Hadoop学习笔记:数据分析引擎Hive
概述
Hive是一个构建在Hadoop之上的数据仓库,和传统的数据仓库一样主要用来访问和管理数据,提供了类SQL查询语言;和传统数据仓库不一样的是可以处理超大规模的数据,可扩展性和容错性非常强。
 Hive是由FaceBook开源的分布式数据分析引擎,它把SQL语句转化成MapReduce作业提交到Hadoop上运行并返回结果。
Hive是由FaceBook开源的分布式数据分析引擎,它把SQL语句转化成MapReduce作业提交到Hadoop上运行并返回结果。
Hive可以做日志分析(包括统计网站一个时间段内的pv、uv),海量结构化数据离线分析,支持多维度、低成本数据分析,不必编写MapReduce程序。
Hive不是一个OLTP系统,响应时间慢,无法实时更新数据;另外,Hive的表达能力有限,不支持机器学习的迭代式计算,有些复杂运算用SQL不易表达。
Hive架构

Hive 和HBase一样,只是管理数据,数据存储在HDFS上,Yarn管理计算。Hive的内核有MapReduce、Spark,也有其他的计算引擎,不过大多数还是使用MapReduce。

1)用户接口,包括 CLI,JDBC/ODBC,WebUI
2)元数据存储(Metastore),默认存储在自带的数据库derby中,线上使用时一般换为MySQL。Metastore存储数据库的Schema,包括字段名称、类型等,以及数据映射关系(数据库Table和HDFS文件夹的对应关系)。Metastore检查SQL的正确性。
3)驱动器(Driver)是一个解释器、编译器、优化器、执行器,使SQL转化为MapReduce,并将MapReduce作业提交到Yarn上运行。
4)Hadoop使用MapReduce进行计算,使用HDFS 进行存储。
Hive访问方式
- 重客户端:
所有的SQL翻译都在客户端进行,最后将MapReduce作业提交到HDFS上执行。客户端比较耗费资源,每个客户端都可以看做是一个Hive Server。

使用Hive CLI,在本地客户端输入“Hive”运行Hive,通过本地配置获取Metastore(借助第三方数据库存储)的位置,本地客户端使用Metastore来运行SQL,在本地翻译SQL为MapReduce作业,并提交到Hadoop上运行。系统可以启动多个Metastore,映射到MySQL,所以它是HA高可靠。
hive
hive -h -p
- 轻客户端:
类似于JDBC,Beeline,将请求提交到Hive Server上,由Hive Server将SQL翻译成MapReduce后提交到HDFS上运行。一般只需要一个Hive Server和一个Metastore就可以了。

Beeline获取Hive Server的位置,把SQL语句传给Hive Server,Hive Server充当Hive Driver的角色,Beeline是轻客户端。
beeline -u jdbc:hive2://:
HIve的数据模型

1)Databases:和关系型数据库中的数据库一样;
2)Tables:和关系型数据库中的表一样;
3)Partitions(可选):一些特殊的列,基于Table的优化,用于优化数据的存储和查询;
4)Files:实际数据的物理存储单元。
Hive的数据类型:
| 类型 | 大小 | 举例 |
|---|---|---|
| TINYINT | 1 byte 有符号整型 | 20 |
| SMALLINT | 2 byte 有符号整型 | 20 |
| INT | 4 byte 有符号整型 | 20 |
| BIGINT | 8 byte 有符号整型 | 20 |
| BOOLEAN | 布尔类型 | true |
| FLOAT | 单精度浮点型 | 3.14159 |
| DOUBLE | 双度浮点型 | 3.14159 |
| STRING(CHAR, VARCHAR) | 字符串 | ‘Now is the time’, “for all” |
| TIMESTAMP (Date) | 整型、浮点型或字 符串 | 1327882394 (Unix epoch seconds), 1327882394.123456789 (Unix epochseconds plus nanoseconds), |
| BINARY | 字节数组 | |
| STRUCT | 与C/C++中的结构体类似,可通过 “.”访问每个域的值,比如 STRUCT {first STRING; last STRING},可通过name.first访问第 一个成员。 | struct(‘John’, ‘Doe’) |
| MAP | 存储key/value对,可通过[‘key’]获 取每个key的值,比如‘first’→‘John’ and ‘last’→‘Doe’,可通过name[‘last’] 获取last name。 | map(‘first’, ‘John’, ‘last’, ‘Doe’) |
| ARRAY | 同种类型的数据集合,从0开始索引,array(‘John’, ‘Doe’) 比如[‘John’, ‘Doe’],,可通过name[1]获取“Doe”。 | array(‘John’, ‘Doe’) |
数据定义语句(DDL):
1)Create/Drop/Alter Database
2)Create/Drop/Truncate Table
3)Alter Table/Partition/Column
4)Create/Drop/Alter View
5)Create/Drop/Alter Index
6)Create/Drop Function
7)Create/Drop/Grant/Revoke Roles and Privileges 8)Show
9)Describe
数据格式:
| 分隔符 | 解释 |
|---|---|
| \n | 记录间的分割符,默认一行一条记录 |
| ^A (“control” A) | 列分隔符,通常写成“\001” |
| ^B | ARRAY或STRUCT中元素分隔符,或MAP中 key与value分隔符,通常写成“\002” |
| ^C | MAP中key/value对间的分隔符,通常写成 “\003” |
例如:
John Doe^A100000.0^AMary Smith^BTodd Jones^AFederal Taxes^C.2^BState Taxes^C.05^BInsurance^C.1^A1 Michigan Ave.^BChicago^BIL^B60600
数据操作语句(DML):
1)数据加载与插入语句:
-
Load Data:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename[PARTITION (partcol1=val1, partcol2=val2 ...)][local]标明是本地,没有[local]标明是在HDFS上;
当数据被加载至表中时,不会对数据进行任何转换。Load 操作只是将数据复制/移动至 Hive 表对应的位置。默认每个表一个目录,比如数据库dbtest中,表名为tbtest,则数据存放位置为:${metastore.warehouse.dir}/dbtest.db/tbtest,metastore.warehouse.dir默认值是/user/hive/warehouse -
Insert
INSERT OVERWRITE TABLE tablename[PARTITION (partcol1=val1,partcol2=val2 ...)] select_statement FROM from_statement
2)数据查询语句:SELECT
3)查看HQL执行计划:explain
4)表/分区导入导出:Export/Import
数据验证方式:
传统数据库是写时模式,既是在数据写入的时候就要验证数据类型;而Hive是读时模式,在Load时不检查数据是否符合Schema,在读的时候检查、解析具体的数据字段Schema。
数据分区:
为减少不必要的暴力数据扫描,可以对表进行分区,为避免产生过多小文件,建议只对离散字段进行分区。
Hive对表分区(Partition),其实就是将不同的数据存储到不同的目录或文件中,有点像传统数据库中的索引。不是所有的字段都可以做为Partition,比如像年龄、性别这样的字段比较容易做,对于Float或Double就不容易做,因为Partition不是使用范围划分,而是使用确定值,所以对于Float或Double这样线性的数字不容易做分区。建表的时候用“PARTITIONED BY”来定义使用哪些字段来分区

以上例子是将相同国家的数据先存储在一起,然后是相同的州的数据。所以当做查询的时候,如果已经定位是某个国家和某个州,就可以直接去这个目录或文件去查看,可以排除掉其他的目录和文件了。
一般会用时间作为Partition,这样当只保留最近一段时间数据的时候,就可以把Partition等于之前时间的文件删除掉。

这个表有九个属性,但是原始数据只有7列,所以分区的名字其实不在原始数据中。在导入数据的时候指定了分区的名字,导入数据的时候加入了分区列。
Partition对于查询没有区别,只是在文件底层判断读取哪些文件。查询后,分区也作为数据列显示。当有条件但分区不在条件中的时候,分区是不会优化Hive查询的;但是当查询分区不带条件的时候,是可以优化查询的,因为Hive只查目录。
当分区名作为GROUPBY时,有可能会减少Reduce,所以有可能优化Hive,这时Map在分区内进行,减少了Shuffle,减少了网络IO,GROUPBY就相当于Reduce,它把相同的Key的记录聚合到一起,直接Map统计数量,省略了Shuffle和Reduce。
外部表:
外部表就是使用Hive管理HDFS上已经有的数据表,使用external关键字, 删除表时,外部表只删除元数据,不删除数据,更加安全。所以,内表DROP后数据不在了,外表DROP后数据还在。
列存储格式ORC:
在Create/Alter表的时候,可以为表以及分区的文件指定不同的格式(Storage Formats,Row Formats和SerDe)。对于文本格式还需要指定分隔符(行分割符,列分割符,集合元素分割符,Kv分割符)。
Hive默认是存储为TEXT格式,行存储模式,ORC和PARQUET是比较典型的列式存储。ORC比较经典,是伴随Hive成长的列式存储。ORC的文件不容易创建,可以先创建TEXT文件,再用Hive的工具来转化为ORC格式。
• STORED AS file_format
– STORED AS PARQUET
– STORED AS ORC
– STORED AS SEQUENCEFILE
– STORED AS AVRO
– STORED AS TEXTFILE
• STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)
– STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler’ WITHSERDEPROPERTIES ("hbase.columns.mapping"= ":key,a:b,a:c,d:e");
-
传统行式存储(如:text,sequence file)
数据是按行存储的,没有索引的查询使用大量I/O;建立索引和物化视图需要花费大量时间和资源;面向查询的需求,数据库必须被大量膨胀才能满足性能要求。 -
列式存储(如ORCFile、Parquet)
数据是按列存储,每一列单独存放,数据即是索引,访问查询涉及的列可以大量降低系统I/O;每一列由一个线索来处理,查询支持并发处理;数据类型一致,数据特征相似,可以高效压缩。

大数据的优化主要是减少IO,因为磁盘和网络会比较慢,而数据分析的时候一般都是按列查询,只选择几列,当使用列存储的时候,除了查询列,其他列的IO就可以节省。行存储不建立索引的话,当查询某几行的时候要把所有的行都扫描。但是如果更新数据还是按行存储更容易,对于Hive主要是分析为主,修改数据很少,所以在大数据分析中主要用列存储。比如星型模型中的事实表一般都很大,都是用列存储,维度表一般不大,可以用行存储。

先将TEXT文件Load到TEXT临时表中,再插入到ORC表中,ORC表的上层查询语句和TEXT表是一样的,只是底层数据格式不一样。
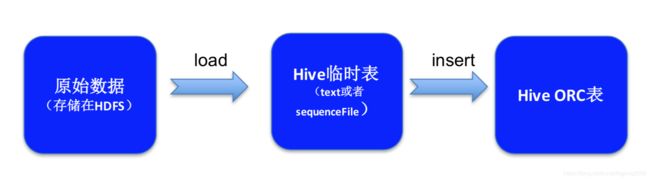
创建表,通过最后一句话设置表的存储格式为ORC,如果没有最后一句话,默认是TEXT格式
create table if not exists record_orc ( rid STRING,
uid STRING,
bid STRING,
price INT,
source_province STRING,
target_province STRING,
site STRING,
express_number STRING,
express_company STRING,
trancation_date DATE
)
stored as orc
导入数据
insert into table record_orc select * from record;
ORC表中的数据可能会存在不同的ORC文件中,一个ORC文件按照行切分成不同的Blog(不同与HDFS上的Blog,是ORC本身的Blog),然后Blog中的每列存储称为一个Strip;Hive在调用MapReduce任务的时候,一个Map处理一个Blog,因为每个Blog的结构是一样的,所以Map的处理逻辑一样,可以并行的计算,并且每个Blog的大小保持和HDFS上的Blog一样,这样可以保证数据的一致性。
参考链接
https://cwiki.apache.org/confluence/display/Hive/Home;jsessio
https://wenku.baidu.com/view/059b4d12312b3169a451a49e.ht ml