【知识发现】隐语义模型LFM算法python实现(一)
1、隐语义模型:
物品:表示为长度为k的向量q(每个分量都表示 物品具有某个特征的程度)
用户兴趣:表示为长度为k的向量p(每个分量都表示 用户对某个特征的喜好程度)
用户u对物品i的兴趣可以表示为:
![]()
其损失函数定义为:
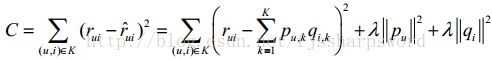
使用随机梯度下降,获得参数p,q。
负样本生成:对于只有正反馈信息(用户收藏了,关注了xxx)的数据集,需要生成负样本,原则如下
1)生成的负样本要和正样本数量相当
2)物品越热门(用户没有收藏该物品),越有可能是负样本
2、数据集:https://grouplens.org/datasets/movielens/

格式:
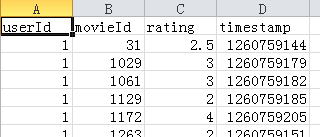
3、参考代码:
# -*- coding: utf-8 -*-
'''
Created on 2017年9月15日
@author: Jason.F
'''
from math import exp
import pandas as pd
import numpy as np
import pickle
import time
from numpy import rank
def getUserNegativeItem(frame, userID):
'''
获取用户负反馈物品:热门但是用户没有进行过评分 与正反馈数量相等
:param frame: ratings数据
:param userID:用户ID
:return: 负反馈物品
'''
userItemlist = list(set(frame[frame['userid'] == userID]['itemid'])) #用户评分过的物品
otherItemList = [item for item in set(frame['itemid'].values) if item not in userItemlist] #用户没有评分的物品
itemCount = [len(frame[frame['itemid'] == item]['userid']) for item in otherItemList] #物品热门程度
series = pd.Series(itemCount, index=otherItemList)
series = series.sort_values(ascending=False)[:len(userItemlist)] #获取正反馈物品数量的负反馈物品
negativeItemList = list(series.index)
return negativeItemList
def getUserPositiveItem(frame, userID):
'''
获取用户正反馈物品:用户评分过的物品
:param frame: ratings数据
:param userID: 用户ID
:return: 正反馈物品
'''
series = frame[frame['userid'] == userID]['itemid']
positiveItemList = list(series.values)
return positiveItemList
def initUserItem(frame, userID=1):
'''
初始化用户正负反馈物品,正反馈标签为1,负反馈为0
:param frame: ratings数据
:param userID: 用户ID
:return: 正负反馈物品字典
'''
positiveItem = getUserPositiveItem(frame, userID)
negativeItem = getUserNegativeItem(frame, userID)
itemDict = {}
for item in positiveItem: itemDict[item] = 1
for item in negativeItem: itemDict[item] = 0
return itemDict
def initUserItemPool(frame,userID):
'''
初始化目标用户样本
:param userID:目标用户
:return:
'''
userItem = []
for id in userID:
itemDict = initUserItem(frame, userID=id)
userItem.append({id:itemDict})
return userItem
def initPara(userID, itemID, classCount):
'''
初始化参数q,p矩阵, 随机
:param userCount:用户ID
:param itemCount:物品ID
:param classCount: 隐类数量
:return: 参数p,q
'''
arrayp = np.random.rand(len(userID), classCount) #构造p矩阵,[0,1]内随机值
arrayq = np.random.rand(classCount, len(itemID)) #构造q矩阵,[0,1]内随机值
p = pd.DataFrame(arrayp, columns=range(0,classCount), index=userID)
q = pd.DataFrame(arrayq, columns=itemID, index=range(0,classCount))
return p,q
def initModel(frame, classCount):
'''
初始化模型:参数p,q,样本数据
:param frame: 源数据
:param classCount: 隐类数量
:return:
'''
userID = list(set(frame['userid'].values))
itemID = list(set(frame['itemid'].values))
p, q = initPara(userID, itemID, classCount)#初始化p、q矩阵
userItem = initUserItemPool(frame,userID)#建立用户-物品对应关系
return p, q, userItem
def latenFactorModel(frame, classCount, iterCount, alpha, lamda):
'''
隐语义模型计算参数p,q
:param frame: 源数据
:param classCount: 隐类数量
:param iterCount: 迭代次数
:param alpha: 步长
:param lamda: 正则化参数
:return: 参数p,q
'''
p, q, userItem = initModel(frame, classCount)
for step in range(0, iterCount):
for user in userItem:
for userID, samples in user.items():
for itemID, rui in samples.items():
eui = rui - lfmPredict(p, q, userID, itemID)
for f in range(0, classCount):
print('step %d user %d class %d' % (step, userID, f))
p[f][userID] += alpha * (eui * q[itemID][f] - lamda * p[f][userID])
q[itemID][f] += alpha * (eui * p[f][userID] - lamda * q[itemID][f])
alpha *= 0.9
return p, q
def sigmod(x):
'''
单位阶跃函数,将兴趣度限定在[0,1]范围内
:param x: 兴趣度
:return: 兴趣度
'''
y = 1.0/(1+exp(-x))
return y
def lfmPredict(p, q, userID, itemID):
'''
利用参数p,q预测目标用户对目标物品的兴趣度
:param p: 用户兴趣和隐类的关系
:param q: 隐类和物品的关系
:param userID: 目标用户
:param itemID: 目标物品
:return: 预测兴趣度
'''
p = np.mat(p.ix[userID].values)
q = np.mat(q[itemID].values).T
r = (p * q).sum()
r = sigmod(r)
return r
def recommend(frame, userID, p, q, TopN=10):
'''
推荐TopN个物品给目标用户
:param frame: 源数据
:param userID: 目标用户
:param p: 用户兴趣和隐类的关系
:param q: 隐类和物品的关系
:param TopN: 推荐数量
:return: 推荐物品
'''
userItemlist = list(set(frame[frame['userid'] == userID]['itemid']))
otherItemList = [item for item in set(frame['itemid'].values) if item not in userItemlist]
predictList = [lfmPredict(p, q, userID, itemID) for itemID in otherItemList]
series = pd.Series(predictList, index=otherItemList)
series = series.sort_values(ascending=False)[:TopN]
return series
def Recall(df_test,p,q):#召回率
hit=0
all=0
df_userid=df_test['userid']
df_userid=df_userid.drop_duplicates()
for userid in df_userid:
pre_item=recommend(df_test, userid, p, q)
df_user_item=df_test.loc[df_test['userid'] == userid]
true_item=df_user_item['itemid']
for itemid,prob in pre_item.items():
if itemid in true_item:
hit+=1
all+=len(true_item)
return hit/(all*1.0)
def Precision(df_test,p,q):
hit=0
all=0
df_userid=df_test['userid']
df_userid=df_userid.drop_duplicates()
for userid in df_userid:
pre_item=recommend(df_test, userid, p, q)
df_user_item=df_test.loc[df_test['userid'] == userid]
true_item=df_user_item['itemid']
for itemid,prob in pre_item.items():
if itemid in true_item:
hit+=1
all+=len(pre_item)
return hit/(all*1.0)
if __name__ == '__main__':
start = time.clock()
#导入数据
df_sample = pd.read_csv("D:\\tmp\\ratings.csv",names=['userid','itemid','ratings','time'],header=0)
#模型训练
p, q = latenFactorModel(df_sample,5, 3, 0.02, 0.01 )
#模型评估
df_test=df_sample.sample(frac=0.2)#抽20%来测试
print (Recall(df_test,p,q))#召回率
print (Precision(df_test,p,q))#准确率 print (Coverage(df_test,p,q))#覆盖率
end = time.clock()
print('finish all in %s' % str(end - start))
实际推荐应用中,应结合特征工程开展。
补充覆盖率评价指标的函数:
def Coverage(df_test,p,q):#覆盖率
df_itemid=df_test['itemid']
df_itemid=df_itemid.drop_duplicates()
rec_items=set()#推荐的物品总数
df_userid=df_test['userid']
df_userid=df_userid.drop_duplicates()
for userid in df_userid:
pre_item=recommend(df_test, userid, p, q)
for itemid,prob in pre_item.items():
rec_items.add(itemid)
return len(rec_items)/(len(df_itemid)*1.0)