作者:林冠宏 / 指尖下的幽灵
掘金:https://juejin.im/user/587f0dfe128fe100570ce2d8
博客:http://www.cnblogs.com/linguanh/
GitHub : https://github.com/af913337456/
腾讯云专栏: https://cloud.tencent.com/developer/user/1148436/activities
关于
server.go源码的解析可以去搜下,已经有很多且还不错的文章。
正文:
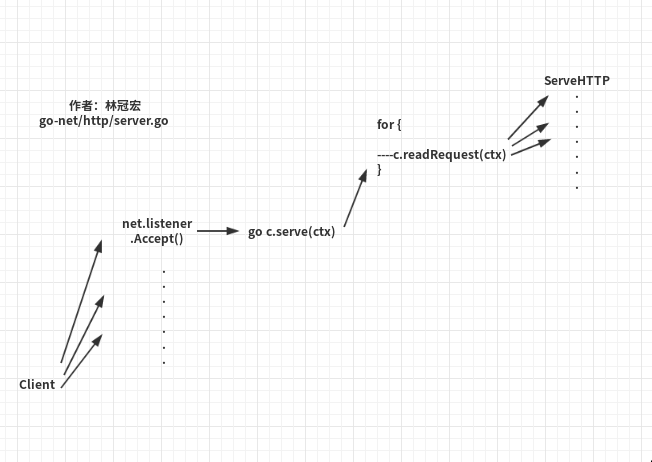
从我们启动http.ListenAndServe(port,router)开始,server.go 内部最终在一个for 循环中的 accept 方法中不停地等待客户端的连接到来。
每接收到一个accept 就启动一个 gorutine 去处理当前ip的连接。也就是源码里的go c.serve(ctx)。这一个步骤在 c.serve(ctx) 它并不是简单的形式:
请求-->处理请求-->返回结果-->断开这个连接-->结束当前的 gorutine
根据我的调试结果与源码分析显示,正确的形式是下面这样的:
为每一个连接的用户启动了一个长连接,
serve方法内部有个超时的设置是c.rwc.SetReadDeadline(time.Time{}),这样子的情况,如果内部不出错,当前的连接断开的条件是客户端自己断开,或nat超时。这个连接建立后,以
ip为单位,当前的客户端,此时它的所有http请求,例如get,post,它们都会在这个启动的gorutine内进行分发与被处理。也就是说,同一个
ip,多个不同的请求,这里不会触发另一个accept,不会再去启动一个go c.serve(ctx)
上述我们得出结论:
如果有
100万个accept,就证明有100万个连接,100万个ip与当前server连接。即是我们说的百万连接百万连接不是百万请求每一个连接,它可以进行多个
http请求,它的请求都在当前启动这个连接的gorutine里面进行。c.serve(...)源码中的for 死循环就是负责读取每个请求再分发
for {
w, err := c.readRequest(ctx) // 读取一个 http 请求
//...
ServeHTTP(...)
}- 我们的
100万连接里面,有可能并发更多的请求,例如几百万请求,一个客户端快速调用多个请求api
图解总结

结合 master-worker 并发模式
根据我们上面的分析,每一个新连接到来,go 就会启动一个 gorutine,在源码里面也没有看到有一个量级的限制,也就是达到多少连接就不再接收。我们也知道,服务器是有处理瓶颈的。
所以,在这里插播一个优化点,就是在server.go 内部做一个连接数目的限制。
master-worker 模式本身是启动多个worker 线程,去并发读取有界队列里面的任务,并执行。
我自身已经实现了一个go版本的master-worker,做过下面的尝试:
- 在
go c.serve(ctx)处做修改,如下。
if srv.masterWorkerModel {
// lgh --- way to execute
PoolMaster.AddJob(
masterworker.Job{
Tag:" http server ",
Handler: func() {
c.serve(ctx)
fmt.Println("finish job") // 这一句在当前 ip 断开连接后才会输出
},
})
}else{
go c.serve(ctx)
}
func (m Master) AddJob(job Job) {
fmt.Println("add a job ")
m.JobQueue <- job // jobQueue 是具备缓冲的
}
// worker
func (w Worker) startWork(master *Master) {
go func() {
for {
select {
case job := <-master.JobQueue:
job.doJob(master)
}
}
}()
}// job
func (j Job) doJob(master *Master) {
go func() {
fmt.Println(j.Tag+" --- doing job...")
j.Handler()
}()
}不难理解它的模式。
现在我们使用生产者--消费者模式进行假设,连接的产生是生产者,<-master.JobQueue 是消费者,因为每一次消费就是启动一个处理的gorutine。
因为我们在accept 一个请求到<-master.JobQueue,管道输出一个的这个过程中,可以说是没有耗时操作的,这个job,它很快就被输出了管道。也就是说,消费很快,那么实际的生产环境中,我们的worker工作协程启动5~10个就有余了。
考虑如果出现了消费跟不上的情况,那么多出来的job将会被缓冲到channel里面。这种情况可能出现的情景是:
短时间十万+级别连接的建立,就会导致
worker读取不过来。不过,即使发生了,也是很快就取完的。因为间中的耗时几乎可以忽略不计!
也就说,短时间大量连接的建立,它的瓶颈在队列的缓冲数。但是即使瓶颈发生了,它又能很快被分发处理掉。所以说:
-
我的这个第一点的尝试的意义事实上没有多大的。只不过是换了一种方式去分发
go c.serve(ctx)。
- 这个是第二种结合方式,把
master-worker放置到ServeHTTP的分发阶段。例如下面代码,是常见的http handler写法,我们就可以嵌套进去。
func (x XHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
//...
if x.MasterWorker {
poolMaster.AddJob(master_worker.Job{
Tag:"normal",
XContext:xc,
Handler: func(context model.XContext) {
x.HandleFunc(w,r)
},
})
return
}
x.HandleFunc(w,r)
//...
}这样的话,我们就能控制所有连接的并发请求最大数。超出的将会进行排队,等待被执行,而不会因为短时间 http 请求数目不受控暴增 而导致服务器挂掉。
此外上述第二种还存在一个:读,过早关闭问题,这个留给读者尝试解决。