全栈02 Koa2+Vue2+MySQL 全栈的入门尝试
0 前言
其实并没有想要成为全栈工程师的想法,因为我觉得自己作为一个半路出家、至今全职前端开发经验不到两年的程序猿来说,把前端稍微深入一点的东西搞明白就算不错。
但是心里其实一直有一些疑惑,比如,每次后台提供的接口到底是怎么工作的?数据是怎么存放到数据库中的?数据库是怎么维护的?等等。这些问题总不时的在我全心全意的码代码的过程中冒出来。
幸好,我们前端有了NodeJS这个利器,让我可以在现有的技能树上去简单的探讨这些问题,而不用完全新开一门技能。这让我能够降低难度的去初步了解后台乃至整个网站的开发流程,让我有一些明白在以前的工作中接触过的后台代码“啊,原来是这么回事”。
想着通过尝试实现一个小小的登陆+后台管理系统,了解后台接口的实现、对数据库的操作以及代码部署。这次尝试对于我自己而言还是有意义的,补上了一些短板,解决了一些疑惑,但是这次尝试也仅仅是初步的、浅尝辄止的,很多更深的问题我目前没有经历和能力去深入的研究,所以本文也可能仅仅适用于有一些前端基础、对全栈技能有一些好奇的小伙伴,前端骨干、后端精英、全栈大神们,咱们说好,不要鄙视我好么?
确定了这个基本的约定后,让我们开始全栈开发的初次尝试吧。
P.S. 这篇文章尝试的主要思路来自于这篇文章,具体代码、实现有所不同,特此致谢。
1 项目简介
整个项目的技术栈,前端是Vue+Vue-Router+Element,后端的话主要是Koa2+MySQL。
前端的话不用说了,后端的话主要就是两个方面,一是为前端提供API,二是操作数据库。
2 入口文件
首先建立项目的入口文件index.js,
require('babel-polyfill');
require('babel-register');
if (process.env.NODE_ENV === 'development') {
require('./server/dev');
} else {
require('./server/app');
}
这个入口文件作用有两个,一个是区分开发模式和生产模式,两个模式下面主要的区别就是监听给的端口不同并且生产模式下会将webpack打包好的项目目录作为Koa静态文件服务。
另一个作用是引入babel-register和babel-polyfill
babel-register的目的主要是为了在文件中兼容ES6的import和export,但是注意:在入口文件(即本项目中的index.js)中仍然不能使用。
babel-polyfill的目的就是为ES6的一些API,比如Iterator、Generator、Set、Maps、Proxy、Reflect、Symbol、Promise等全局对象,以及一些定义在全局对象上的方法(比如Object.assign)提供转码。这个我考虑在后面进行优化,减小webpack打包体积,后面再说。
3 Koa中间件
首先看一下后端服务的真正的启动文件,以app.js为例吧,使用的框架是Koa2,在此基础上引用了很多的Koa2的中间件
3.1 koa-router
对路由进行处理控制的中间件,使用的时候我们现在server文件夹下面新建一个router文件夹,用存放所有子路由的文件
现在我们建立了两个文件,api.js用来管理所有的api,auth.js用来专门处理权限相关的路由:
看auth.js,很简单,引用koa-router,然后声明相关的路由并且对应处理方法,最后将路由模块导出
import * as userController from '../controller/userController'
import KoaRouter from 'koa-router';
const router = new KoaRouter();
router.get('/user/:id', userController.getUserInfo);
router.post('/user', userController.postUserAuth);
export {
router
};
里面引入的userController就是所有MVC中的C,controller层,我的理解就是对路由进行处理,对api请求进行处理,getUserInfo和postUserAuth都是在其中定义好的方法,具体一会再看。
auth.js作为子路由导出之后,在app.js中引入并且使用:
import KoaRouter from 'koa-router';
import * as auth from './router/auth';
const router = new KoaRouter();
const authRouter = auth.router;
// 挂载auth子路由
router.use('/auth', authRouter.routes());
// 挂载所有路由
app.use(router.routes());
这样层层传递下来,当我们使用get请求访问/auth/user时,就会触发预定义的userController.getUserInfo方法
其他api请求也是同样的处理。
3.2 koa-bodyparser
koa-bodyparser用来解析body的中间件,比方说你通过post来传递表单,json数据,或者上传文件,在koa中是不容易获取的,通过koa-bodyparser解析之后,在koa中this.body就能直接获取到数据。
3.3 koa-logger
koa-logger是koa的日志模块,在安装、挂载之后
import KoaLogger from 'koa-logger';
app.use(KoaLogger());
命令程序就会在控制台自动打印日志
3.4 koa-json
用来美观的输出JSON response,有两种使用方式:
一种是总是返回美化了的json数据,本文就采用的这种
import KoaJson from 'koa-json';
app.use(KoaJson());
另一种是默认不进行美化,但是当地址栏传入pretty参数的时候,则返回的结果是进行了美化的。
app.use(json({ pretty: false, param: 'pretty' }));
3.5 kcors
用来处理跨域的中间件,简化了我们处理CORS跨院的设置步骤,为我们在请求头上加上CORS,客户端即可跨域发送请求
import Kcors from 'kcors';
// 跨域设置
const corsOptions = {
'origin': '',
'credentials': true,
'maxAge': 3600
};
app.use(Kcors(corsOptions));
3.6 koa-jwt
用来实现JSON-WEB-TOKEN的中间件,具体的后面关于登录的章节进行展开
import jwt from 'koa-jwt';
router.use('/api', jwt({ secret: db.jwtSecret }), apiRouter.routes()); // 所有走/api/打头的请求都需要经过jwt验证。
3.7 koa-compress
用来为服务端的静态文件开启压缩
import Compress from 'koa-compress';
app.use(Compress({
threshold: 2048 // 要压缩的最小响应字节
}));
3.8 koa-static
用来实现访问静态资源,当我们使用webpack进行生产模式的打包之后,都放到了dist目录下,这个目录就作为Koa静态文件服务的目录:
import staticServer from 'koa-static';
// 将webpack打包好的项目目录作为Koa静态文件服务的目录
app.use(staticServer(path.resolve('dist')));
4 后端服务
对数据库的设计这里就不讲了,因为我也不会,只是简单的设计了两个表,一个是user,用来存放用户名和密码:
| 字段 | 类型 | 说明 |
|---|---|---|
| id | int(自增) | 用户的id |
| username | varchar(50) | 用户名 |
| password | char(128) | 进行bcrypt加密后的密码 |
另一张表是example,用来显示一些主要的数据
| 字段 | 类型 | 说明 |
|---|---|---|
| id | int(自增) | 数据id |
| title | varchar(50) | 标题 |
| image | varchar(50) | 插入时间 |
有了数据库的基本结构后,我们需要使用NodeJS来操作数据库,对数据库进行增删改查,对于Mongodb以前公司的同时使用的是Mongoose,对于MySQL我使用了Sequelize,关于Sequelize的基本使用可以参考我的另一篇总结
在使用Sequelize之前我们需要把数据库的表结构导出来,当然我们可以手动的导出,但是如果表很多的情况下,手动导出的效率太低了,可以使用sequelize-auto导出
这之前我们需要全局安装sequelize-auto:
npm install sequelize-auto -g
然后安装MySQL在NodeJS下的驱动mysql:
npm install mysql --save-dev
安装完成之后,进入server目录,执行下面的语句:
sequelize-auto -o "./schema" -d zhou -h 127.0.0.1 -u root -p 3306 -x XXXXX -e mysql
-o参数后面的是输出的文件夹目录-d参数后面的是数据库名-h参数后面是数据库地址-u参数后面是数据库用户名-p参数后面是端口号-x参数后面是数据库密码,-e参数后面指定数据库为mysql
完成之后再schema下面就会生成对应各个表的JS文件
user.js
export default function (sequelize, DataTypes) {
return sequelize.define('user', {
id: {
type: DataTypes.INTEGER(10),
allowNull: false,
primaryKey: true
},
username: {
type: DataTypes.STRING(50),
allowNull: true,
defaultValue: ''
},
password: {
type: DataTypes.CHAR(128),
allowNull: true,
defaultValue: ''
}
}, {
tableName: 'user'
});
};
example.js
export default function(sequelize, DataTypes) {
return sequelize.define('example', {
id: {
type: DataTypes.INTEGER(10),
allowNull: false,
primaryKey: true,
autoIncrement: true
},
title: {
type: DataTypes.STRING(50),
allowNull: true
},
image: {
type: DataTypes.STRING(100),
allowNull: true
}
}, {
tableName: 'example'
});
};
然后我们在server下建立config文件夹,在其中创建db.js文件,用来存放数据库地址、用户名、密码等信息,在这个文件中我通过对环境的判断,让代码操纵不同的数据库,在开发环境下想测试库写入信息,生产环境下操作的则是线上库
然后再在server下面创建common文件夹,创建mysql.js文件,用来连接我们上面定义好的数据库:
import Sequelize from 'sequelize';
import config from '../config/db';
const mysql = new Sequelize(config.mysql.default, {
define: {
timestamps: false,
},
operatorsAliases: false
});
export default mysql;
在连接好数据库并且导出mysql这个对象后,我们对数据库的增删改查都是基于这个对象上完成的。
创建model文件夹,用来存放对数据库处理的Model层的代码文件,创建userModel.js,对user表进行处理:
import Mysql from '../common/mysql'; // 引入MySQL数据库
const userSchema = '../schema/user'; // 引入user的表结构
const User = Mysql.import(userSchema);// 将Sequelize与表结构对应
export async function getUserById(id) {
return await User.findOne({
where: {
id
}
})
}
export async function getUserByName(username) {
return await User.findOne({
where: {
username
}
})
}
上面的代码中,首先将数据库和user表进行了对应,使用的是sequelize的import方法,然后定义了两个方法,分别是通过id和用户名查找数据
然后在我们上面提到的controller文件夹下的userController.js中,编写api的逻辑。
同样我们定义了两个方法,第一个方法是获取用户信息getUserInfo,对应的就是/auth/user/:id的get请求
export async function getUserInfo(ctx) {
const id = ctx.params.id; // 获取url里传过来的参数里的id
const user = await userModal.getUserById(id);
if (user) {
ctx.body = {
success: true,
retDsc: '查询成功',
ret: user
}
} else {
ctx.body = {
success: false,
retDsc: '用户不存在',
ret: null
};
}
}
需要注意的是,ctx是koa的上下文,可以理解为上(request)下(response)沟通的环境,其实就是将NodeJS的request/response对象封装进一个单独对象,ctx.req=ctx.request,ctx.res=ctx.response,ctx.body是http协议中的响应体,ctx.header是响应头
url里面传过来的参数/user/:id是通过ctx.params.id获取的
另外一个方法postUserAuth是用来为密码验证通过的用户下发token,保证在访问过程中用户权限的有效性,具体会在登录的章节展开,在这里我们只需要了解这个方法的主要逻辑即可
export async function postUserAuth(ctx) {
const data = ctx.request.body; // post过来的数据存在request.body里
const userInfo = await userModal.getUserByName(data.username); // 数据库返回的数据
if (!userInfo) {
ctx.body = {
success: false,
retDsc: '用户不存在',
ret: null
};
return
}
if (!bcrypt.compareSync(data.password, userInfo.password)) {
ctx.body = {
success: false,
retDsc: '密码错误',
ret: null
};
return
}
const userToken = {
iss: config.userToken.iss,
name: userInfo.username,
id: userInfo.id,
};
const secret = serverConfig.jwtSecret; // 指定密钥,这是之后用来判断token合法性的标志
const token = JWT.sign(userToken, secret); // 签发token
ctx.body = {
success: true,
retDsc: '登陆成功',
ret: {
token,
}
}
}
首先调用model里面定义的getUserByName,通过用户名查找用户,找不到就返回“用户不存在”,找到用户对密码校验,如果校验不通过返回“密码错误”,通过之后下发token
对于另外的exmaplModel.js→exampleController.js→api.js流程类似,不再展开,需要指出的几点是
- 想表中插入数据的方法是
create,更新的就是找到对应的对象,然后对要更新的属性直接赋值并保存(save),删除数据的方法是destroy - 操作数据库的操作都是异步函数,这里面使用了
async和await语法 - 最好将返回值的retCode和retDsc有统一的定义并统一维护
- 接口最好定义为使用restful风格的接口
最终在后端服务的实际启动文件app.js中,除了在第三章提到的加载各个中间件的服务,实现对应的功能,加上对错误和日至的处理:
// log
app.use(async (ctx, next) => {
const start = new Date();
await next();
let ms = new Date() - start;
console.log('%s %s - %s', ctx.method, ctx.url, ms); // 显示执行的时间
});
app.on('error', (err, ctx) => {
console.log('server error: ', err);
});
然后通过listen方法监听指定的端口:
app.listen(config.appServer.port, () => {
console.log(`Koa is listening in ${config.appServer.port}`);
});
在完成这些之后我们就可以开启后端服务了,在控制台输入:
node ./index.js
这样我们就要可以开启dev.js对应的端口,提示“koa is listening in 80”
这时候我们如果改动后端代码,都需要手动将node进行停止,然后再次执行上述命令开启服务,代码更改才能生效,好在我们有nodemon, nodemon将监视启动目录中的文件,如果有任何文件更改,nodemon将自动重新启动node应用程序。
如果没有全局安装nodemon的话是无法在命令行直接执行下面的命令来启动nodemon服务的:
nodemon ./index.js
我们将这条命令写到package.json中的scripts命令中,
"scripts": {
"server": nodemon ./index.js ",
},
当我们执行npm run server时就会启动nodemon服务,但是我们没有办法指定NODE_ENV环境变量,也就无法切换环境,所以需要在命令中增加NODE_ENV=development,再次执行时会报错,原因是“windows不支持NODE_ENV=development的设置方式”,解决方式就是使用cross-env,安装之后再NODE_ENV=development前面增加cross-env就可以了。
"scripts": {
"server": "cross-env NODE_ENV=development nodemon ./index.js ",
"start": "cross-env NODE_ENV=production nodemon ./index.js "
},
这样执行npm run server就可以监听开发端口8099了:“Koa is listening in 8099 for development”
P.S.
- 开发过程中对API的自测可以使用Postman
- webstorm是支持NodeJS的断点调试的,具体可以参考这篇文章。
5 前端页面
前端页面不细说了,就是Vue+Vue Router+element,首先进入的是login页面,进行登录,登录之后是一个列表页,点击单挑数据进入详情页,详情页有三个button,分别是插入、编辑和删除,没什么好讲的。
要注意的是现在由/login到/admin的跳转是单页面应用内的跳转,没有向后端发送任何请求,是从前端实现的。所以实际上在应用了后面的登陆系统后,跳转之前是需要想后端进行判断验证的,根据情况不同再决定是否跳转
6 登录系统
6.1 JSON-WEB-TOKEN
使用JSON-WEB-TOKEN可以实现无状态的登陆,可以参考这篇文章和这篇文章帮助理解
主要的登陆流程如下:
- 客户端通过Post请求将用户名和密码发送到服务器接口(这一过程一般都是明文传输的,建议通过SSL加密的https协议进行传输,避免被监听和中间人攻击。
- 服务器核定用用户名和密码
- 验证通过之后发送经过加密的Token返回给客户端
- 客户端收到Token后应该存储到cookie或者storage,每次访问指定资源都应该携带含有Token的cookie或者storage
- 后端受到请求信息,都需要验证TOKEN是否有效
6.2 token的请求与发放
具体到我们的代码中,我们已经安装了JSON-WEB-TOEKN的koa2中间件koa-jwt,然后在安装bcryptjs来为密码加解密,bcryptjs是一个第三方密码加密库
正规的流程应该是当我们向数据库添加一个用户的时候,密码通过bcryptjs加密后存储到数据库的password字段,而登陆时传输的是未经加密的密码数据(所以https是必须的)。我这里为了省事没有做注册的功能,所以数据库中的密码是通过手动加密然后存储的。
当服务器收到登陆验证的Post请求(/auth/user),会调用对应的postUserAuth方法
router.post('/user', userController.postUserAuth);
定义在userController.js中的postUserAuth方法会应用bcrypt的compareSync方法对密码进行验证。
if (!bcrypt.compareSync(data.password, userInfo.password)) {
ctx.body = {
success: false,
retDsc: '密码错误',
ret: null
};
return
}
要注意,compareSync的第一个参数应该是未加密的数据,第二个参数是加密的数据,否则是无法验证通过的。
验证通过之后,向客户端下发Token,Token由两个部分组成:
const userToken = {
iss: config.userToken.iss,
name: userInfo.username,
id: userInfo.id,
};
const secret = dbConfig.jwtSecret; // 指定密钥,这是之后用来判断token合法性的标志
const token = JWT.sign(userToken, secret); // 签发token
里面的userToken是包含了认证用户的一些信息,secret是我们定义的用来加密的密钥,是之后用来判断token合法性的标志,secret不应该在前端被暴露出来,后端将签发后的token返回给客户端:
ctx.body = {
success: true,
retDsc: '登陆成功',
ret: { token}
}
浏览器收到token之后,将token保存到了sessionStorage中,然后进行页面跳转:
sessionStorage.setItem('userToken', data.ret.token);
this.$router.push('/admin')
6.3 token的验证
访问哪些资源需要token的验证呢?这也需要我们在定义koa-router时指定,在app.js中
router.use('/auth', authRouter.routes());
router.use('/api', jwt({ secret: dbConfig.jwtSecret }), apiRouter.routes()); // 所有走/api/打头的请求都需要经过jwt验证。
我们定义,所有走/api/的路由都需要经过token的验证,验证的密钥就是之前定义的secret,具体的验证工作都是有koa-jwt帮我们完成的。
所以前端在发起API请求时,都应该在请求头中携带上token,否则请求会被拒绝。为了简化代码,我们在Vue router的定义文件中使用了全局的导航守卫router.beforeEach,在每次跳转之前都判断是否存在token(并且token是我们所下发的token,这是通过token解析后包含我们预定义一些信息来进行判断的),如果存在就在请求头添加token:
import JsonWebToken from 'jsonwebtoken';
router.beforeEach((to, from, next) => {
const token = sessionStorage.getItem('userToken');
const isTokenRight = !!(token && JsonWebToken.decode(token) && (JsonWebToken.decode(token).iss === config.userToken.iss));
// 全局设定发送请求header的token验证
if (isTokenRight) {
Vue.prototype.$http.defaults.headers.common['Authorization'] = 'Bearer ' + token
}
});
这样做其实不太对,请求头增加token其实在第一次登陆成功后就增加了,以后每次的网络请求的请求头都会携带token,就算token失效也不会改变
更加合理的做法应该是在每个网络请求前都判断一下token是否存在,如果存在就携带,如果不存在就不添加token
我的http请求使用了axois这个库,并且在src/components/helper下增加了一个httpHelper.js文件,用来对网络请求进行个性化定制,主要的定制内容有:
针对开发环境还是线上环境的URL前缀进行改变等:
const sever = process.env.NODE_ENV === "development" ? config.devServer : config.appServer;
axios.defaults.baseURL = sever.protocol + sever.host + ':' + sever.port;
axios.defaults.headers.post['Content-Type'] = 'application/x-www-form-urlencoded';
axios.defaults.withCredentials = true;
此外添加了请求拦截器和响应拦截器,刚才提到的对token的判断可以放到请求拦截器中。
// 添加请求拦截器
axios.interceptors.request.use(function (config) {
// 发送时展示loading
loading = uiHelper.showLoading();
return config;
}, function (error) {
// 请求错误时取消loading
loading.close();
// 给出提示
uiHelper.showMessage(errorText, 'error');
return Promise.reject(error);
});
// 添加响应拦截器
axios.interceptors.response.use(function (response) {
// 收到相应数据后取消loading
if (loading) {
loading.close();
}
return response;
}, function (error, text) {
// 响应错误时取消loading
if (loading) {
loading.close();
}
uiHelper.showMessage(errorText, 'error');
return Promise.reject(error);
});
6.4 跳转拦截
现在我们每一步路由的变化都会验证token了,但是如果我们直接手动将地址栏的地址更改,还是能够跳转到登陆后的页面的,所以我们需要跳转拦截,做法就是在导航守卫的钩子函数中进行拦截:
router.beforeEach((to, from, next) => {
const token = sessionStorage.getItem('userToken');
const isTokenRight = !!(token && JsonWebToken.decode(token) && (JsonWebToken.decode(token).iss === config.userToken.iss));
// 全局设定发送请求header的token验证
if (isTokenRight) {
Vue.prototype.$http.defaults.headers.common['Authorization'] = 'Bearer ' + token
}
if (to.path === '/login') { // 如果是跳转到登陆页的
if (isTokenRight) { // 如果有token就转向admin页不返回登录页
next('/admin')
} else { // 否则呆在登陆页
next()
}
} else {
if (isTokenRight) { // 如果有token就正常转向
next()
} else {
next('/login') // 否则跳转回登录页
}
}
});
注意:一定要确保要调用next()方法,否则钩子就不会被resolved。如果纯粹调用next(path)这样的方法最终还是会回到beforeEach()这个钩子里面来,如果没有写对条件就有可能出现死循环,栈溢出的情况。
至此,前后端的服务就算是都搭建起来了。
7 部署
对于一个没有任何部署惊人的人来说,部署这个小demo也是花费了很多精力。下面就是我的部署过程
首先,你需要有一个服务器,我选的是腾讯云的云服务器,最低配置那种,一个月40多,如果是学生的话可以申请免费的(云虚拟主机是不可以的,云虚拟主机只能配置静态网页,无法自行配置node环境、部署koa的服务等)
然后,你还需要申请一个MySQL的服务,同样我选购的是最低配置的,一个月30多
7.1 配置环境
都申请好了之后,要在虚拟服务器上配置环境。
7.1.1NodeJS
首先就是要安装NodeJS,要存放下载资源的目录,我放在了usr/local/src目录下,然后执行安装命令:
wget http://nodejs.org/dist/v8.10.0/node-v8.10.0-linux-x64.tar.gz
上述命令是下8.10.0的64位NodeJS版本,如果你想下载其他版本,可以将命令中的两处v8.10.0替换成其他版本号;如果你的系统是 32 位(一般是64位),也可以将x64改成x32
下载完成后,执行解压命令:
tar -zxvf node-v8.10.0-linux-x64.tar.gz
解压完成,可以看到当前目录解压后的文件夹node-v8.10.0-linux-x64,将这个文件夹重命名:
mv node-v8.10.0-linux-x64 node
现在,重命名后的node文件夹就是程序目录,然后需要添加环境变量,首先在root目录下找到.bash_profile,编辑:
vim ~/.bash_profile
找到PATH=$PATH:$HOME/bin,在后面添加路径为:
PATH=$PATH:$HOME/bin:/usr/local/src/node/bin
保存修改,然后重载一下
source ~/.bash_profile
现在node和npm就可以全局使用了
7.1.2 MySQ客户端
利用CentOS自带的包管理软件Yum去腾讯云的镜像源下载安装MySQL客户端。
yum install mysql
输入:
mysql -h 172.21.0.15 -P 3306 -u root -p xxxx
其中172.21.0.15是你申请的MySQL的内网地址,3306是端口号,xxxx是密码
7.1.3 其他
其他的软件都可以通过npm来安装了
7.1.4 保存镜像
安装之后,在云主机的列表页,操作的选项卡中的更多,选择制作镜像,输入镜像名称和竞相描述,将镜像保存,如果有新的云主机或者需要重装系统的时候,就可以选择自己制作的镜像来快捷的安装依赖了。
7.2 静态资源托管
前面提到过了,先用webpack打包出项目文件到dist目录中,然后使用koa-static来实现静态资源的托管
7.3 部署运行
一般会使用pm2来管理Node应用进程,而不是直接用Node来执行,原因是pm2这类进程工具可以更方便的监控一些信息,包括cpu,内存,日志,异常,其他信息等
安装之后的启动命令
pm2 start index.js
7.4 二级域名解析
网站目前可以登录了,地址栏输入http://139.199.112.184/#/admin,就可以看到登录页面了

但是现在我们目前只能用IP登录,因为我没有单独购买域名,但是我以前在百度云购买国一个域名,oldzhou.cn,并且已经备案过,所以我想将这个demo作为二级域名解析到demo.oldzhou.cn
登录百度云控制台,进入域名服务→域名管理,点击添加解析,在主机记录输入demo,记录值输入腾讯云服务器的公网IP,其他选择默认值即可。
等待一会就可以通过demo.oldzhou.cn来访问了。
8 webpack打包优化
8.1 开启Gzip
在webpack.prod.conf.js中,引入了compression-webpack-plugin,用来生成一个被gzip压缩过的JS文件
if (config.build.productionGzip) {
const CompressionWebpackPlugin = require('compression-webpack-plugin')
webpackConfig.plugins.push(
new CompressionWebpackPlugin({
asset: '[path].gz[query]',
algorithm: 'gzip',
test: new RegExp(
'\\.(' +
config.build.productionGzipExtensions.join('|') +
')$'
),
threshold: 10240,
minRatio: 0.8
})
)
}
可以看出来,压缩过的vendor.js文件由1.07M减小到了306kb
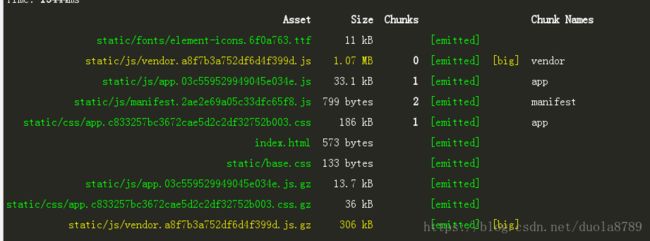
然后我们配合我们在前面提到的koa-compress中间件,来使用压缩后的JS文件,这时候来看我们的网络请求情况:
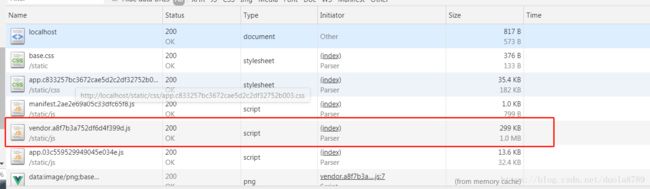
可以看到,size栏目上面的数字是传输的大小,是经过gzip压缩的,下面是文件实际的大小。
8.2 定位原因
虽然小了很多,但是这样一个简单的demo压缩之后还有300kb,也是让人无法忍受的,我们就要找出打包后的文件到底大在哪里
我们可以使用webpack-bundle-analyzer插件,它可以帮助我们发现模块有哪些组成,体积多大
我们可以在项目的package.json文件中注入如下命令,以方便运行她(npm run analyz),默认会打开http://127.0.0.1:8888作为展示。
"analyz": "cross-env NODE_ENV=production npm_config_report=true npm run build"
运行之后页面内容:

我们发现,两个大胖子是element-ui和vue,那就有针对性的对他们进行处理
8.2.1 element的按需加载
element提供了按需加载的方法,可以有效地减小项目体积。
按需加载需要安装babel-plugin-component
npm install babel-plugin-component -save-dev
然后在.babelrc中添加下面的内容:
"plugins": [
[
"component",
{
"libraryName": "element-ui",
"styleLibraryName": "theme-chalk"
}
]
]
然后就可以按需引入组件了,在scr/heper/elementHelper.js中,引入Vue和element的css文件,然后按需引入我们使用的表格、按钮等组件
import Vue from 'vue'
import 'element-ui/lib/theme-chalk/index.css';
import {
Table, TableColumn, Row, Col,
Input,
Button
} from 'element-ui'
[
Table, TableColumn, Row, Col,
Input,
Button
].forEach(Compo => Vue.use(Compo));
export default Vue
引入之后需要使用Vue.use或者Vue.component(Button.name, Button)来注册组件,注册完成后导出Vue
在前端入口文件main.js中引用的Vue更改为由elementHelper.js导出的Vue,然后我们就可以再组件中使用element的组件了,比如ElButton、ElTable等
登陆
将element改为按需加载之后,再执行分析看一下体积
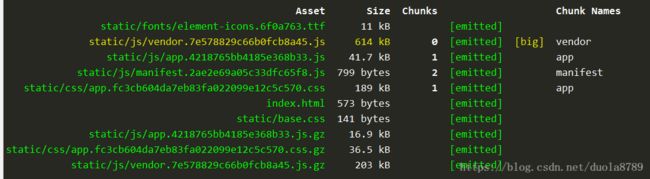
压缩前的打包体积由1.07M缩小到了614kb,压缩后的打包体积由299kb缩小到了203kb
8.2.2 外部引入模块
针对打包后的Vue比较大的问题,我们采取通过绕过webpack打包,外部引入模块的方式解决,这样既可以减小打包后的体积,加快打包速度,同时CDN的下载速度肯定要比我目前申请的服务器的宽带速度要快。
既然要处理,我们将前端用的相关的包都通过外部引入
外部引入模块需要在webpack.prod.conf.js中配置externals,
externals: {
'vue': 'Vue',
'vue-router': 'VueRouter',
'element-ui': 'ElementUI',
'axios': 'axios'
},
webpack可以不处理应用的某些依赖库,使用externals配置后,依旧可以在代码中通过CMD、AMD或者window/global全局的方式访问。关于externals更多的信息可以查看官网上的介绍
注意,这里面对应的属性名称比如
Vue、VueRouter就是源码中看导出的模块的名称
然后在index.html中通过标签的形式引入
background-demo
这样做之后再来看一下打包后的体积:
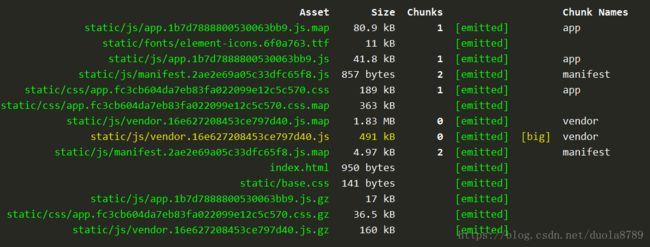
压缩前的体积已经减小到了491kb,压缩后的体积缩小到了160kb
9 写在最后
到这里基本上这个小的尝试就结束了,正如题目所说的,只是一个入门的尝试,并且还有很多可以改进的地方,但是他解决了我很多的疑惑,让我亲身接触到了前端之外的开发领域
学海无涯,大家加油。
参考
- https://molunerfinn.com/Vue+Koa/#简介
- https://chenshenhai.github.io/koa2-note/note/route/koa-router.html
- https://segmentfault.com/q/1010000005024412
- https://cnodejs.org/topic/56936889c2289f51658f0926
- https://www.npmjs.com/package/kcors
- https://div.io/topic/1937
- https://itbilu.com/nodejs/npm/VkYIaRPz-.html
- https://segmentfault.com/q/1010000008379638
- https://www.jianshu.com/p/fc7664e9025c
- https://segmentfault.com/a/1190000005811347
- https://segmentfault.com/a/1190000008479977
- https://www.zcfy.cc/article/two-quick-ways-to-reduce-react-app-s-size-in-production-1930.html
- https://segmentfault.com/q/1010000000672656
- https://www.zcfy.cc/article/two-quick-ways-to-reduce-react-app-s-size-in-production-1930.html
- https://jeffjade.com/2017/08/06/124-webpack-packge-optimization-for-volume/
- http://element-cn.eleme.io/#/zh-CN/component/quickstart
- https://www.cnblogs.com/wangrongxiang/p/8202912.html
- https://www.jb51.net/article/129670.htm
- https://blog.csdn.net/qq_25186543/article/details/79279874