【Python-ML】SKlearn库逻辑斯蒂回归(logisticregression) 使用
# -*- coding: utf-8 -*-
'''
Created on 2018年1月12日
@author: Jason.F
@summary: Scikit-Learn库逻辑斯蒂回归分类算法
'''
from sklearn import datasets
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
#数据导入
iris=datasets.load_iris()
X=iris.data[:,[2,3]]
y=iris.target
print (np.unique(y))
#训练集和测试集划分
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
#标准化
sc=StandardScaler()
sc.fit(X_train)#计算样本的均值和标准差
X_train_std=sc.transform(X_train)
X_test_std=sc.transform(X_test)
#逻辑斯蒂回归
lr=LogisticRegression(C=1000.0,random_state=0)
lr.fit(X_train_std,y_train)
#模型预测
y_pred=lr.predict_proba(X_test_std[0,:])
print (y_pred[:,1])
#绘制决策边界
def plot_decision_regions(X,y,classifier,test_idx=None,resolution=0.02):
# 设置标记点和颜色
markers = ('s','x','o','^','v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# 绘制决策面
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
#绘制所有样本
X_test,y_test=X[test_idx,:],y[test_idx]
for idx,cl in enumerate(np.unique(y)):
plt.scatter(x=X[y==cl,0],y=X[y==cl,1],alpha=0.8,c=cmap(idx),marker=markers[idx],label=cl)
#高亮预测样本
if test_idx:
X_test,y_test =X[test_idx,:],y[test_idx]
plt.scatter(X_test[:,0],X_test[:,1],c='',alpha=1.0,linewidths=1,marker='o',s=55,label='test set')
X_combined_std=np.vstack((X_train_std,X_test_std))
y_combined=np.hstack((y_train,y_test))
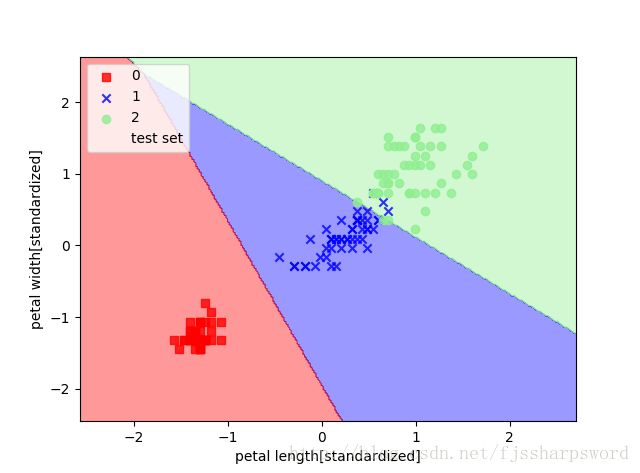
plot_decision_regions(X=X_combined_std, y=y_combined, classifier=lr, test_idx=range(105,150))
plt.xlabel('petal length[standardized]')
plt.ylabel('petal width[standardized]')
plt.legend(loc='upper left')
plt.show()
#观察正则化参数C的作用:减少正则化参数C的值相当于增加正则化的强度
#观察:减小参数C值,增加正则化强度,导致权重系数逐渐收缩
weights,params=[],[]
for c in np.arange(-5,5,dtype=float):
lr=LogisticRegression(C=10**c,random_state=0)
lr.fit(X_train_std,y_train)
weights.append(lr.coef_[1])
params.append(10**c)
weights=np.array(weights)
plt.plot(params,weights[:,0],label='petal length')
plt.plot(params,weights[:,1],label='petal width',linestyle='--')
plt.ylabel('weight coefficient')
plt.xlabel('C')
plt.legend(loc='upper left')
plt.xscale('log')
plt.show()
结果: