整个Flink的Job启动是通过在Driver端通过用户的Envirement的execute()方法将用户的算子转化成StreamGraph
然后得到JobGraph通过远程RPC将这个JobGraph提交到JobManager对应的接口
JobManager转化成executionGraph.deploy(),然后生成TDD发给TaskManager,然后整个Job就启动起来了
这里来看一下Driver端的实现从用户的Envirement.execute()方法作为入口
这里的Envirement分为
RemoteStreamEnvironment
LocalStreamEnvironment
因为local模式比较简单这里就不展开了,主要是看下RemoteStreamEnvironment的execute方法

可以看到这里先获取到了streamGraph,具体获取的实现

这里传入了一个transformations其中就包含了我们用户的所有operator
![]()
这个地方就是遍历了用户端所有的operator生成StreamGraph,遍历的每一个算子具体转化成streamGraph的逻辑
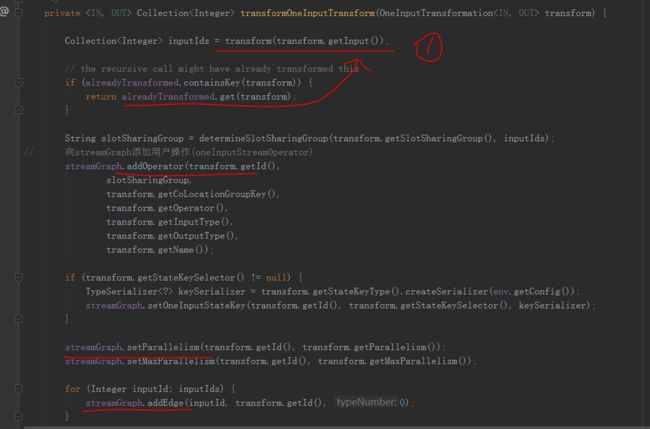
1处会递归遍历input直到input已经transfor,然后拿到了上游的ids
然后将operator加入到了streamGraph中调用addNode()方法将operator作为一个node,包含了一些信息,上下游的类型,并行度,soltGroup
最后遍历上游的ids,创建边添加到streamGraph
到这里streamGraph就创建完成了
回到最开始的地方,创建完streamGraph以后,会将streamGraph传入executeRemotely(streamGraph, jarFiles)这个方法,这里就是streamGraph转化成jobgraph的逻辑
其中创建了一个RestClusterClient

![]()
可以看到这里,通过getJobGraph方法将streamGraph转换成了jobgraph
然后就submitJob将这个JobGraph提交Jobmanager了
先看一下streamGraph如何转化成jobgraph的

通过getJobGraph方法然后
![]()

这个createJobGraph方法是主要的转化逻辑

广度优先遍历为所有streamGraph的node 即operator生成hash散列值,为什么要生成这个operator的hash?
因为这个hash需要作为每一个operator的唯一标示,标示每一个operator用于cp的恢复,当用户代码没有修改时,这个hash值是不会改变的
接下来


这里会将flink中上下游的operator操作根据是否满足chain条件链在一起,在createChian中
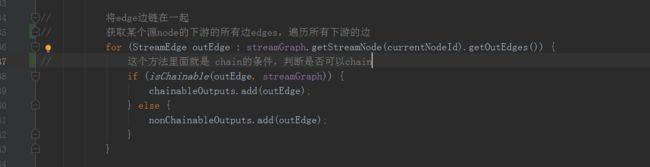
这个isChainable()方法就是是否可以chain的判断条件

1.下游的输入边只有一条
2.下游操作operator不为空
3.上游操作operator不为空
4.上游必须有相同的solt组
5.下游chain策略为always
6.上游chain策略为head或上游chain策略为always
7.forwardpartition的边
8.上下游并行度相同
9.用户代码设置的operator是否可以chian
将可以chain的streamnode 链在一起以后就可以创建成为jobGraph的jobVertex了
然后通过RestClusterClient会将这个jobGraph往jobmanager的Dispatcher对应的RPC接口上面发送
整个job的启动Driver端的任务就结束了
总结:
在Driver端用户的算子会被创建成为streamGraph,其中包含了一些边,角,上下游类型,并行度等一些信息
然后将streamGraph通过一些chain条件将可以chain的顶点chain在了一起转化成了JobGraph
streamEdge变成了jobEdge,chain在一起的streamnode变成了jobVertex
最后然后通过RPC将整个jobGraph向jobmanager提交。