1. 绪论
0x1:信息论与其他学科之间的关系
信息论在统计物理(热力学)、计算机科学(科尔莫戈罗夫复杂度或算法复杂度)、统计推断(奥卡姆剃刀,最简洁的解释最佳)以及概率和统计(关于最优化假设检验与估计的误差指数)等学科中都具有奠基性的贡献。如下图

这个小节,我们简要介绍信息论及其关联的思想的来龙去脉,提纲挈领地给出一个总的框架。
1. 电子工程(通信理论)
香农(shannon)证明了只要通信速率低于信道容量,总可以使误差概率接近于零。同时,香农还进一步讨论了诸如音乐和语音等随机信号都有一个不可再降低的复杂度。遵从热力学的习惯,他将这个临界复杂度命名为熵,并且讨论了当信源的熵小于信道容量时,可以实现渐进无误差通信。
如果将所有可能的通信方案看成一个集合,那么信息论描绘了这个集合的两个临界值:
- 左临界值
 :数据压缩达到最低程度的方案,所有数据压缩方案所需的描述速率不得低于该临界值
:数据压缩达到最低程度的方案,所有数据压缩方案所需的描述速率不得低于该临界值 - 右临界值
 :数据传输速率达到最大的方案,临界值即信道容量,所有调制方案的极限传输速率都必须低于该值
:数据传输速率达到最大的方案,临界值即信道容量,所有调制方案的极限传输速率都必须低于该值
综上,所有调制方案和数据压缩方案都必须介于这两个临界值之间。
信息论从理论上提供了能够达到这些临界值的通信方案,但是要注意的是,最佳方案固然很好,但从计算的角度看,它们往往是不切实际的。唯一原因是,只有使用简单的调制与解调方案时才具有计算可行性。
2. 计算机科学(科尔莫戈罗夫复杂度或算法复杂度)
科尔莫戈罗夫、Chaitin、Solomonoff指出,一组数据串的复杂度可以定义为计算该数据串所需的最短二进制程序的长度。因此,复杂度就是最小描述长度。
利用这种方式定义的复杂度是通用的,即与具体的计算机无关,因此该定义具有相当重要的意义。科尔莫戈罗夫复杂度的定义为描述复杂度的理论奠定了基础。
更令人激动的是,如果序列服从熵为H的分布,那么该序列的科尔莫戈罗夫复杂度K近似等于香侬熵H。所以信息论与 科尔莫戈罗夫复杂度二者有着非常紧密的联系。
算法复杂度与计算复杂度二者之间存在微妙的互补关系:
- 计算复杂度(时间复杂度)可以看成对应于程序运行时间
- 科尔莫戈罗夫复杂度(程度长度或者描述复杂度)可以看成对应于程序长度
二者是沿着各自的轴的最小化问题,同时沿两条轴进行最小化的工作几乎没有。
3. 统计物理(热力学)
熵与热力学第二定律都诞生于统计力学。对于孤立系统,熵永远增加。根据热力学第二定律,永动机是不存在的。
4. 数学(概率论和统计学)
信息论中的基本量,熵、相对熵、互信息,定义成概率分布的泛函数。它们中的任何一个量都能刻画随机变量长序列的行为特征,使得我们能够估计稀有事件的概率(大偏差理论),并且在假设检验中找到最佳的误差指数。
渐进均分性(AEP)证明绝大部分序列是典型的,它们的样本熵接近于H,因此我们可以把注意力集中在大约2nH个典型序列上。在大偏差理论中,考虑任何一个由分布构成的集合,如果真是分布到这个集合最近元的相对熵距离为D,那么它的概率大约为2-nD。
信息论从相对熵的角度度量了不用随机变量概率分布之间的误差距离,这和数理统计中的拟合优度理论形成了统一。
5. 科学的哲学观(奥科姆剃刀)
奥卡姆居士威廉说过“因不宜超出果之因所需。”,即“最简单的解释是最佳的”。
Solomonoff和Chaitin很有说服力地讨论了这样的推理:谁能获得适合处理数据的所有程序的加权组合,并能观察到下一步的输出值,谁就能得到万能的预测程序。
如果是这样,这个推理可以用来解决许多会用统计方法不能处理的问题,例如:
- 这样的程序能够最终预测圆周率π的小数点后面遥远位置上的数值。
- 从理论上保证退出物理学中的牛顿三大定律。
当然,这是一个理论上的完备预测器,这样的推理极度的不切实际。如果我们按照这种推理来预测明天将要发生的事情,那么可能要花一百年时间。
6. 经济学(投资)
在平稳的股票市场中重复投资会使财富以指数增长。财富的增长率与股票市场的熵率有对偶关系。股票市场中的优化投资理论与信息论的相似性是非常显著的。
7. 计算与通信
当将一些较小型的计算机组装成较大型的计算机时,会受到计算和通信的双重限制。计算受制于通信速率,而通信受制于计算速度,它们相互影响、相互制约。因此,通信理论中所有以信息论为基础所开发的成果,都会对计算理论造成直接的影响。
8. 量子力学
在量子力学中,冯诺依曼(von Neumann)熵 扮演了经典的香农-玻尔兹曼(Shannon-Boltzmann)熵
扮演了经典的香农-玻尔兹曼(Shannon-Boltzmann)熵 的角色。由此获得数据压缩和信道容量的量子力学形式。
的角色。由此获得数据压缩和信道容量的量子力学形式。
0x2:信息论视角下的随机变量编码问题
考虑一个服从均匀分布且有32种可能结果的随机变量,为确定一个结果,需要一个能够容纳32个不同值的标识,因此,根据熵定理,用5比特的字符串足以描述这些标识,即:

在均匀分布的等概论情形下,所有结果都具有相同长度的表示。
接着考虑一个非均匀分布的例子,假定有8匹马参加的一场赛马比赛,设8匹马的获胜概率分布为(1/2,1/4,1/8,1/16,1/64,1/64,1/64,1/64),我们可以计算出该场赛马的熵为:
![]()
下面来思考一个问题,现在需要将哪匹马会获胜的消息发出去,该怎么达到这个目标?
从机器学习的视角范畴来看,这本质上就是一个特征工程特征编码问题,即如何对随机变量进行向量化编码。
一个最简单直白的策略就是“one-hot独热编码”,即发出胜出马的编号,这样,对任何一匹马,描述需要3比特。
但其实我们换一个思路想问题,从单次的随机试验视角中拉高到大量的重复随机试验集合中,我们还可以有更高效的编码方式,一个很简单的道理:较少发生的事情给予相对较长的描述,而较常发生的事情给予相对较短的描述。
这样,从总体上来说,我们会获得一个更短的平均描述长度。例如,使用以下的一组二元字符串来表示8匹马:(0,10,110,1110,111100,111101,111110,111111)。此时,平均描述长度为2比特,比使用等长编码时所用的3比特小。
使用随机生成的编码方案,
0x3:信息论视角下的通信信道问题
通信信道是一个系统,系统的输出信号按概率依赖于输入信号。该系统特征由一个转移概率矩阵p(y|x)决定,该矩阵决定在给定输入情况下,输出的条件概率分布。
对于输入信号为X和输出信号为Y的通信信道,定义它的信道容量C为:

信道容量是可以使用该信道发送信息的最大速率,而且在接收端以极低的误差概率恢复出该信息。
下面有一些例子来说明信道的速率和误码率等问题。
1. 无噪声二元信道
对于无噪声二元信道,二元输入信号在输出端精确地恢复出来,如下图所示:
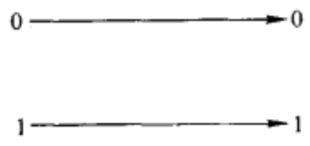
在此信道中,任何传输的信号都会毫无误差地被接受,因此,在每次传输中,可以将1比特的信息可靠地发送给接收端,从而信道容量为1比特,即![]()
2. 有噪声四字符信道
四字符信道如下图:
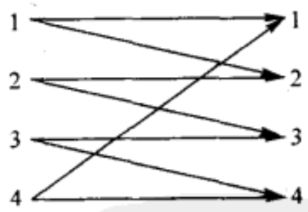
在该信道中,传输每个输入字符时,能够正确地接受到该字符的概率为1/2,误报为它的下一个字符的概率也为1/2。如果将4个输入字符全部考虑进去,那么在接收端,仅凭单个输出结果根本不可能确切判定输入端是哪个字符。
另一方面,如何使用2个输入(例如1和3,或者2和4),我们立即可以根据输出结果知道传输的是哪个输入字符,于是,这种信道相当于一个无噪声信道,该信道上每传输一次可以毫无误差地发送1比特信息,信道容量![]() 也同样等于1比特/传输。
也同样等于1比特/传输。
抽象地思考一下,考虑一系列传输,任何信道看起来都会像此例一样,并且均可以识别出输入序列集合(马子集)的一个子集,其传输信息的方式是:对应于每个码字的所有可能输出序列构成的集合近似不相交。此时,我们可以观察输出序列,能够以极低的误差概率识别出相应的输入码字。
3. 近似无损通信信道
随用随机生成的编码方案,香农证明了,如果码率不超过信道容量C(可以区分的输入信号个数的对数),就能够以任意小的误差概率发送信息。
随机生成码的思想非同寻常,为简化难解问题打下了基础,因为在实际工程中,我们无法总是100%得到一个最优编码方案,香农的近似无损通信信道理论告诉我们,在一定的误差容忍度范畴内,可以去设计一个近似最优的编码方案。
笔者思考:从机器学习的视角范畴来看,每一个算法模型本质上都是一个通信信道。数据从输入层输入,经过模型的压缩后,将有效信息传输都输出层,将输出层的熵降低到足以得到目标的结果(生成式模型或者判别式模型)。
Relevant Link:
《信息论基础》阮吉寿著 - 第一章
2. 熵、相对熵、互信息
0x1:熵(entropy)
信息是一个相当宽泛的概念,很难用一个简单的定义将其完全准确地把握。然而,对于任何一个概率分布,可以定义一个称为熵(entropy)的量,它具有许多特性符合度量信息的直观要求。
1. 熵的形式化定义
熵是随机变量不确定度的度量。设X是一个离散型随机变量,其字母表(概率论中的取值空间)为X,概率密度函数![]() ,则该离散型随机变量X的熵H(X)定义为:
,则该离散型随机变量X的熵H(X)定义为:
 ,熵的单位用比特表示。
,熵的单位用比特表示。
注意,熵实际上是随机变量X的分布的泛函数,并不依赖于X的实际取值,而仅依赖于其概率分布。
从数理统计的角度来看,X的熵又解释为随机变量 的期望值,其中p(X)是X的概率密度函数,于是有:
的期望值,其中p(X)是X的概率密度函数,于是有:

0x2:联合熵(joint entropy)
1. 联合熵形式化定义
基于单个随机变量熵的定义,现在将定义推广到两个随机变量的情形。
对于服从联合分布为p(x,y)的一对离散随机变量(X,Y),其联合熵H(X,Y)(joint entropy)定义为:
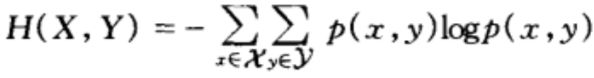
带入联合期望公式,上式也可表示为:
![]()
0x3:条件熵(conditional entropy)
1. 条件熵形式化定义
定义一个随机变量在给定另一个随机变量下的条件熵,它是条件分布熵关于起条件作用的那个随机变量取平均之后的期望值。
若(X,Y)~p(x,y),条件熵(conditional entropy)H(Y | X)定义为:
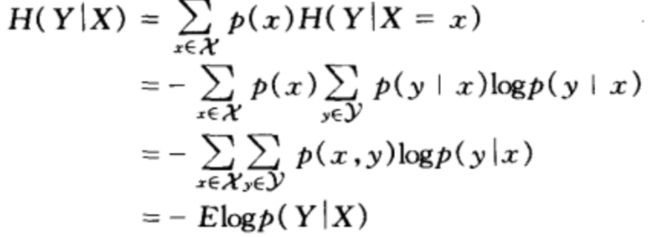
笔者思考1:从条件熵的角度理解算法模型的训练及模型拟合过程,如果我们将初始状态的模型参数看做是一个由若干个未知量组成的联合概率分布,即(X1,X2,...,Xn)。在训练开始前,我们对模型参数的可能取值完全没有任何先验,理论上所有参数都符合均匀分布,此时H(X1,X2,...,Xn)达到最大值。训练的过程是不断向模型输入有标签的样本并通过负反馈以及一定的策略不断调整模型的参数取值,从信息论的角度来看,有监督训练样本的作用是向联合概率分布注入新的信息Y,即(X1,X2,...,Xn | Y)。新的信息Y使得模型参数联合概率分布的的联合熵减小,即消除不确定性。而最终模型训练以及泛化能力的好坏,则取决于训练样本能多大程度地消除所有的不确定性,留下确定性的判断依据。
笔者思考2:从条件熵的角度看训练样本的标注(label)精确性重要性,如果在训练样本中,对同一类的样本既有黑标也有白标,这样会造成对同一个特征向量同时有label=1/0,相当于传递了一个均匀分布最大熵,这类样本对模型训练就是没有任何帮助的,甚至可能带来欠拟合波动。但是如果同一类样本(同一类特征向量)只有纯净的黑标或者白标,相当于传递了一个100%确定事件,条件熵为0,即为一次有效性训练。具体来说就是,在完成特征工程后,对特征维度字段进行groupby聚合,并检查是否出现了同时label=0/1的现象,如果出现要及早清楚或重打标。
0x4:相对熵(relative entropy)
1. 相对熵直观理解
相对熵(relative entropy)是两个随机分布之间距离的度量。在统计学中,它对应的是似然比的对数期望(极大似然估计的损失函数值)。
相对熵![]() 度量当真实分布为p而假定分布为q时的无效性。
度量当真实分布为p而假定分布为q时的无效性。
例如,已知随机变量的真实分布为p,可以构造平均描述长度为H(p)的码,但是如果使用针对分布q的编码,那么在平均意义上就需要 H(p)+D(p || q) 比特来描述这个随机变量。
2. 相对熵公式形式化定义
设两个概率密度函数为p(x)和q(x)之间的相对熵或Kullback-Leiler距离定义为:

需要注意的是,相对熵并不对称,也不满足三角不等式,因此它实际上并非两个分布之间的真正距离。然而,将相对熵视作分布之间的”距离“往往会非常有用,相对熵和数理统计中的很多理论概念之间也存在非常多的关系。
3. 条件相对熵(conditional relative entropy)
对于联合概率密度函数p(x,y)和q(x,y),条件相对熵![]() 定义为条件概率密度函数 p(y|x) 和 q(y|x) 之间的平均相对熵,其中取平均是关于概率密度函数p(x)而言的,即:
定义为条件概率密度函数 p(y|x) 和 q(y|x) 之间的平均相对熵,其中取平均是关于概率密度函数p(x)而言的,即:
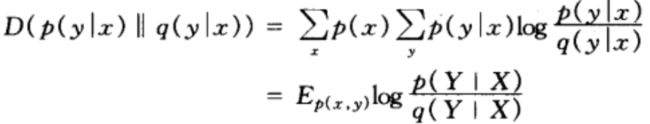
0x5:互信息(mutual information)
互信息是一个随机变量包含另一个随机变量信息量的度量。互信息也是在给定另一随机变量知识的条件下,原随机变量不确定度的缩减量。
1. 互信息公式形式化定义
考虑两个随机变量X和Y,它们的联合概率密度函数为p(x,y),其边际概率密度函数分别是p(x)和p(y)。互信息![]() 为联合分布p(x,y)和乘积分布p(x)p(y)之间的相对熵,即:
为联合分布p(x,y)和乘积分布p(x)p(y)之间的相对熵,即:

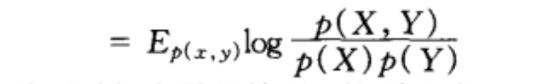
注意,一般![]()
2. 熵与互信息的关系
可将互信息![]() 重新写为:
重新写为:

可以看出,互信息![]() 是在给定Y知识的条件下,X的不确定度的缩减量。
是在给定Y知识的条件下,X的不确定度的缩减量。
对称地,亦可得下式:
![]()
由此得到一个推论:X含有Y的信息量等同于Y含有X的信息量。
特别的,有:
![]()
随机变量与自身的互信息为该随机变量的熵,也称为自信息(self-information)。
3. 互信息和熵之间的关系
H(X),H(Y),H(X,Y),H(X | Y),H(Y | X),I(X;Y)之间的关系可用文氏图表示。

注意到,互信息I(X;Y)对应于X的信息和Y的信息的相交部分。
基于该文氏图,我们有如下定理:
4. 条件互信息(conditional mutual information)
条件互信息是指在给定Z时,由于Y的知识而引起关于X的不确定度的缩减量。
随机变量X和Y在给定随机变量Z时的条件互信息为:

5. 从互信息的角度看线性回归参数的拟合程度
笔者思考:从信息论的角度来看,模型对目标随机变量概率分布的拟合程度,可以用互信息来进行定量表征。模型对目标随机变量概率分布拟合地越好,则模型对目标随机变量的代表性就越强,两者之间的互信息也就越强。
0x6:联合熵、相对熵、互信息的链式法则
1. 两个随机变量联合熵的链式法则
联合熵和条件熵的定义的这种自然性可由一个事实得到体现,它就是:一对随机变量的熵等于其中一个随机变量的熵加上另个一随机变量的条件熵。
形式化定义如下式:
![]()

2. 两个以上随机变量联合熵的链式法则
在双随机变量联合熵文氏图的基础上,我们继续进行抽象思考,本质上来说,时间万物都可以抽象为多个随机变量的联合作用的综合结果,如果直接将其看做一个黑盒整体看待,则我们看不到任何规律存在其中,因为完全是混沌。解决的方法就是进行合理的剥离与分解。但同时要注意的是,世间万物又不是彼此独立存在的,所有人和所有人之间都存在互相影响的关系。
通过数学的方式来形式化表达上面这句话就是多随机变量联合熵的链式法则。联合熵的链式法则解决的是联合熵如何分解的问题。
设随机变量X1,X2,Xn服从p(x1,x2,....,xn),则

证明过程重复利用两个随机变量情况下熵的链式展开法则:

3. 联合熵链式法则在NLP问题中的应用
笔者思考:多随机变量的联合熵链式法则是一个高度抽象概括的定理,NLP语言模型的链式分解就是基于此发展出来的,在NLP问题中,人们首先定义出组成一篇文档(可以是一句话、一段话、一篇文章)的最基本语言单位,即“词素Token”,这样就可以将一篇文档通过单个词素Token的方式表示为联合分布,进而运用链式法则进行分解。
例如统计语言模型中,对于句子w1,w2,...,wn, 计算其序列概率为P(w1,w2,...,wn),根据链式法则可以求得整个句子的概率:
![]()
其中,每个词出现的概率通过统计计算得到:

即第n个词的出现与前面N-1个词相关,整句的概率就是各个词出现概率的乘积。
关于NLP问题抽象化建模的其他讨论,可以参阅另一篇文章。
3. 互信息的链式法则
在联合熵的基础上,互信息同样可以定义链式法则。
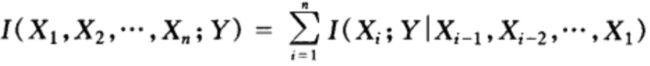
证明过程如下:
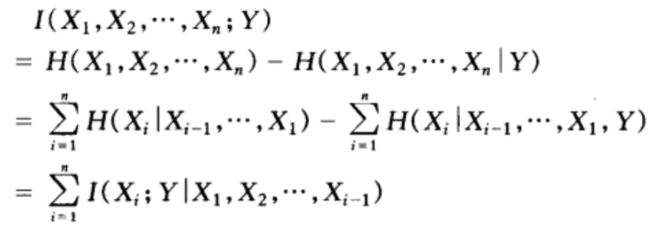
4. 相对熵的链式法则
![]()
证明过程如下:

一对随机变量的两个联合分布之间的相对熵可以展开为相对熵和条件相对熵之和。相对熵的这种链式法则可以用来证明热力学第二定律。
Relevant Link:
《信息论基础》阮吉寿著 - 第二章
3. 基于Jensen不等式得到熵的一些定理推论
0x1:Jensen不等式及其结果
Jensen不等式是凸函数的一个很重要的性质,而凸函数是凸优化里一个很重要的关键概念,在实际工程中,略带夸张的说,如果能将问题抽象建模为一个凸函数,则问题可能已经解决了一半。
1. Jensen不等式泛化定义
下面来看Jensen不等式的定义,若对于任意的![]() 及
及![]() ,满足下式:
,满足下式:
![]()
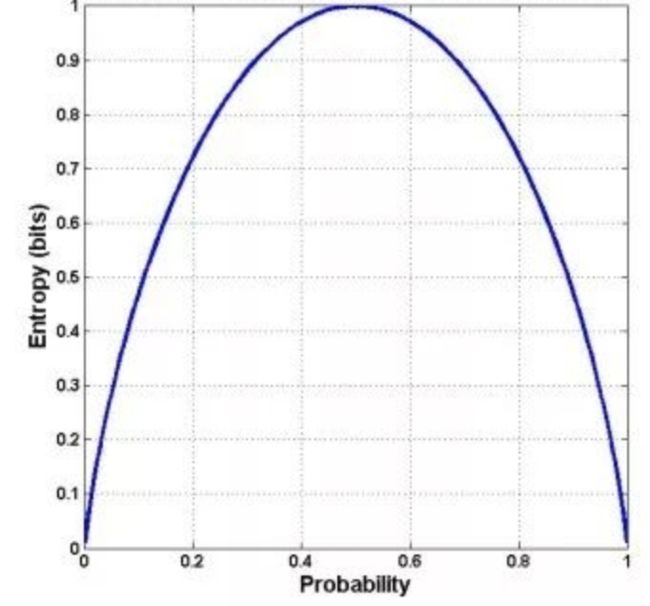
则称函数f(x)在区间(a,b)上是凸的(convex)。如果当且仅当λ=0或λ=1时,上式成立,则称函数f是严格凸的(strictly convex)。
从函数图像直观地看,如果函数总是位于任何一条弦的下面,则该函数是凸的。如下图:

凸函数的例子有很多,例如![]() 。
。
注意到线性函数ax+b既是凸的也是凹的。凸性已经成为许多信息理论量的基本性质的基础。
2. 凸函数的性质
这小节我们来看一下凸函数具备的几个常用性质,也是证明其他定理的常用基础定理。
1)定理1
如果函数f在某个区间上存在非负(正)的二阶导数,则f为该区间的凸函数(严格凸函数)。
2)定理2
若给定凸函数f和一个随机变量X,则
![]()
0x2:基于Jensen不等式得到的信息论不等式定理
1. 信息不等式 - 相对熵恒非负定理
设![]() 为两个概率密度函数,则
为两个概率密度函数,则![]() ,当且仅当对任意的x,p(x) = q(x),等号成立。
,当且仅当对任意的x,p(x) = q(x),等号成立。
证明过程如下:
设![]() 为p(x)的支撑集,则
为p(x)的支撑集,则

上面证明过程用到了Jensen不等式。
信息不等式直观上的理解就是,任意两个概率密度函数之间的距离总是大于等于0的,这也是模型最优化问题的上界。
2. 互信息非负性定理
对任意两个随机变量X和Y,![]() ,当且仅当X与Y相互独立,等号成立。
,当且仅当X与Y相互独立,等号成立。
推论,![]() ,当且仅当给定随机变量Z,X和Y是条件独立的,等号成立。
,当且仅当给定随机变量Z,X和Y是条件独立的,等号成立。
互信息非负性不等式定理的直观理解就是,只有当X和Y具有一定的相关性时,新信息Y的输入,才会降低原随机变量X的熵(不确定性)。反之,如果新信息Y和X完全独立,则无论输入多少Y,也无法降低X的熵。
这对我们在机器学习训练的工程实践中具有很好的指导意义,我们的特征工程和训练样本一定要追求有相关度,对训练目标没有帮助的样本,即使输入的再多,对最终的效果也是没有任何帮助的,这就是所谓的”garbage in,garbage out“。
3. 最大熵定理
![]() ,其中
,其中![]() 表示X的字母表X中元素的个数,当且仅当X服从X上的均匀分布,等号成立。
表示X的字母表X中元素的个数,当且仅当X服从X上的均匀分布,等号成立。
字母表X上的均匀分布是X上的最大熵分布。
最大熵原理是统计学习的一般定理,将它应用到分类得到最大熵模型,最大熵模型学习的目标是用最大熵原理选择最好的分类模型。本质上和极大似然估计是一样的,区别在于最大熵模型的优化目标是熵的最大化。
关于最大熵模型的相关讨论,可以参阅另一篇文章。
4. 条件熵恒非负定理
![]()
该式和互信息非负性定理本质是一样的。直观上理解,信息不会有负面影响,最多零影响。即另一个随机变量Y的信息只会降低或不变X的不确定度。
5. 熵的独立界
设X1,X2,....,Xn服从p(x1,x2,....,xn),则
![]() ,当且仅当Xi相互独立,等号成立。
,当且仅当Xi相互独立,等号成立。
证明过程用到了联合熵的链式法则:
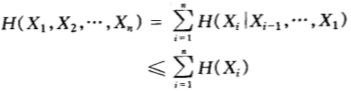
Relevant Link:
《信息论基础》阮吉寿著 - 第二章
0x3:凸函数和机器学习模型优化的关系
凸优化是优化理论中最最重要的一个理论体系了,许多工程中的非凸优化问题,目前最有效的办法也只能是利用凸优化的思路去近似求解。例如:
- 带整数变量的优化问题,松弛之后变成凸优化问题(所以原问题其实是凸优化问题+整数变量)
- 任意带约束的非凸连续优化问题,其对偶问题作为原问题解的一个lower bound,一定是凸的
- 针对带有hidden variable的近似求解maximum likelihood estimate的EM算法,或者贝叶斯统计里的variational Bayes(VB) inference。相比于原本的MLE(本质是非凸优化问题),EM和VB算法都是找到了一个比较好优化的concave lower bound对这个lower bound进行优化
在传统的线性回归问题中,往往可以通过极大似然估计或者矩估计得到一个全局最优解,这本质上因为线性回归的似然函数是凸函数,可以通过对凸函数进行求导得到极值点。凸优化有个非常重要的定理,即任何局部最优解即为全局最优解。所以凸优化的全局最优点很容易得到,不管是导数极值还是梯度下降都可以。
当到了深度神经网络,特别是大规模非线性单元组成的深度神经网络,其对应的似然函数基本不可能是一个凸函数。所以在深度神经网络中,传统的极大似然估计和矩估不能继续使用,从数学上讲本质原因还是计算量过于巨大,大到无法接受的程度。
下图给出了凸优化和非凸优化似然函数的对比。

所以,在复杂深度神经网络中,转而取代的优化算法是SGD、Adam这种局部启发式优化算法。
本质上来说,对于这些非凸优化问题取得的算法理论方面的突破大体其实归结于找到这些非凸优化问题中“凸”的结构,著名的Hessain矩阵描述的就是似然函数在一定范围内的局部表现出的“凸”结构。非凸优化算法的时候其实很多的lemma(引理)仍然是凸优化(凸分析)里的引理或者引申。
Relevant Link:
https://www.jiqizhixin.com/articles/2019-02-25-6
4. 对数和不等式及其应用
0x1:对数和不等式
对于非负数a1,a2,...,an和b1,b2,...,bn。
 ,当且仅当
,当且仅当![]() ,等号成立。
,等号成立。
0x2:基于对数和不等式得到的推论
1. 信息不等式 - 相对熵恒非负定理
利用对数和不等式可以重新证明信息不等式定理,该定理表明![]() ,当且仅当
,当且仅当![]() ,等号成立。证明过程如下:
,等号成立。证明过程如下:

2. 相对熵凸性定理
D(p || q)关于对(p,q)是凸的,即,如果(p1,q1)和(p2,q2)为两对概率密度函数,则对所有的![]() ,有
,有
![]()
3. 熵的凹性
H(p)是关于p的凹函数。熵作为分布的函数时,它具有凹性。
证明过程如下:
![]() ,其中,u为 |X| 个结果的均匀分布。从而H的凹性可由D的凸性直接得到。
,其中,u为 |X| 个结果的均匀分布。从而H的凹性可由D的凸性直接得到。
直观上可以这么理解:均匀分布下混乱度(熵)是最大的,所有随机变量在概率分布上和均匀分布的距离(相对熵)可以理解为一种熵减的过程,从均匀分布对应的最大熵减去相对熵,剩下的混乱度部分就是该随机变量剩余的混乱度(熵)。
Relevant Link:
《信息论基础》阮吉寿著 - 第二章
5. 数据处理不等式及其应用
数据处理不等式可以说明,不存在对数据的优良操作能使从数据中所获得的推理得到改善。
数据处理不等式描述的在一个随机过程序列中,信息是如何通过一个个彼此相邻的节点进行传递的。
0x1:马尔科夫链 - 一种特殊的随机过程
马尔柯夫链是一种特殊的随机过程,信息在马尔柯夫链节点间的传递是无损的。
1. 公式形式化定义
如果Z的条件分布仅依赖于Y的分布,而与X是条件独立的,则称随机变量X,Y,Z依序构成马尔柯夫(Markov)链,记为(X->Y->Z)。
具体说,如果X,Y,Z的联合概率密度函数可以写为:![]() ,则X,Y,Z构成马尔柯夫链X->Y->Z。
,则X,Y,Z构成马尔柯夫链X->Y->Z。
2. 马尔柯夫链的一些性质
1)马尔柯夫链内部外部独立性定理
X->Y->Z,当且仅当在给定Y时,X与Z是条件独立的。马尔科夫性蕴含的条件独立性是因为
![]()
马尔柯夫链的这个特性可以推广到定义n维随机过程的马尔科夫场,它的马尔科夫性为:当给定边界值时,内部和外部相互独立。
2)双向马尔柯夫链定理
X->Y->Z蕴含Z->Y->X,因此,可记为为X<->Y<->Z。
3)马尔柯夫链的函数传递特性
若![]() ,则X->Y->Z。
,则X->Y->Z。
0x2:数据处理不等式 - 任意随机过程序列不增加节点的信息
若X->Y->Z,则有![]() ,证明过程如下:
,证明过程如下:
由链式法则,将互信息以下面两种方式展开:
![]()
由于在给定Y的情况下,X与Z是条件独立的,因此有![]() ,又由于
,又由于![]()
![]() ,所以有:
,所以有:
![]() ,当且仅当
,当且仅当![]() (即X->Y->Z构成马尔柯夫链),等号成立。
(即X->Y->Z构成马尔柯夫链),等号成立。
直观上理解数据处理不等式就是:马尔柯夫链是逐个节点传递信息的,信息只在彼此相邻的节点间传递。马尔柯夫链是一个很好的假设,但是如果随机过程不满足马尔柯夫链,则数据处理不等式告诉我们,随机过程序列也不会增加节点信息,信息只会在节点间逐步递减,至多保持不变(马尔柯夫链就是上界)。
从上面定理我们可以得到一个推论,如果![]() ,则
,则![]() ,X->Y->g(Y)构成马尔柯夫链。
,X->Y->g(Y)构成马尔柯夫链。
这说明Y的函数不会增加X的信息量,而只可能损失关于X的信息量。
Relevant Link:
《信息论基础》阮吉寿著 - 第二章
6. 充分统计量
本节间接地说明利用数据处理不等式可以很好地阐明统计学中的一个重要思,即特征对原始数据的抽象代表性问题。
0x1:充分统计量形式化定义
假定有一族以参数θ指示的概率密度函数{fθ(x)},设X是从其中一个分布抽取的样本。设T(X)为任意一个统计量(样本的概率分布的函数,如样本均值或样本方差),那么θ->X->T(X),且由数据处理不等式可知,对于θ的任何分布,有:
![]() ,若等号成立,则表明无信息损失。
,若等号成立,则表明无信息损失。
如果T(X)包含了X所含的关于θ的全部信息,则称该统计量T(X)关于θ是充分的。
如果对θ的任何分布,在给定T(X)的情况下,X独立于θ(即θ->T(X)->X构成马尔柯夫链),则称函数T(X)是关于分布族{fθ(x)}的充分统计量(sufficient statistic)。
这个定义等价于数据处理不等式中等号成立的条件,即对θ的任意分布,有
![]()
因此充分统计量保持互信息不变,反之亦然。
0x2:充分统计量的例子
这小节我们通过例子来更深入理解充分统计量是如何传递互信息的,即如何对原始数据进行无损的抽象代表的。
如果X服从均值为θ,方差为1的正态分布,即如果
![]()
且X1,X2,...,Xn相互独立地服从该分布,那么样本均值![]() 为关于θ的充分统计量。
为关于θ的充分统计量。
可以验证,在给定![]() 和n的条件下,X1,X2,...,Xn的条件分布不依赖于θ。换句话说,样本均值和样本方差可以无损地传递出原始样本的全部互信息。这就是为什么在传统统计模型中,高斯模型和多元高斯模型可以仅仅用(均值、方差)参数向量就可以完全无损的表征原始样本。
和n的条件下,X1,X2,...,Xn的条件分布不依赖于θ。换句话说,样本均值和样本方差可以无损地传递出原始样本的全部互信息。这就是为什么在传统统计模型中,高斯模型和多元高斯模型可以仅仅用(均值、方差)参数向量就可以完全无损的表征原始样本。
0x3:最小充分统计量
如果统计量T(X)为其他任何充分统计量U的函数,则称T(X)是关于{fθ(x)}的最小充分统计量(minimal sufficient statistic)。通过数据处理不等式解释,此定义蕴含
![]()
因而,最小充分统计量最大程度地压缩了样本中关于θ的信息,而其他充分统计量可能会含有额外的不相关信息。
例如,对于均值为θ的一个正态分布,取奇数样本的均值和取偶数样本的均值所构成的函数对是一个充分统计量,但不是最小充分统计量,而只有使用了全量典型集训练得到的统计量才是一个充分统计量。
0x3:从充分统计量角度看机器学习中特征工程
特征工程可能我们大家都非常熟悉,几乎在所有项目中,不管是使用传统机器学习模型还是深度学习模型,最初始也是最关键的一个环节就是特征工程。
基本上来说,衡量特征工程好坏的标准就是特征函数T(X)和原始数据分布X之间的互信息,互信息越高,说明该特征工程方案效果越好。
另一方面,特征的信息损失可以用相对熵来衡量,相对熵越大,则说明特征函数和原始数据分布X之间的相关性就越差。
Relevant Link:
《信息论基础》阮吉寿著 - 第二章
7. 费诺不等式及其引理
假定知道随机变量Y,想进一步推测与之相关的随机变量X的值。费诺不等式将推测随机变量X的误差概率,与它的条件熵 H(X|Y) 联系在一起。
给定另一个随机变量Y,当且仅当X是Y的函数,随机变量X的条件熵0(H(X|Y)=0),即可以通过Y直接估计X(即满足函数映射关系),其误差概率为0。费诺不等式也可以用来解释随机变量之间的函数关系和相关关系,关于这部分话题的讨论,可以参阅另一篇文章。
我们暂时抛开随机变量之间相关性这个视角,将思维回到信息论的领域来。考虑两个随机变量之间的互相推测/推导关系,我们希望仅当条件熵 H(X|Y) 较小时,能以较低的误差概率估计X,费诺不等式量化这个误差的上界。
0x1:费诺不等式形式化定义
假定要估计随机变量X具有分布p(x),我们观察与X相关的随机变量Y,相应的条件分布为p(y|x),通过Y计算函数![]() ,其中
,其中![]() 是对X的估计(即统计量),我们并不要求
是对X的估计(即统计量),我们并不要求![]() 与X必须相同,也允许函数g(Y)是随机的,对
与X必须相同,也允许函数g(Y)是随机的,对![]() 的概率作一个界。
的概率作一个界。
注意到![]() 构成马尔柯夫链,定义误差概率为:
构成马尔柯夫链,定义误差概率为:
![]()
一般地,对任何满足![]() 的估计量
的估计量![]() ,设
,设![]() ,有
,有
![]()
上面不等式可减弱为:
![]() ,或
,或![]()
很显然,![]() 可推出
可推出![]()
进一步得到泛化推论,对任意两个随机变量X和Y,设![]() ,有
,有
![]()
0x2:随机变量误差概率下界定理
基于费诺不等式,可以得到一个体现误差概率与熵之间关系的不等式,设X和X'是两个独立同分布的随机变量,有相同的熵H(X),那么X=X'的概率为:
![]()
由此得到下面的引理:
如果X和X'独立同分布,具有熵H(X),则:
![]() ,当且仅当X服从均匀分布,等号成立。
,当且仅当X服从均匀分布,等号成立。
Relevant Link:
《信息论基础》阮吉寿著 - 第二章
8. 渐进均分性
0x1:典型集
在信息论中,与大数定律类似的是渐进均分性(AEP),它是弱大数定律的直接结果。而典型集本身就是AEP成立的基本条件,这节我们先来讨论典型集,由此引出AEP的讨论。
大数定律针对独立同分布(i.i.d)随机变量,当n很大时,![]() 近似于期望值EX。而渐进均分性表明
近似于期望值EX。而渐进均分性表明![]() 近似于熵H,其中X1,X2,...,Xn为i.i.d.随机变量。p(X1,X2,...,Xn)是观察序列X1,X2,...,Xn出现的概率。
近似于熵H,其中X1,X2,...,Xn为i.i.d.随机变量。p(X1,X2,...,Xn)是观察序列X1,X2,...,Xn出现的概率。
因而,当n很大时,一个观察序列出现的概率p(X1,X2,...,Xn)近似等于2-nH。
举一个虚构的例子,设随机变量![]() 的概率密度函数为p(1)=p,p(0)=q。若X1,X2,...,Xn为i.i.d.,且服从p(x),则序列(x1,x2,...,xn)出现的概率为
的概率密度函数为p(1)=p,p(0)=q。若X1,X2,...,Xn为i.i.d.,且服从p(x),则序列(x1,x2,...,xn)出现的概率为![]() 。比如,序列(1,0,1,1,0,1)出现的概率是
。比如,序列(1,0,1,1,0,1)出现的概率是![]() 。很显然,并非所有长度为n的2n个序列都具有相同的出现概率。
。很显然,并非所有长度为n的2n个序列都具有相同的出现概率。
不同序列出现概率不同的这件事,促使我们将全体序列组成的集合划分为两个子集:
- 第一是典型集:其中样本熵近似于真实熵
- 第二是非典型集:包含其余的序列
在实际工程项目和学术研究中,我们主要关注典型集,这是因为人和基于典型序列的性质都是高概率成立的,并且决定着大样本的平均行为。
那接下来的问题是,所有长度为n的2n个序列出现的概率是如何分布的呢?典型集又是如何占据了绝大多数概率分布呢?
假定有一个二项分布随机试验,N=1000,p(T)=0.1,即T出现的该概率是0.1。
易得该二项分布的均值为Np=100,方差为Np(1-p),通过分位表我们知道,T发生的次数以100为中心,在3个标准差内概率近似接近1
于是,我们得出下列结论:
一般地,若p(T)=p,则N长序列中,T出现次数以接近概率1落在区间![]()
![]() ,且在N足够大时,T出现的次数几乎等于Np次。
,且在N足够大时,T出现的次数几乎等于Np次。
从这个结论出发,我们可以将最大概率区间(3标准差估计区间)内出现的序列称之为typical set(典型序列集合)。
上述讨论方式涉及数理统计中的概率分布理论,相关讨论可以参阅这篇文章。现在我们从信息论熵的视角重新来看待这个问题。
不同观测结果X1,X2,...,Xn,对应着不同的出现概率p(X1,X2,...,Xn),而p(X1,X2,...,Xn)将以高的概率接近于2-nH,即概率与熵一一对应。
对于,概括为“几乎一切事物都令人同等的意外”。换言之,当X1,X2,...,Xn为i.i.d.~p(x),则
![]()
下面用概率论中的收敛概念,其定义如下:
给定一个随机变量X1,X2,...,Xn。序列收敛于随机变量X有如下3种情形:
- 如果对任意的
 ,则称为依概率收敛
,则称为依概率收敛 - 如果
 ,则称为均方收敛
,则称为均方收敛 - 如果
 ,则称为以概率1(或称几乎处处)收敛
,则称为以概率1(或称几乎处处)收敛
0x2:渐进均分性定理(AEP)
若X1,X2,...,Xn为i.i.d.~p(x),则![]() 依概率收敛。
依概率收敛。
AEP定理表明,对于一个分布 假设,按此概率,取n次,则形成一个序列,这个序列出现的概率的对数除以n,会趋近于 的熵,且n越大,越趋近于 。
由此得到一个推论:
关于p(x)的典型集![]() (typical set)是序列
(typical set)是序列![]() 的集合,且满足性质:
的集合,且满足性质:
![]()
该推论表明,选取一个典型集合,这个集合并不要求其对数除n等于,而是允许有一个微小的误差 ,且序列越长时, 可以越小。
作为渐进均分性的一个推论,可以证明典型集![]() 有如下性质:
有如下性质:
- 如果
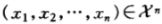 ,则
,则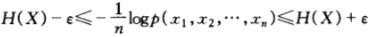
- 当n充分大时,
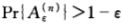
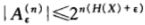 ,其中 |A| 表示集合A中的元素个数
,其中 |A| 表示集合A中的元素个数- 当n充分大时,

由此可见,典型集的概率近似为1,典型集中所有元素几乎是等可能的,且典型集的元素个数近似等于2nH。
0x3:AEP的推论:数据压缩
设X1,X2,...,Xn服从概率密度函数p(x)的i.i.d.随机变量。为了获取这些随机变量序列的简短描述,将Xn中的所有序列划分为两个集合:典型集,及其补集。如下图所示:
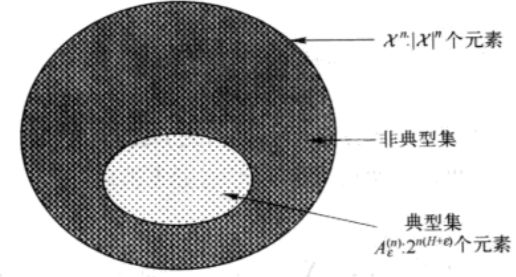
将每个集合中的所有元素按照某种顺序(例如字典顺序)排列,然后给集合中的序列指定下标,表示![]() 中的每个序列。由于
中的每个序列。由于![]() 中的序列个数<=2n(H+ε),则这些下标不超过n(H+ε)+1比特(额外多处的1比特是由于可能不是整数)。
中的序列个数<=2n(H+ε),则这些下标不超过n(H+ε)+1比特(额外多处的1比特是由于可能不是整数)。
在所有这些序列的前面加0,表示![]() 中的每个序列需要的总长度<=n(H+ε)+2比特。
中的每个序列需要的总长度<=n(H+ε)+2比特。
类似地,对不属于![]() 的每个序列给出下标,所需的位数不超过nlog|X|+1比特,再在这些序列前面加1,就获得关于Xn中所有序列的一个编码方案。
的每个序列给出下标,所需的位数不超过nlog|X|+1比特,再在这些序列前面加1,就获得关于Xn中所有序列的一个编码方案。
如下图所示:
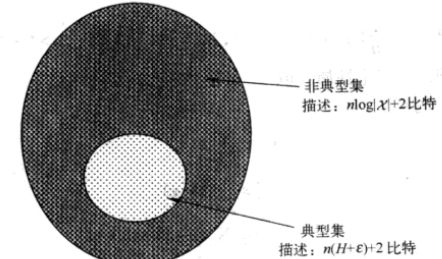
上述编码方案有如下特征:
- 编码是1-1的,且易于译码,起始位作为标志位,标明紧随码字的长度
- 典型序列具有较短的描述长度

用xn表示序列x1,x2,....,xn,设![]() 表示相应于xn的码字长度。若n充分大,使得
表示相应于xn的码字长度。若n充分大,使得![]() ,于是,码字长度的数学期望为:
,于是,码字长度的数学期望为:

其中![]() ,适当选取ε和n时,ε’可以任意小。
,适当选取ε和n时,ε’可以任意小。
基于上面讨论,我们已经证明了下序列序列编码长度期望定理。
设Xn为服从p(x)的i.i.d.序列,ε>0,则存在一个编码将长度为n的序列Xn映射为比特串,使得映射是1-1的(因为可逆/可解码),且对于充分大的n,有
![]()
因而从平均意义上,用nH(X)比特可表示序列Xn。
0x4:高概率与典型集
由![]() 的定义知道,
的定义知道,![]() 是包含大多数概率的小集合。但从定义看,并不确定是否是这类集合中的最小集。下面来证明典型集在一阶指数意义下与最小集有相同的元素个数。
是包含大多数概率的小集合。但从定义看,并不确定是否是这类集合中的最小集。下面来证明典型集在一阶指数意义下与最小集有相同的元素个数。
对每个n=1,2,....,设![]() 为满足如下条件的最小集,即
为满足如下条件的最小集,即
![]()
下面证明![]() 与
与![]() 的交集充分大,使其含有足够多的元素。
的交集充分大,使其含有足够多的元素。
设X1,X2,...,Xn为服从p(x)的i.i.d.序列,对![]() 及任意的
及任意的![]() ,如果
,如果![]() ,则
,则
![]() ,该定理即为典型集和最小集近似相等定理。
,该定理即为典型集和最小集近似相等定理。
因此在一阶指数意义下,![]() 至少含有2nH个元素,而
至少含有2nH个元素,而![]() 大约有2n(H+-ε)个元素。所以,
大约有2n(H+-ε)个元素。所以,![]() 的大小差不多与最小的高概率集是相同的。
的大小差不多与最小的高概率集是相同的。
考虑一个伯努利序列X1,X2,...,Xn,其参数p=0.9,此时,典型序列中1所占的比例近似等于0.9。然而,这并不包括很可能出现的全部是1的序列,因为显然,全为1的序列出现是一个小概率事件。
集合![]() 包括所有很可能出现的序列,因而包括全部为1的序列。
包括所有很可能出现的序列,因而包括全部为1的序列。
典型集和最小集近似相等定理表明![]() 与
与![]() 必定包含了所有1所占比例90%的序列,且两者的元素数量几乎相等。
必定包含了所有1所占比例90%的序列,且两者的元素数量几乎相等。
0x5:AEP和典型集对工程的指导意义
从对典型集的讨论中,我们很明显地看到了”长尾效应“的影子,即当提升某件事可以另一件事的效能时,持续不断提升下去,会在某个点达到一个收敛平衡界,超出收敛平衡界之后,继续投入更多的资源也不能带来更多的线性增长。
在实际的工程项目中,不要过分地追求海量数据,例如你做恶意文件文本检测,使用20w数量级的样本已经可以取得良好效果,这个时候,没有必要继续提高到200w数量级,因为很可能20w就已经在一定的误差ε下达到典型集了,继续增加样本对整体信息量的贡献并不明显,相反还带来成倍的计算和训练开销。
参考Andrew Gelman的一句名言:样本从来都不是足够大的。如果 N 太大不足以进行足够精确的估计,你需要获得更多的数据。但当 N “足够大”,你可以开始通过划分数据研究更多的问题,例如在民意调查中,当你已经对全国的民意有了较好的估计,你可以开始分性别、地域、年龄进行更多的统计。N 从来都无法做到足够大,因为当它一旦大了,你总是可以开始研究下一个问题从而需要更多的数据。
Relevant Link:
《信息论基础》阮吉寿著 - 第三章 https://zhuanlan.zhihu.com/p/33668137