写在前面的话
人在河边走,湿鞋是早晚是事情,操作服务器,数据库也一样。谁也不知道自己哪一天控制不住自己就手贱。这时候有两个东西能救我们,一是备份,二是 bin log,bin log 前面讲了,但是 bin log 可能只是由于清理机制,可能里面只是一部分数据。所以,真正它更多的是用来恢复备份恢复以后欠缺的部分最新数据。能够真正拯救我们的,还是需要备份。所以这一节主要谈谈 MySQL 备份恢复。
关于备份
运维或者 DBA 在工作过程中的职责:
1. 设计备份策略,如何时全备,何时增量备份,如何定期备份。
2. 日常检查备份的可用性,对于备份的数据,不仅要检查备份是否成功,还要看数据有没有问题。
3. 定期在测试库恢复数据测试,也是为了检查备份的可用性。
4. 掌握各种数据恢复技巧,能够应对各种可挽救的故障。
备份的分类:
1. 热备:在数据库正常处理业务时备份数据,只能在 innodb 中,几乎不影响业务。
2. 温备:锁表备份,业务只能查,不能改,一半在 MyISAM 中。
3. 冷备:关闭所有业务,保证数据不在变更再度备份。
备份方式分类:
1. 逻辑备份:基于 SQL 的备份,常用工具有 mysqldump,mysqlbinlog。
2. 物理备份:基于磁盘文件的备份,常用工具有 Xtrabackup(XBK)或者 MySQL Enterprise Backup(MEB)。
其中主要的来个就是:mysqldump 和 xtrabackup。
mysqldump 优点:
1. MySQL 自带,不需要自己安装。
2. 备份后是文本的 SQL 语句,可读性和可操作性都强。
3. 压缩比高,能节省磁盘空间。
mysqldump 缺点:
1. 依赖于数据库存储引擎,需要将数据从数据库中读出写入 SQL 文件,比较耗费系统资源,数据量大的话效率低。
一般 100G 以内的实用 mysqldump 完全没问题。当然超过 TB 也可以选择它,但是需要更换方式。
xtrabackup 优点:类似于直接 cp 数据,性能较高。
xtrabackup 缺点:可读性差,压缩比低,占用磁盘空间。一般用于 100G - 1TB 之间的备份。
mysqldump 详解
mysqldump 中最重要的还是备份参数,有些时候一个参数改变可能带来的是质的飞跃,接下来主要谈谈常用的一些参数:
基础的参数 u / p / h / S / P,这几个参数其实和 mysql 登录数据库时候一个意思。
u:指定用户名
p:指定密码
h:指定数据库的 IP(一般用于远程备份)
S:指定 socket 文件(一般在多实例的时候实用)
P:指定端口(一般在默认端口不是 3306 的时候使用)
1. -A:(--all-databases)全备参数,备份所有数据库
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -A >/data/backup/mysql/mysqlbackup.sql
由于在配置文件中之前重新定义了 sock 文件的路径,所以需要专门指定。

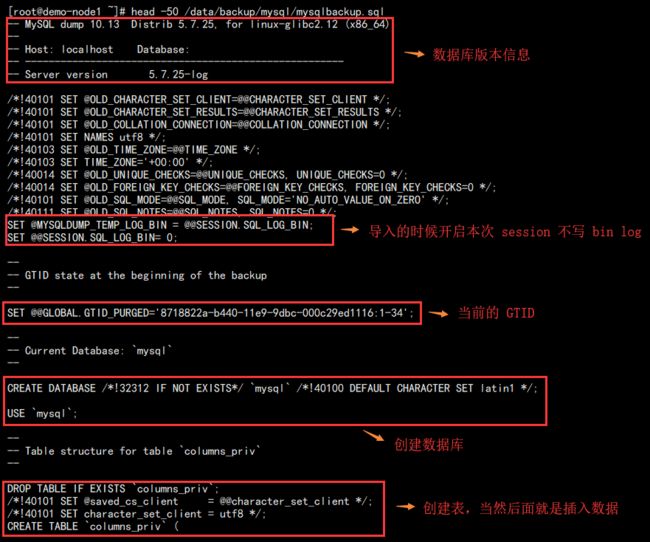
这里有很多提示信息,先不用管,后面一一处理,此时查看备份文件:
head -50 /data/backup/mysql/mysqlbackup.sql
通过前 50 行就可以大致了解备份的结构:
2. -B:备份单个或者多个库
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -B world testdb1 testdb2 >/data/backup/mysql/mysqlbackup_2.sql
此时查看对比来个备份:

可以看出后者明显小很多。
3. 备份某个库下面的指定一个或多个表:
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock world city country >/data/backup/mysql/mysqlbackup_3.sql
不需要任何参数,红色为库名,后面接需要备份的表名就行。当然如果后面不跟表就是整库备份:
# 不用 -B 参数 mysqldump -uroot -p -S /data/logs/mysql/mysql.sock world >/data/backup/mysql/mysqlbackup_4.sql # 使用 -B 参数 mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -B world >/data/backup/mysql/mysqlbackup_5.sql
相比于 -B 参数,该方法只能一个库,而且备份中内容不一样,对比发现,在使用 -B 参数的备份中,多了以下内容:
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `world` /*!40100 DEFAULT CHARACTER SET latin1 */; USE `world`;
使用 -B 参数会多出创建数据库并 use 的过程,而不用 -B 则没,意味着恢复的时候需要手动创建数据库。
4. -R / -E / --triggers:这些参数就是备份时候的大部分提示问题
-R:(--routines)备份存储过程和函数
-E:(--events)备份事件
--triggers:备份触发器
有了这三个参数才是真正的完整的备份:
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -R -E --triggers -A >/data/backup/mysql/mysqlbackup_6.sql
可以看到两次全备大小是不一样的,备份过程也没有了 warning 提示 :

5. -F:(--flush-logs)备份的时候刷新 bin log,这样的好处在于恢复的时候新的 bin log 开始就是增量数据
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -E -R --triggers -A -F >/data/backup/mysql/mysqlbackup_7.sql
6. --master-data:用于保存备份时间点的 bin log 信息,并且备份的时候会自动锁表
0:默认值,不记录
1:以 change master to 的命令格式保存到备份文件中,可以被用于主从复制。
2:推荐使用,以注释的形式写入备份文件。
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -A -E -R --triggers -F --master-data=2 >/data/backup/mysql/mysqlbackup_8.sql
查看备份:
head -50 mysqlbackup_8.sql | grep 'CHANGE'
结果:
![]()
可以看到当前的 bin log 是:MASTER_LOG_FILE='mysql-bin.000026', MASTER_LOG_POS=154
登录数据库查看:

7. --single-transaction:innodb 表进行热备,目的是解决 --master-data 参数带来的锁表问题
在不加该参数的时候,锁定 --master-data 参数相当于温备,锁定所有表。所有一般来个参数一起用。
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -A -E -R --triggers -F --master-data=2 --single-transaction >/data/backup/mysql/mysqlbackup_9.sql
8. --set-gtid-purged:是否在备份中增加 GTID 的命令,一般备份会关闭
auto:默认值,开启
ON:和 auto 其实是一样的
OFF:关闭,不写
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -A -E -R --triggers -F --master-data=2 --single-transaction --set-gtid-purged=OFF >/data/backup/mysql/mysqlbackup_10.sql
查看备份:

此时红色的地方就没了之前的 GTID 相关信息:

这样的好处在于在恢复的时候更方便,否则因为 GTID 在其他库中导入会麻烦一下。
9. --max-allowed-packet:服务端和客户端之间通信缓冲区大小,常用于导出大表
可以查看系统默认:
select @@max_allowed_packet;
结果如图:

可以看到系统默认是 4M,这意味着在导出大表的时候 insert 可能会被拆分成很多很多个。这样的结果就是导入的时候非常慢。
在数据库中,可能插入 2000 条数据和插入 1 条数据事件差不多,insert 越多越耗时。
我自己遇到过导入 5G 的一个表导了 10 多个小时都没有导完,最后还失败了,气得吐血。所有可以适量增加这个值优化导出。
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -A -F -E -R --triggers --master-data=2 --single-transaction --set-gtid-purged=OFF --max-allowed-packet=32M >/data/backup/mysql/mysqlbackup_11.sql
这个值可以根据自己环境调整到合适的。
10. --net-buffer-length:和上面参数类似,也是设置备份时候缓冲区大小。这个主要震度 TCP/IP 和他套接字。
查看系统默认:
select @@net_buffer_length;
结果如图:

默认 16K,可以导出的时候适当调大。
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -A -F -E -R --triggers --master-data=2 --single-transaction --set-gtid-purged=OFF --max-allowed-packet=32M --net-buffer-length=1M >/data/backup/mysql/mysqlbackup_12.sql
当然这来个参数都可以写到 my.cnf 中永久生效。这两个值能够直接让导入速度起飞。
补充说明:生成除了系统的 sys / information_schema / performance_schema 的所有表的单表备份脚本
select concat("mysqldump -uroot -p123 -S /data/logs/mysql/mysql.sock --master-data=2 --single-transaction --set-gtid-pureged=OFF"," ",TABLE_SCHEMA," ",TABLE_NAME," > /data/backup/mysql/",TABLE_SCHEMA,"_",TABLE_NAME,".sql") from information_schema.tables where TABLE_SCHEMA not in ("sys","information_schema","performance_schema") into outfile "/tmp/backup.sh";
补充说明:压缩和添加时间戳:
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -A -F -E -R --triggers --master-data=2 --single-transaction --set-gtid-purged=OFF --max-allowed-packet=128M --net-buffer-length=1M | gzip >/data/backup/mysql/mysqlbackup_$(date +%F).sql.gz
其中 gzip 是压缩,后面加了文件的时间戳:
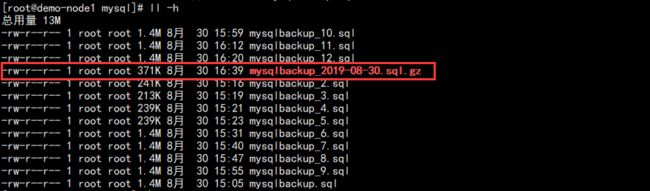
可以看到压缩之后的压缩文件小很多,方便传输,解压只需要使用 gunzip 即可。
补充说明:从备份文件中截取指定表的语句
# 截取指定表建表语句 sed -e'/./{H;$!d;}' -e 'x;/CREATE TABLE `表名`/!d;q' backup.sql > /tmp/create_table.sql # 截取指定表数据 grep 'INSERT INTO `表名`' backup.sql > /tmp/insert_table.sql
备份恢复指定数据库示例
说明:这个示例模仿生成,假设一个库中有很多库,但在操作过程中不小心被误删了某条特别重要的数据,备份只能追随到前一天,我们需要恢复那条数据的同时,又不影响其它业务的正常使用。而且在备份之后,我们并不清楚那条数据是否有再度被修改过。
准备工作:
1. 昨天的备份。
2. 昨天备份开始到现在的所有 bin log。
3. 一个新的测试数据库。
恢复思路:
在测试数据库将旧数据导入,然后根据里面的指针将后面的数据修改从 bin log 导出,剔除删除数据那一行,然后再度将增加的 bin log 导入到测试数据库。由此得到完整的那个数据库,如果事件允许,建议将这个库全部重新在生产导入一次,如果这个数据能确定,那完全可以单独找出这条数据,然后再度在生产执行一次,生成该数据。当然这是该数据比较独立的情况。
注意事项:
1. 为了数据安全,导入之前先备份一个。
2. 如果需要重新这个库全库导入,记得需要将服务引导到维护界面,避免新数据写入该库。
详细模拟操作过程:
1. 查看基础数据:

2. 模拟昨天备份:
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -A -F -E -R --triggers --master-data=2 --single-transaction --set-gtid-purged=OFF --max-allowed-packet=128M --net-buffer-length=1M >/data/backup/mysql/mysqlbackup_12.sql
3. 测试新增数据然后删除指定数据,模拟线上操作:

这里误删除了 sno=3 的那个 sql。
4. 此时测试环境准备一个新的数据库,导入备份:

由于不知道是否该数据后面被改过,所以不敢直接用。需要使用 bin log。
5. 查看 bin log:
head -30 mysqlbackup_12.sql
如图:
![]()
这意味着 34 以后的 bin log 就是新增的数据,我这里没用再度刷新日志,所以就这一个,如果后续刷新过,那么从 34 起后面的都需要。
mysqlbinlog --base64-output=decode-rows -vvv mysql-bin.000034 > /tmp/test.sql
将 bin log 解码出来放到文本中,这样有助于找到 DELETE 语句。
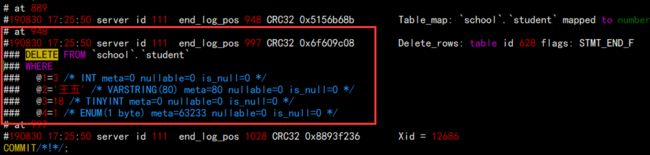
我这里是 948 删除的这个数据,那么我们只需要截取从 194 到 948 的 school 库就行了。注意数据库。
6. 截取 bin log:
mysqlbinlog --skip-gtids --start-position=194 --stop-position=948 mysql-bin.000034 > /tmp/new.sql
7. 将 bin log 的 SQL 在新测试环境执行:
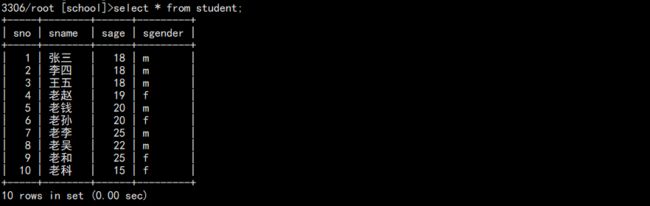
这样 school 库就恢复到了 sno=3 这条数据被删除之前了,我们只需要单独导出这条记录然后在原本的库中执行即可。
至于导出可以使用 Navicat:

语句:
INSERT INTO `school`.`student` (`sno`, `sname`, `sage`, `sgender`) VALUES ('3', '王五', '18', 'm');
旧库执行,至此恢复完成:

Xtrabackup 说明
安装 Xtrabackup:(官网下载非常慢)
# 安装依赖 yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL libev # 下载安装包,MySQL 8.0 以前版本需要使用 2.4 版本 wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.4/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.4-1.el7.x86_64.rpm # 安装 rpm 包 yum localinstall percona-xtrabackup-24-2.4.4-1.el7.x86_64.rpm # 查看安装结果 innobackupex --version
此时可以查看到 xtrabackup 的版本:
![]()
对于 Xtrabackup 备份,几乎所有的操作都集中于 innobackupex 命令。
说说 Xtrabackup:
之前说过,Xtrabackup 属于物理备份,在旧版本中只支持对 innodb 表的备份,不过我们安装的版本已经支持 MyISAM 表的备份了。
对于 MyISAM,采用温备方式,也就是锁表,然后拷贝数据文件。
对于 InnoDB,则是热备方式,拷贝数据页,然后保存成文件,同时还报错 redo 和 undo 部分。
Xtrabackup 全库备份恢复
Xtrabackup 整体备份恢复流程:
1. 在执行 innobackupex 时,立即触发 ckpt(check point),将已经提交的数据脏页写到磁盘中,记录此时的 LSN(日志)号。
2. 备份开始执行,拷贝磁盘数据页,并记录整个备份过程中新生成的 redo 和 undo。再次记录此时的 LSN 号。
3. 在恢复时,前面说过 MySQL 自动恢复 CSR,通常在执行 Xtrabackup 的时候,数据都挂了,所以需要手动 CSR,将 redo 和 undo 应用。
4. 最终恢复过程就是将结果 CSR 的备份文件 cp 过去替换掉我们之前的所有数据。
执行最简单的全备:
1. 默认全备方式:
innobackupex --user=root --password=123 /data/backup/mysql/
注意,该过程会调用 /etc/my.cnf,有些时候会报错无法找到 mysql.sock,或者我们的端口直接就不是 3306,此时有两种办法解决:
方法1:--port 和 --socket 参数可以指定相关的参数。
方法2:在 /etc/my.cnf 后面增加配置,不用重启数据库:
[clienct] port=3306 socket=/data/logs/mysql/mysql.sock
之前说过客户端定义的词,其实都可以给他配上,有些客户端调用的时候可能用的时另外一个。
由于时客户端直接调用这个值,所以不需要重启数据库。此时去查看备份情况:
![]()
此时在备份目录下生成了一个时间戳目录,该目录下就是备份的数据。但是显然这种名称不适合管理。
2. 定义备份的名称:
innobackupex --user=root --password=123 --no-timestamp /data/backup/mysql/mysql-full-$(date +%F)
自定义备份目录的名称,名称有意义,便于管理。

注意这个备份成功的标志。查看备份情况:

备份文件说明:

其中目录和 ibdata1 这些很熟悉,就是 MySQL 数据目录下面的文件,不用再次说明,主要说明下面的 4 个文件。
1. xtrabackup_binlog_info:
![]()
很明显,这个文件时记录了备份之后 bin log 的 position 和 gtid,这意味着增量恢复的时候也是能够使用 bin log 恢复增量的。
2. xtrabackup_checkpoints:

最重要的 3 个值:
from_lsn:开始的 LSN 值,上面说了会记录开始时候的 LSN 值,由于是全备,所以是 0。
to_lsn:这个是执行备份时间点的 LSN 值。
last_lsn:这个是真正完成备份时间点的 LSN 值。
如果 last - to 的值为 9,说明在整个备份期间,没有数据变动。
3. xtrabackup_info:
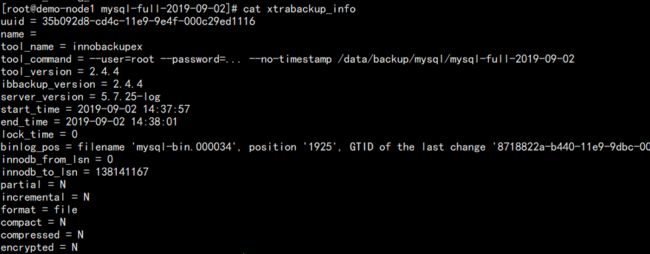
整体的一些信息,不用特别关注。
4. xtrabackup_logfile:
该文件不是文本文件,二是 data 文件,所以不能直接打开。
![]()
这里面就是 redo 和 undo 的一些信息。
全备恢复恢复前提:
1. 准备一个新的 MySQL。绝对不能直接使用生产的数据库,如果出问题就直接爆炸。
2. 关闭新的 MySQL 并删除数据目录下面的所有文件。
开始全库恢复:
1. 清理新库的所有数据并将备份拷贝到新库的服务器:

已经清空了新库的所有数据并拷贝过去了备份,当然新库也要安装 percona-xtrabackup。
2. 手动 CSR,由于当前数据库无法启动,所有需要手动 CSR,这是工具带有的功能。
当然,即使数据库能用也不能让它 CSR,否则可能会报错。
innobackupex --apply-log /data/backup/mysql/mysql-full-2019-09-02/
如图:

最后这个标识标识应用完成。
3. 此时只需要将处理过后的数据拷贝到数据目录更改授权即可:
cp -r /data/backup/mysql/mysql-full-2019-09-02/* /data/data/mysql/
chown -R mysql.mysql /data/data/mysql/
4. 启动数据库查看:

可以看到所有数据全部恢复已经。
Xtrabackup 增量备份
对于增量备份,前提是有一个全备在之前,然后采用增量一说,也就是基于谁的增量。
innobackupex --user=root --password=123 --no-timestamp --incremental --incremental-basedir=/data/backup/mysql/mysql-full-2019-09-02 /data/backup/mysql/mysql-inc-1-$(date +%F)
参数说明:
--incremental:开启增量备份,必要参数
--incremental-basedir:指定基于哪个备份就行增量
最后就是备份放到哪个目录。
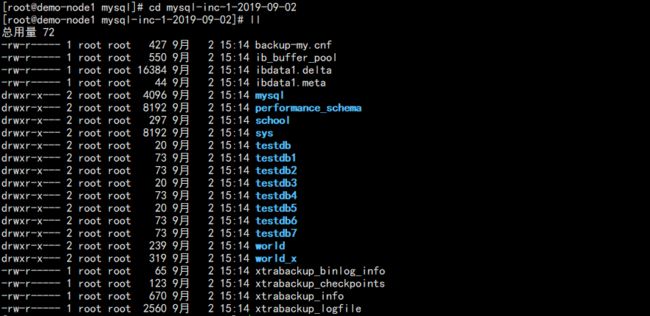
此时查看备份文件其实结构和之前差不多,但这里面只有增量。

可以看到增量 from LSN 号其实不是全备的 to LSN 号,而应该是 last LSN 号 -9,之所以等于 to LSN,是因为没有新数据写入。
因为有了备份策略,于是对于使用 xtrabackup 的备份策略就可以使用:
每周一次全备,其它时候使用增量备份,这样能够对于大数据量的库可以节省很多资源。因为 xtrabackup 很吃 IO 和磁盘空间的。
全备和增量备份恢复示例
模拟故障发生过程:
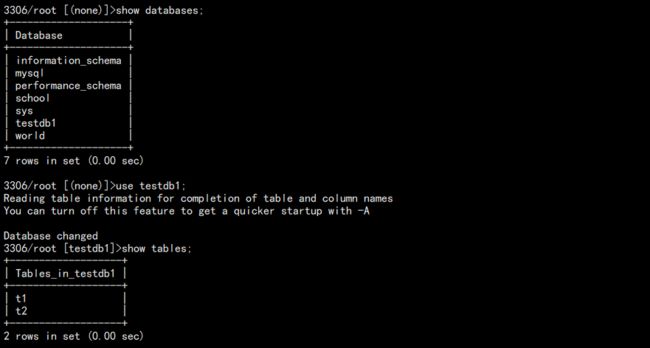
1. 先清理掉没用的库,基础环境如下:

2. 此时执行一个全备,模拟全备:
innobackupex --user=root --password=123 --no-timestamp /data/backup/mysql/mysql-full-$(date +%F)
结果:
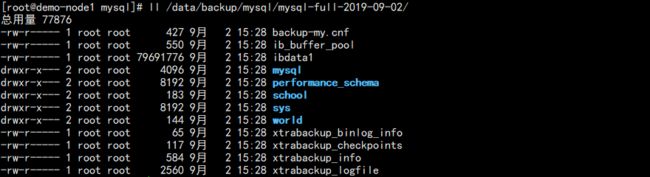
查看此时 LSN 信息:

3. 此时模拟修改数据:

4. 执行增量备份:
innobackupex --user=root --password=123 --no-timestamp --incremental --incremental-basedir=/data/backup/mysql/mysql-full-2019-09-02 /data/backup/mysql/mysql-inc-1-$(date +%F)
查看:

5. 再次模拟增加数据:
6. 模拟第二次增量备份:
innobackupex --user=root --password=123 --no-timestamp --incremental --incremental-basedir=/data/backup/mysql/mysql-inc-1-2019-09-02 /data/backup/mysql/mysql-inc-2-$(date +%F)
查看备份:

7. 模拟第三次修改数据并删库:
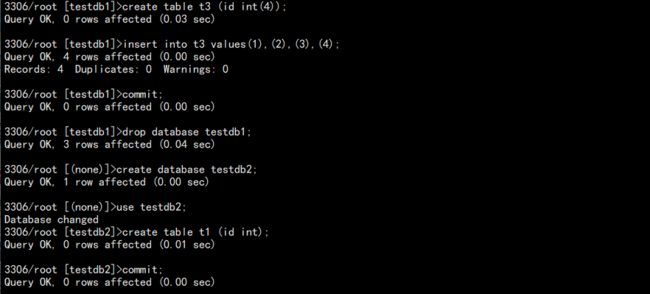
到此,整个故障过程已经模拟了出来,一个全备,两个增备,还有些来不及备份的数据。需要恢复数据。
故障解决思路:
1. 使用全备恢复基础数据。
2. 使用增量恢复能够恢复的新增数据。
3. 使用 bin log 恢复剩余数据。
4. 所有操作在新建的数据库上面操作,超级重要。
故障解决过程:
1. 将所有的备份拷贝到新服务器:

2. 我们需要将所有的备份合并成一个,这就包含了 xtrabackup 的合并操作:
a. 按照备份顺序手动执行 CSR,先对 full 进行操作:
innobackupex --apply-log --redo-only /data/backup/mysql/mysql-full-2019-09-02
b. 对第一次增量进行 CSR 并合并到 full 中去:
innobackupex --apply-log --redo-only --incremental-dir=/data/backup/mysql/mysql-inc-1-2019-09-02 /data/backup/mysql/mysql-full-2019-09-02
注意,这里使用的是 --incremental-dir 而不是 basedir。
c. 进行最后一次增量备份合并:
innobackupex --apply-log --incremental-dir=/data/backup/mysql/mysql-inc-2-2019-09-02 /data/backup/mysql/mysql-full-2019-09-02
注意,最后一次增量在合并的时候,不再需要:--redo-only
d. 所有增量都合并完成以后,对 full 在次进行整理:
innobackupex --apply-log /data/backup/mysql/mysql-full-2019-09-02/
此时查看:

此时的 to LSN 和 last LSN 已经变成了我们最后一次增量备份的值了。
3. 删除新库下面的数据,然后拷贝恢复:
pkill mysqld rm -rf /data/data/mysql/* cp -r /data/backup/mysql/mysql-full-2019-09-02/* /data/data/mysql/ chown -R mysql.mysql /data/data/mysql/
启动查看:
可以看到,备份的数据已经恢复,接下来恢复增量。
4. 查看最新一次增量备份的 bin log:
![]()
5. 导出处理后的 bin log:
查看当前的 GTID:

将 bin log 导出,方便找到 drop 语句:
mysqlbinlog --base64-output=decode-rows -vvv /data/logs/mysql/binlog/mysql-bin.000034 > /tmp/all.sql
使用 vim /tmp/all.sql 然后搜索 drop:
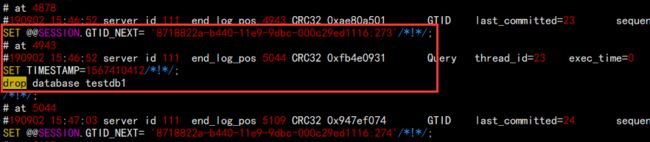
本地我们采用 gtid 的方法获取增量 SQL,所以酒要排除 273。
所以本次 GTID 范围:270 - 275 但是排除 273。
mysqlbinlog --skip-gtids --include-gtids="8718822a-b440-11e9-9dbc-000c29ed1116:270-275" --exclude-gtids="8718822a-b440-11e9-9dbc-000c29ed1116:273" /data/logs/mysql/binlog/mysql-bin.000034 > /tmp/bin.sql
6. 将 SQL 传到新数据库恢复:
source /tmp/bin.sql
结果:
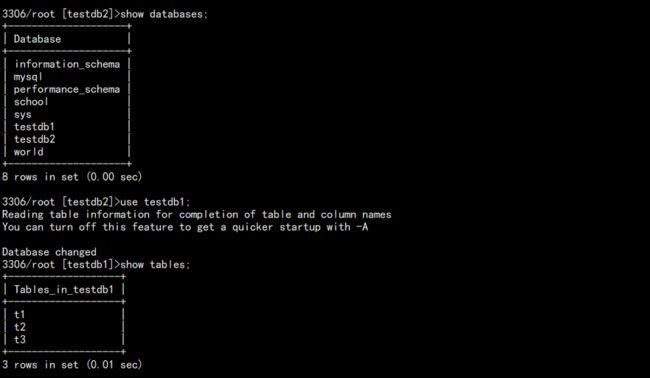
至此,数据已经全部恢复!
小结
本章节是救命章节,包含两种备份已经恢复方式,以及抽取数据恢复。这些操作无不提醒着我们备份的重要性。这个备份还包括异地备份。因为本地可能 rm -rf /*。
数据安全第一位,规范的操作才是不跑路的根本。