的框架所决定的,罪与罚,谁也逃不离。问题是,怎么罚。Yeah的答案很简单,如果不是过度拥塞造成的丢包,就减窗少一点,否则就按照标准Reno执行折半减窗。当然在实现细节上,还可以有更多的灵活空间。
...
是不是跟QVegas很像呢?其实啊,正确的方法并不多,只要懂原理,大家最终踏上的都是同一条路,所以说我不得不鄙视一下那些只破不立的家伙了。
那么,怎么样证明你已经精通了TCP的协议头格式或者握手挥手的过程,答案很简单,那就是写下来或者说出来,错与对听闻间便知。
TCP的另外一个层面就没有这么好考核了。那就是TCP的拥塞控制算法方面。为什么我这么说呢?
因为TCP拥塞控制算法它“太简单了”,毫无量化的确定的东西,如果一个人来面试,他可以随便怎么说都行,只要不犯原则性错误,比如说成MIAD,一般都能侃侃而谈好几个小时。所有人都能理解的是网络是大家共享的,难免会拥塞,然后围绕这个话题五花八门的点子就蹦出来了,任何人都不能说这些点子完全正确,却也不能否定它们...我趁着周末的空闲时间,我给我老婆讲半个小时的拥塞控制原理,我相信她马上就能“上手”提出各种“算法”,如果说我老婆学历过高更有文化乃至悟性好的话,我换成我丈母娘或者我妈,我打赌结果完全一样,当然,我并非在否定老年人的智商,我只是说,老年人难免思考能力会退化,精力会不足等等,但也能聪明到理解拥塞控制算法。
那难道TCP拥塞控制算法是一个如此简单的东西吗?不!相反,它是非常难的。
能让一个人侃侃而谈好几个小时不喘气的最著名的例子是什么?是演讲或者传销课,要么就是布道。能让一群人在一起折腾好几个小时不喘气的典型例子是什么?是议会讨论,是选举,是打官司...总之,这些都不是自然科学。TCP的拥塞控制实际上就不是自然科学,而是社会科学。你把一个好的算法交给交管局,让它治理交通同样合适,同时,让一个交警来写拥塞控制算法,那应该可是秒杀格子间的程序员的。所以说它本身就是一个跨学科的范畴,并不仅仅属于程序员。和直觉有点不一致的是,程序员在拥塞控制领域反而处于劣势,因为他们根本就没有机会,时间,精力来探知TCP/IP网络或者交通网络中到底发生了什么以及如何发生的,即便了解到这些,背后那些超级复杂的数学理论也是程序员完全无力企及的,相反,那些运筹学,博弈论,统计学领域内的专家,可能更加适合这个领域。
最近在看《大秦帝国》,里面的一个故事所有人都知道,在赵括面对白起之前,他可是响当当的专家,然而怎么就败了呢?这其中端倪我想不是秦国挑拨离间这么简单。两军打仗跟打架一样,总要至少有一个失败者,这是必然的,如果赵括真的只会纸上谈兵,难道赵国人就是傻逼看不出来吗?其实,我觉得非常简单,就算换成廉颇,说不定也得输,并不是说如果赵国不用赵括的话好像就能赢似的。为什么会输,原因就是因为事实上他输了。打仗之前,要是谁能确定输赢,那就不用打了,直接签条约就好了!同样的,甲午战争,舆论一边倒地倾向于清朝秒杀日本,可是结果呢?
赵括并非弱者,也不是只会纸上谈兵,事实上所有的将军都一样,他只是综合国力的代表罢了,在结局胜负之前,大家都是纸上谈兵,这一点跟TCP拥塞控制领域是完全一样的。
.....................
推荐一个博客: http://www.cnhalo.net/archives,这就是传说中温州皮鞋厂老板的博客。只要能坚持,厂长一定会成为大湿的。但是,我觉得博客的红利时代已经过去了,特别是那些源码分析,实在是太多了,博客文章,书籍都已经汗牛充栋了。另外,现在早就是微信,微博,知乎的时代了,很少有人会看完一篇长篇大论的源码分析了,除非它恰好碰到了自己不懂的,而那个源码分析恰好解决了他的问题。所以说,我建议皮鞋厂老板还是写一些散文体的技术分析文章,重在记录思路,而不是记录Howto。
方法论问题。
这个题目太大以至于内容和题目的关联看起来有失偏颇,不过也无所谓,既然被人以为“没有方法论”而鄙视了,这里也就抛出一些伪方法论,总之,就是一些大而空的东西。我并不是说方法论没有用,而是说方法论太有用了,以至于绝不能误解它。难道方法论不是从已经成功的经验中总结出来的吗?如果还没有成功的案例,那么方法论从何而生呢?So,我只能从现成的东西入手了...分类学是一个贯通古今的学科,也蕴含在实在太多的方法论中,从中我们可以得出二元论,多元论等等,比如人不是神,神不是人,耶稣既是神,也是人等等,但是总是有另外的声音,这个声音一直抵制着分类,说分类只是方便了人们的后天学习,却阻碍了前瞻。我是赞同的,其实,我也非常抵制分类,我不喜欢把灵活的东西放入人为构建的框架之中。其实消除了分类,我们可以免去很多灾难,比方说你我都能理解的那些宗教战争,民族自决,仇富导致的犯罪,贪欲带来的侵犯...同时,消除分类之后,自然科学也会被促进,甚至融合社会学科,比方说量子力学,博弈论,混沌学...如今,跨界正是另一个视角的反分类学案例,事实证明,跨界带来的成功案例非常多,正是因为跨界让事情变得简单了。So,对于TCP而言,也是一样。
之前的一篇文章《 QVegas-一个升级版的TCP Vegas拥塞算法》中,我给出了QVegas这个非常简陋但足以表达核心思想的一个TCP拥塞控制算法,本文中,我通过几个现成的算法来表达相同的思想。
其实这些算法根本就不是什么新奇的东西,如果不是囿于成见,对待设计拥塞控制算法问题上,每个人的思路几乎都是一样的。正是那些成型的模式,那些教科书被奉为金科玉律,才让我们习惯于将算法分为什么“基于丢包的”,“基于时延的”,“混合的”...如果你要设计一个东西而不是仅仅学会一样东西,那么千万注意,要避开分类!
为什么要避开分类,因为但凡分类都会在类别之间树立屏障,正是这些屏障让一个算法分属了不同的类别,这十分突出地表现在民族和政治问题上,阿尔萨斯,洛林,苏台德区,捷克,希腊,斯拉夫...这都是血的教训。结论是什么,结论就是没有任何屏障可以正确的将事物分类。
正确的做法便是抛弃一切的类别,从本源入手。
正确的做法要么是自己识别拥塞迹象并悬崖勒马般地退让,靠自觉收敛,要么就是依靠控制论里的收敛法则来被动收敛,也就是靠惩罚来收敛。无他。但考虑到自觉收敛这件事确实是看人品的,所以为了保证TCP的绝对收敛,惩罚是必须的,是无条件的。怎么个惩罚法则呢?很简单,MD(乘性减窗)法则。请注意,Linux直到4.8内核都没有开放可以逃避惩罚的接口。
是Google在4.9内核引入BBR的时候才破坏了游戏规则!
什么是AIMD以及Reno/NewReno/BIC/CUBIC
说实话,我并不觉得AIMD是一个设计良好的拥塞控制算法之全部,它甚至没有经过设计,它只是经过数学精心确认的一个收敛法则,属于控制论范畴,恰好TCP的首要原则是收敛,那么“采用AIMD策略就是可行的”,并且在后面的日子里,事实证明它工作的还算良好,就一直延续了下去。因此,照这个观点,Reno,NewReno,BIC,CUBIC根本就是非常简陋的“算法”。它们能保证的只是收敛,而根本就和拥塞控制无关,它们并不识别拥塞,也无力识别拥塞,所以也就根本控制不了拥塞。AIMD的核心公式如下:cwnd = cwnd + alpha (per RTT)
cwnd = beta*cwnd (at lost)
基于AIMD的TCP收敛算法被视为经典的“TCP拥塞控制算法”,几乎成了一切TCP拥塞控制算法的根基,这也是事实。但是再次重申,以我的观点来看,简单的AIMD算法并不能控制拥塞,它只是基本原则。
起初,最简单的Reno是一切算法的基础,后来逐步发展进化促成了NewReno,BIC,CUBIC这些变种。但无论哪一个具体的此类算法,都对拥塞没有任何概念,我之前说过,也正是这个发展进化的过程,在一定程度上促进了路由器的缓存越来越大,形成了网络界封闭的安迪-比尔定律。但这又说明什么呢?难道应该把这些算法全部抛弃吗?
不可能抛弃!但这并不是全部。我们需要AIMD的原因是为了收敛,为了全局的公平性AIMD应该包含在所有的拥塞控制算法中,现在的问题是,如果想形成一个完整的拥塞控制算法,AIMD之外我们还需要加入些什么呢?
TCP-Illinois的注解
我先展示一个“经过优化”的AIMD算法,即TCP Illinois算法。盗用Illinois的一个图,来自其Wiki页面: https://en.wikipedia.org/wiki/TCP-Illinois
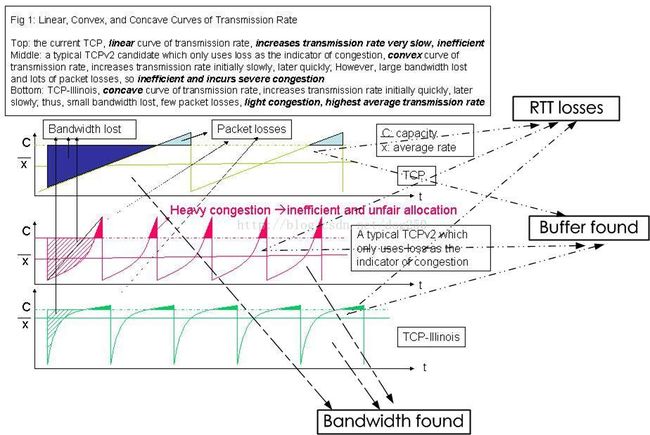
按照这个思路,我们可以看到从上到下的三个图之进化过程。首先,我们可以把第一个图看成是标准的Reno,这一点没有异议,中间的那个图呢,可以看作的畸形版的CUBIC,也还合理,那么下面的那个图谁都可以看出是明显优于上面两个图的,它叫什么?它就是Illinois。
Illinois是怎么做到的呢?
其实很简单,Illinois在AIMD之外考虑了拥塞。所以它成了一个完整的拥塞控制算法,感知了拥塞,并主动回避了拥塞。仔细观察Illinois的窗口-时间曲线,你会发现曲线的斜率在逐渐减小,最终在突破可用BDP的时候越发趋于平缓,这样做的效益是什么?说白了就是Illinois通过RTT的变化主动探测了拥塞的发生,当拥塞尚未发生的时候,窗口增长得快些,而在探测到拥塞将要发生或者已经发生的时候,窗口增长得慢些。
从窗口-时间图上来看,在可用BDP之下,窗口曲线的凹增长向左挤压了Bandwidth lost的区域,在突破可用BDP之后,窗口曲线的凹增长向下压缩了Packet lost区域,就好像Illinois知道可用BDP这个位置似的。注意,Illinois和CUBIC完全不同,CUBIC并不控制拥塞,只为收敛,所以它的窗口曲线会呈现对称的凸凹曲线,CUBIC的曲线在效率明显低于Illinois,因为它的下半段是凹增长的,和Illinois类似,它挤压了Bandwidth lost区域,然而它的上半段是凸的,相当于放大了Packet lost区域,这么做也是无奈之举,由于CUBIC并不感知拥塞,为了公平收敛,其对称的三次凸凹曲线是唯一合理的选择。事实证明,CUBIC的收敛性非常好,虽然它的带宽利用率比较低。
再回到Illinois,我们发现,即使是Illinois也没有想办法减少RTT lost区域,这也无可厚非,毕竟它并不准备主动退避,它依靠的还是被动的惩罚,即MD的过程。So,既然Illinois不会减少RTT lost区域,那么它也是诸多实时连接的噩梦!好在它也有保证公平性。值得注意的是,Buffer found意味着RTT lost!
既然知道了Illinois的窗口曲线走向的细节,下一个问题就是,Illinois是如何做到的?
也不难,它通过采集RTT的变化情况,不断地调整Reno曲线的斜率,造就成了一条动态的不断下凹的曲线(这点是与CUBIC截然不同的,CUBIC仅仅根据AIMD原则来上凸下凹,而Illinois则是通过实际采集的RTT来指导曲线的斜率走向)。
不管怎样,Illinois和CUBIC的基本原则都是AIMD,只是依托的手段不同,对于Illinois而言,其alpha,beta是动态调整的,调整的具体公式就不复制粘贴了,请看: https://en.wikipedia.org/wiki/TCP-Illinois,至于说为什么这样,请更进一步: http://tamerbasar.csl.illinois.edu/LiuBasarSrikantPerfEvalArtJun2008.pdf。
TCP-YeAH注解
和我的QVegas以及微软的Compount算法类似,Yeah采用几乎完全相同的思路,相比之下,Yeah和QVegas非常像,所以我说Yeah是QVegas的完善版,而QVegas则是一个小儿科,其MD过程对公平性的影响根本没有经过数学论证,我也没那个能力和时间以及精力,所以它只是看上去不错而已。那么看一下和QVegas思路一致的算法应该是什么样子吧!它就是Yeah。首先看一下内核的help:
YeAH-TCP is a sender-side high-speed enabled TCP congestion control
algorithm, which uses a mixed loss/delay approach to compute the
congestion window. It's design goals target high efficiency,
internal, RTT and Reno fairness, resilience to link loss while
keeping network elements load as low as possible.
很明显,它是一个mixed算法。更进一步,Yeah表达了以下的愿望:
1.在未检测到拥塞的时候,窗口快速增长;
2.在检测到拥塞将要发生或者已经发生的时候,窗口慢速增长;
3.在检测到拥塞将要发生或者已经发生的时候,排掉自己排队的数据包。
注意,上述的2和3显得有点矛盾,其实一点都不矛盾,我的QVegas也是这么做的,其实在将窗口分离成了“基于丢包的分量”和“基于时延的分量”这两个分量之后,2和3确实是两码事,上述2中窗口的增量针对“基于丢包分量”,而2中的窗口增量则针对“基于时延分量”。
现在,我来展示一下TCP Yeah算法的简要流程,标准的流程请参考yeah Paper《 YeAH-TCP: Yet Another Highspeed TCP》,不标准的实现请参考Linux源码,tcp_yeah.c,我给出的是基于Linux实现的算法:
首先需要定义变量:
Let reno(慢速增窗的大小), fast(快速增窗的大小),slow_cnt(连续处在排队【拥塞】状态的次数)
Let cwnd(当前窗口大小),queue(当前队列的大小)先来看一下AI的过程:
if slow_cnt > 0
slow AI
else
fast AI
if (未到一个非Delay RTT)
return
queue = cwnd*(RTT_now - RTT_min)/RTT_now
if (queue is very long) or (RTT_now is very long)
if (queue is very long) && (cwnd > reno)
reduction = queue/parameter_A
cwnd = cwnd - reduction
reno++
slow_cnt = 0
else
fast++
slow_cnt++
if fast > parameter_B
fast = 0
reno = 2以上就是AI过程。根据AIMD原则,只要发现拥塞就要执行MD,问题是如何发现拥塞!Yeah算法中,MD并非仅仅在“发现丢包”的时候执行,而是平铺到整个过程中,只要发现有拥塞迹象,就马上降窗。问题的关键是,MD一定要比AI猛,这就是罪与罚的原则,如果不懂,建议看看小说《 罪与罚》。
另外值得注意的是,注意到AI过程中reno,fast计数器的增加过程,其实reno这个计数器表示的就是reno窗口分量的大小,因为在标准的Reno AIMD中,每一个RTT窗口就会增加1,而Yeah的Update动作也是按照RTT驱动的,即每一个RTT完成一次Update。
再来看一下MD的过程:
if slow_cnt < parameter_C
reduction = queue
else
reduction = normal MD
ssthresh = cwnd - reduction针对于Linux的实现,这个MD过程是“万不得已”的时候才执行的,只要是丢包,哪怕是由于线路噪声造成的丢包,也会执行,这是Linux拥塞控制的框架所决定的,罪与罚,谁也逃不离。问题是,怎么罚。Yeah的答案很简单,如果不是过度拥塞造成的丢包,就减窗少一点,否则就按照标准Reno执行折半减窗。当然在实现细节上,还可以有更多的灵活空间。
...
是不是跟QVegas很像呢?其实啊,正确的方法并不多,只要懂原理,大家最终踏上的都是同一条路,所以说我不得不鄙视一下那些只破不立的家伙了。
TCP协议的学习
TCP协议分为两个层面,一个是协议的本身语义,这个非常简单,一般经历几场面试你就都懂了,无外乎协议头的格式,三次握手的过程,socket API等等这些,我现在还记得2010年面试的那段时间,最后一家公司的笔试题目有一道简述三次握手过程的题目,我字写的不好,所以就写了两个字,口述,而这家公司最终录用了我,我在那里干了5年半...我并不知道是不是由于我精通TCP的三次握手而加了分,但至少如果我不懂这个三次握手的过程,我肯定会被拒绝。那么,怎么样证明你已经精通了TCP的协议头格式或者握手挥手的过程,答案很简单,那就是写下来或者说出来,错与对听闻间便知。
TCP的另外一个层面就没有这么好考核了。那就是TCP的拥塞控制算法方面。为什么我这么说呢?
因为TCP拥塞控制算法它“太简单了”,毫无量化的确定的东西,如果一个人来面试,他可以随便怎么说都行,只要不犯原则性错误,比如说成MIAD,一般都能侃侃而谈好几个小时。所有人都能理解的是网络是大家共享的,难免会拥塞,然后围绕这个话题五花八门的点子就蹦出来了,任何人都不能说这些点子完全正确,却也不能否定它们...我趁着周末的空闲时间,我给我老婆讲半个小时的拥塞控制原理,我相信她马上就能“上手”提出各种“算法”,如果说我老婆学历过高更有文化乃至悟性好的话,我换成我丈母娘或者我妈,我打赌结果完全一样,当然,我并非在否定老年人的智商,我只是说,老年人难免思考能力会退化,精力会不足等等,但也能聪明到理解拥塞控制算法。
那难道TCP拥塞控制算法是一个如此简单的东西吗?不!相反,它是非常难的。
能让一个人侃侃而谈好几个小时不喘气的最著名的例子是什么?是演讲或者传销课,要么就是布道。能让一群人在一起折腾好几个小时不喘气的典型例子是什么?是议会讨论,是选举,是打官司...总之,这些都不是自然科学。TCP的拥塞控制实际上就不是自然科学,而是社会科学。你把一个好的算法交给交管局,让它治理交通同样合适,同时,让一个交警来写拥塞控制算法,那应该可是秒杀格子间的程序员的。所以说它本身就是一个跨学科的范畴,并不仅仅属于程序员。和直觉有点不一致的是,程序员在拥塞控制领域反而处于劣势,因为他们根本就没有机会,时间,精力来探知TCP/IP网络或者交通网络中到底发生了什么以及如何发生的,即便了解到这些,背后那些超级复杂的数学理论也是程序员完全无力企及的,相反,那些运筹学,博弈论,统计学领域内的专家,可能更加适合这个领域。
最近在看《大秦帝国》,里面的一个故事所有人都知道,在赵括面对白起之前,他可是响当当的专家,然而怎么就败了呢?这其中端倪我想不是秦国挑拨离间这么简单。两军打仗跟打架一样,总要至少有一个失败者,这是必然的,如果赵括真的只会纸上谈兵,难道赵国人就是傻逼看不出来吗?其实,我觉得非常简单,就算换成廉颇,说不定也得输,并不是说如果赵国不用赵括的话好像就能赢似的。为什么会输,原因就是因为事实上他输了。打仗之前,要是谁能确定输赢,那就不用打了,直接签条约就好了!同样的,甲午战争,舆论一边倒地倾向于清朝秒杀日本,可是结果呢?
赵括并非弱者,也不是只会纸上谈兵,事实上所有的将军都一样,他只是综合国力的代表罢了,在结局胜负之前,大家都是纸上谈兵,这一点跟TCP拥塞控制领域是完全一样的。
.....................
推荐一个博客: http://www.cnhalo.net/archives,这就是传说中温州皮鞋厂老板的博客。只要能坚持,厂长一定会成为大湿的。但是,我觉得博客的红利时代已经过去了,特别是那些源码分析,实在是太多了,博客文章,书籍都已经汗牛充栋了。另外,现在早就是微信,微博,知乎的时代了,很少有人会看完一篇长篇大论的源码分析了,除非它恰好碰到了自己不懂的,而那个源码分析恰好解决了他的问题。所以说,我建议皮鞋厂老板还是写一些散文体的技术分析文章,重在记录思路,而不是记录Howto。