JAVA.SQL.SQLEXCEPTION: INCORRECT STRING VALUE: '\XF0\X9F\X92\X94' FOR COLUMN 'CONTENT' AT ROW 1
标签: Mysql存储表情 Mysql支持Emoji java.sql.SQLException '\xF0\x9F\x92\x94' for column
使用Mysql服务器的utf8字符编码,在存入移动端emoji表情时会报异常:
-
Caused by: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\x84' for column 'content' at row 1 -
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1074) -
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4096) -
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4028) -
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2490) -
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2651) -
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2734) -
at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:2155) -
at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:2458)
原因:mysql的utf8编码的一个字符最多3个字节,但是一个emoji表情为4个字节,所以utf8不支持存储emoji表情,导致报错.
解决办法:
一.服务器端转换数据库存储编码
数据库目前采用的编码为UTF8, 转换为可支持4个字节的utf8mb4_unicode编码。
如图所示:

利:客户端存储和请求数据的时候不需要都去做转换
弊:1)转换编码格式可能会导致现有数据库的数据发生乱码;
2)转换编码格式之后,可能对后续的全文搜索功能有影响,大多数中文搜索引擎支持的编码格式为UTF-8;
3)若Android端的编码与数据库转换后的编码不符,将对Android端产生同样的问题。
二.客户端转换编码
客户端输入内容时候,统一存储为服务端数据库支持的编码;客户端请求内容的时候,需要根据客户端支持的编码对请求到的数据进行相应的转换
如代码所示:
-
public class EmojiConverterUtil { -
/** -
* @Description 将字符串中的emoji表情转换成可以在utf-8字符集数据库中保存的格式(表情占4个字节,需要utf8mb4字符集) -
* @param str -
* 待转换字符串 -
* @return 转换后字符串 -
* @throws UnsupportedEncodingException -
* exception -
*/ -
public static String emojiConvert1(String str) -
{ -
String patternString = "([\\x{10000}-\\x{10ffff}\ud800-\udfff])"; -
Pattern pattern = Pattern.compile(patternString); -
Matcher matcher = pattern.matcher(str); -
StringBuffer sb = new StringBuffer(); -
while(matcher.find()) { -
try { -
matcher.appendReplacement( -
sb, -
"[[" -
+ URLEncoder.encode(matcher.group(1), -
"UTF-8") + "]]"); -
} catch(UnsupportedEncodingException e) { -
} -
} -
matcher.appendTail(sb); -
return sb.toString(); -
} -
/** -
* @Description 还原utf8数据库中保存的含转换后emoji表情的字符串 -
* @param str -
* 转换后的字符串 -
* @return 转换前的字符串 -
* exception -
*/ -
public static String emojiRecovery2(String str){ -
String patternString = "\\[\\[(.*?)\\]\\]"; -
Pattern pattern = Pattern.compile(patternString); -
Matcher matcher = pattern.matcher(str); -
StringBuffer sb = new StringBuffer(); -
while(matcher.find()) { -
try { -
matcher.appendReplacement(sb, -
URLDecoder.decode(matcher.group(1), "UTF-8")); -
} catch(UnsupportedEncodingException e) { -
} -
} -
matcher.appendTail(sb); -
return sb.toString(); -
} -
}
利:减少服务器端转换编码带来的风险和压力
弊:客户端需要根据不同的设备系统自行做编码转换
注意: 这两种方案我都自己试验过,如果服务器时自己的话,我觉得采取第一种方案挺方便的,也不需要编码什么的,转来转去。如果数据时存储在他人服务器上的(比如阿里云),但是别人的服务器不允许存储emoji,那么我觉得采取第二种方案会好很多.
参考博客来源:https://blog.csdn.net/u010839779/article/details/45559291
参考博客来源:https://www.cnblogs.com/shihaiming/p/5833244.html
----------------------------------------
文章参考
https://blog.csdn.net/junsure2012/article/details/42171035
https://www.cnblogs.com/WangYunShuaiBaoLe/p/9055215.html
https://www.jb51.net/article/112879.htm
背景
iOS端测试时发现,在备注一栏输出emoji表情,保存时出现系统异常
java项目架构 spring-boot+mybatis+德鲁伊连接池
现象
抛出 java.sql.SQLException: Incorrect string value: '\xF0\x9F\x92\x94' for column 'name' at row 1
定位
1、数据库字段、表、数据库、mysql的编码需要设置成utf8mb4
2、数据库连接设置编码
show variables like "%char%";

解决
1、设置数据库
1)修改字段字符集
ALTER TABLE table_name CHANGE column_name VARCHAR(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
2)设置表的字符集
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
3)设置数据库的字符集
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
4)修改数据库应用字符集
![]()
找到linux下的mysql位置 $ whereis mysql 找到位置 $ vi my.cnf 【这里有my.ini,如果只有my-default.ini,则复制一份并命名为my.ini】 [增加或修改] [client] # 客户端来源数据的默认字符集 default-character-set = utf8mb4 [mysqld] # 服务端默认字符集 character-set-server=utf8mb4 # 连接层默认字符集 collation-server=utf8mb4_unicode_ci [mysql] # 数据库默认字符集 default-character-set = utf8mb4 $ service mysqld restart 重启服务即可
![]()
2、设置编码
在命令行中输入,但是这个只在当前会话起作用
set character_set_database=utf8; set character_set_server=utf8;
3、修改连接池属性(设置会话字符集)
按 Ctrl+C 复制代码
按 Ctrl+C 复制代码
或
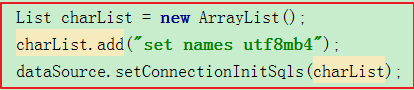
注: set names utf8mb4; 命令会将 character_set_client、character_set_connection、character_set_results 3个会话字符集相关变量均设置为 utf8mb4,以保证写入或者读出的数据使用 utf8mb4 字符集进行解释。
并且
![]()
jdbc.url=jdbc:mysql://localhost:3306/database?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=TRUE 特别说明其中的jdbc.url配置:如果你已经升级好了mysql-connector,其中的characterEncoding=utf8可以被自动被识别为utf8mb4(当然也兼容原来的utf8), 而autoReconnect配置我强烈建议配上,我之前就是忽略了这个属性,导致因为缓存缘故,没有读取到DB最新配置,导致一直无法使用utf8mb4字符集,多么痛的领悟!!
![]()
亲测可以
utf8与utf8mb4说明:
UTF- 8:Unicode Transformation Format-8bit,允许含BOM,但通常不含BOM。是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24为(三个字节)来编码。
UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。UTF-8编码的文字可以在各国支持UTF8字符集的浏览器上显示。如果是UTF8编码,则在外国人的英文IE上也能显示中文,他们无需下载IE的中文语言支持包。
UTF8MB4:MySQL在5.5.3之后增加了utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。