本文面向的读者是对java熟悉,并对volatile有一定的了解的java programer。(volatile简介:https://www.ibm.com/developerworks/cn/java/j-jtp06197.html 建议先看前几段了解下即可。不看happens-before等java理论) 市面上对该关键字的解读,包括《并发编程的艺术》中都对最底层的部分含糊不清,我相信作者是非常了解所有问题的,但是并没有给出一个确定、明了的答案。本文便是对此进行讲解。
我们先抛开volatile不谈,来看看计算机的存储结构(也可以叫做存储架构,架构吹起来比较NB)。在原本的设想中,我们认为cpu是集算术计算(加减乘除)、逻辑计算(与、或、异或等)、移位功能(左移右移)等运算功能以及读、写等控制功能于一身的部件,而存储器就是存放指令、数据的部件,二者分工就可以天下太平。但是在实际情况下,cpu的频率越来越高(由时钟同步器决定),也就是说处理速度越来越快。如3.8GHz表示时钟的变化频率为每秒 3.8 * 10^9 = 38亿次,即每次计算只用1/3.8 = 0.26ns,这还只是单核,如果是四核,则cpu处理速度最快可达0.07ns。参考下图,其中cpu部分的300ps(皮秒) = 0.3ns(纳秒),这个速度是指CPU内部寄存器的速度,仍然要比累加器更慢,但因为每条指令至少需要PC寄存器的参与,所以可以视为CPU速度为0.3ns。相比50-100ns级的主存速度,甚至是毫秒级的硬盘,cpu的处理耗时就仿佛是时间暂停了一般,概率论千分之一即为小概率事件可忽略,类比过来,cpu的处理速度是主存的数百倍,而与L1 Cache可以缩小至几倍差距。
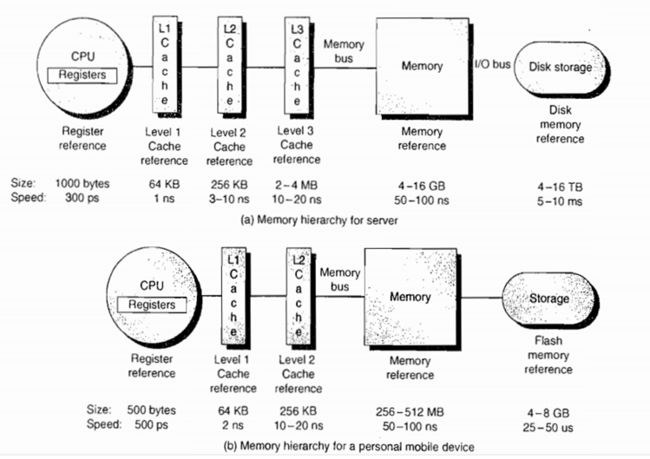
cpu与主存速度的不匹配已经是天堑鸿沟,而大量的指令是含操作数的(如a + b,其中一定包含对a和b的读取指令),也就需要访存,cpu将会有大量时间耗费在等待存取周期(即读写周期)上。那cpu不能在等待期间做别的吗?答案是不可以。指令具有原子性,cpu必须完成整个指令以后才能处理下一条,至于为啥要原子性,感兴趣的同学可以自行搜索下原子性(此处以a + b为例,其中包含对a,b读取的指令,如果指令没有原子性,那么当a已经读出暂存在寄存器中,cpu继续读b,指令刚发出还未等b存入寄存器就开始求和,我们将得到 a + b = a的错误结果)。我们看到了cpu与主存间不可避免的等待矛盾(马克思说这是对抗性矛盾,是无法消除的),因此只能加快访存速度。综合集成化(器材大小,集成度越高,芯片就可以越小,性能越高)、单位价格(每Byte要多少软妹币)、访存速度、功耗等等(其实基本就看价钱和速度),我们采取了三级存储结构:cache(高速寄存器,SRAM——静态随机存储器) - 主存(内存,DRAM——动态随机存储器),主存 - 辅存(硬盘、光盘等)。其中CPU可以直接访问cache和主存,而CPU与cache(先在cache也分三级,L1-L2-L3,L1最快,容量最小,价钱最高)的速度差距可以缩小到10倍以内,主存与辅存差距在100倍以上。分级存储结构得目的是:让访存速度有L1 cache的超高速度,让存储空间有硬盘的大小。
上面的内容告诉了我们,为什么我们不得不分存储结构(还是因为没钱惹的祸,如果我年少有为又有钱,搞1TB cache在电脑里……)。主存-辅存这级和OS的虚拟存储以及数据库相关,我们此处仅讨论随时伴随程序运行的cache-主存。
访存分读(取)和写(存)两个类型,我们要做的事情就是让cpu的读写都尽量仅针对cache,避免与主存交互。在讨论具体的读写操作之前,我们要知道计算机中的局部性原理——即将要用到的信息很可能是正在使用的信息,因为程序存在循环(时间局部性);即将要用到的信息很可能存放在现在在用信息的邻近存储单元,因为程序通常是连续存放的(空间局部性) 基于这一原理,我们将主存和cache按同等大小分块,每次cache与主存同步就按块为最小单位进行刷新,就可以大幅提高命中率(可了解下 cache和主存的映射方式,知道cache命中判断,此处不做赘述)。CPU读取的时候只要访问cache,数据命中则认为读取成功,如果未命中,再到主存读取,并且将该数据所在块刷入cache中。而CPU写的时候也是直接写入cache(主存写入比读取更费时),然后再按策略写入主存,如全写法、写回法、写分配法、非写分配法。以下对此展开讲解,这也是volatile要解决的关键问题所在。
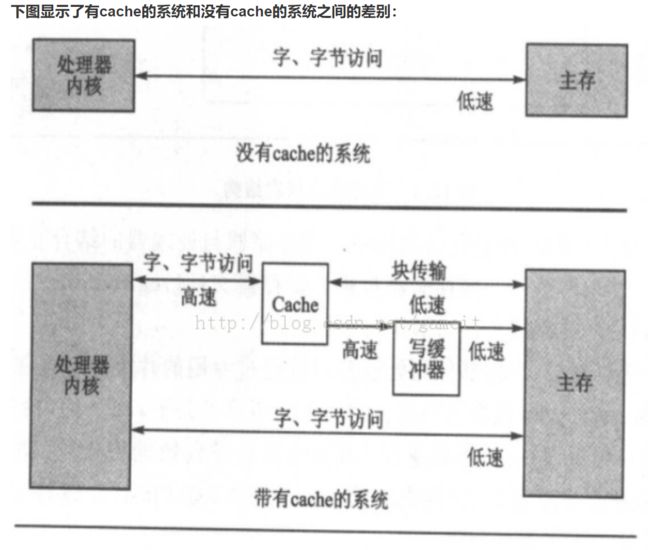
全写法:当写命中时(要写入的数据所在块已经加载在cache中),CPU直接将新的数据同时写入cache和主存,这样的话写入速度就等于主存的写速度了,这完全就是博尔特在陪我这种运动弱将散步,失去了cache的意义。因此全写法通常会配合一个WB(Write Buffer,写缓冲器)同时写入cache和写缓冲。
(其余cache写策略待补,请读者先自查 写回法,另外两种算法是cache写不命中时采用的,影响不大)
ARM架构的cache :https://www.reader8.cn/jiaocheng/20131028/2083384.html
这样使得cpu不用再关心主存的写入,只需要等待cache和buffer的写入时间,而主存则交由缓冲器自行写入。由于缓冲器的存在,在单核情况下全写法无与伦比的优势变得不再可靠:一致性——保证cache与主存的数据一致。由于CPU是先读cache,命中失败才去读主存;写操作也是直接修改cache中的块,只有块未载入cache时才写入主存。因此单核场景中,CPU读到的数据一定是正确的。然而到了多核场景就不一样了。cache以及写缓冲器都是在处理器内部的,因此多核就会有多个写缓冲器,而多核共用一个主存,就会产生两个CPU同时写入同一个主存单元得情况。当CPU1写入数据以后,缓冲器刷入内存以前,CPU2读取该地址的存储单元,将会读到过时的数据。
举例:李雷和韩梅梅约我当bulb,吃饭竟然还让我买单,一气之下我和他们闹绝交,然后这对给我撒了十几年狗粮的神仙眷侣决定还钱。很倒霉的是他们都从X宝同时给我转账(这个时候的X宝刚刚起步,还存在一些并发bug),我本来账户里面还有1000w,李雷、韩梅梅各转给我100块饭钱,X宝为了体现高逼格的并发编程技术,决定用两个线程来处理这两笔转账。倒霉催的是这两个线程又刚好分配在两个CPU同时进行(由此可见,并发问题发生的条件是多么的苛刻。如果其中一个CPU正被其他线程占用,则不会发生我所描述的问题),在完成从他们俩账户扣款,并要给我的账户增加余额的时候:CPU李和CPU韩读了我的余额1000w到他们的cache中,主存君还在泡着茶翘着二郎腿,嘴角微笑,又办妥两件事“我真牛*!”殊不知这两个CPU背后正干着坑我软妹币的勾当!CPU李及CPU韩都看到了这个时候我的账户还剩1000w,于是把自己那份钱钱还上后,他们都以为我的余额应该是1000.01w了。然后他们再委托别人(write buffer)告诉主存君,我现在余额是1000.01w,主存君看到两个1000.01w的余额也没思考(当然,主存没脑子,大脑是CPU),就把我的余额记成1000.01w了。然而我明明应该是1000.02w的,就这样活活被两个CPU+没脑的主存给坑了100块大洋。
上例就是volatile所要解决的并发问题。关于它的博客文章有很多,感兴趣的读者可以自行搜索。此处提炼下各大畅销书和写得不错的博客:volatile通过jvm的指令,调用操作系统中控制cpu缓存策略的指令(即 program -> jvm -> os -> cpu),使得受volatile保护的存储块在修改时,立即写入主存;并且在写入期间其余CPU cache缓存的该存储块失效,需要重新从主存读取。也就是很多博客中讲半天没讲明白的缓存失效。有很多博客围绕汇编指令讲了一堆,篇幅巨大且云里雾里,都是因为无视了处理器架构,不知道那些Lock指令作用在什么地方,为什么非要这样(因为cache写命中最通用的两种写策略,全写法和写回法在多核场景下必然会导致前例的并发问题。而不采用cache则是不可接受原因则是成千上万倍的cpu-访存速度差距,完全无法接受)。
上述有点像:使写不命中,并采用非写分配法(这句话看不懂的话就不管了吧。。这是在前面提炼部分上的一个类比而已)。可以看到,大量使用volatile会导致cpu的写速度回到主存级别,且其使用的方式也较为考究,因而成了一个许多人视而不见,见而不明的问题。
ps:许多书和博客里提到的cpu资源,就是cpu的时间。因为绝大多数指令都是带操作数指令,因此cpu多数时间用在了等待上。等待寄存器是最轻的了,等待主存已经很难接受,如果是等待硬盘,则用户都会感受到明显且痛苦的等待时常。至于I/O...对于CPU来说,大概就是永恒的等待了吧。另外,存储资源也就是存储空间。其实存储问题不仅仅有字长而已,还有如双端芯片的端口资源等。用“资源”两个字概括了不同类型部件的不同问题,只会让问题变得更加模糊,无法帮助读者简化和洞悉问题,应清楚认识到到底是在消耗什么“资源”,尽量不要笼统而过。