以太坊源码分析之九区块
以太坊源码分析之九区块
终于到了区块链中最和区块链搭界的部分,毕竟它们只差一个字。区块是区块链的基础,区块通过HASH链接在一起就成为了区块链。
一、区块的相关数据结构
不当嘴炮党,看源码:
链数据结构:
type BlockChain struct {
chainConfig *params.ChainConfig // Chain & network configuration
cacheConfig *CacheConfig // Cache configuration for pruning
db ethdb.Database // Low level persistent database to store final content in
triegc *prque.Prque // Priority queue mapping block numbers to tries to gc
gcproc time.Duration // Accumulates canonical block processing for trie dumping
hc *HeaderChain //只有头的链,用于验证和快速下载
//其下为消息订阅的一系列事件
rmLogsFeed event.Feed //其下为消息订阅的一系列事件,删除日志
chainFeed event.Feed //主链事件
chainSideFeed event.Feed //侧链事件
chainHeadFeed event.Feed // 主链头事件
logsFeed event.Feed
scope event.SubscriptionScope
genesisBlock *types.Block //创世块
mu sync.RWMutex // global mutex for locking chain operations
chainmu sync.RWMutex // blockchain insertion lock
procmu sync.RWMutex // block processor lock
checkpoint int // checkpoint counts towards the new checkpoint
currentBlock *types.Block // Current head of the block chain
currentFastBlock *types.Block // Current head of the fast-sync chain (may be above the block chain!)
stateCache state.Database // State database to reuse between imports (contains state cache)
bodyCache *lru.Cache // Cache for the most recent block bodies
bodyRLPCache *lru.Cache // Cache for the most recent block bodies in RLP encoded format
blockCache *lru.Cache // Cache for the most recent entire blocks
futureBlocks *lru.Cache // future blocks are blocks added for later processing
quit chan struct{} // blockchain quit channel
running int32 // running must be called atomically
// procInterrupt must be atomically called
procInterrupt int32 // interrupt signaler for block processing
wg sync.WaitGroup // chain processing wait group for shutting down
engine consensus.Engine
processor Processor // block processor interface
validator Validator // block and state validator interface
vmConfig vm.Config
badBlocks *lru.Cache // Bad block cache
}
块数据结构:
// Block represents an entire block in the Ethereum blockchain.
type Block struct {
header *Header
uncles []*Header //叔块的头,叔块最多有两个
transactions Transactions
// caches
hash atomic.Value
size atomic.Value
// Td is used by package core to store the total difficulty
// of the chain up to and including the block.
td *big.Int //难度
// These fields are used by package eth to track
// inter-peer block relay.
ReceivedAt time.Time
ReceivedFrom interface{}
}
区块头数据结构:
type Header struct {
//指向父区块(parentBlock)的hash。除了创世块(Genesis Block)没有父区块,每个区块有且//只有一个父区块。
ParentHash common.Hash `json:"parentHash" gencodec:"required"`
//叔块地址。
UncleHash common.Hash `json:"sha3Uncles" gencodec:"required"`
//出块地址。挖矿和交易都发给这个地址。
Coinbase common.Address `json:"miner" gencodec:"required"`
//世界状态,状态树的根哈希值—三大树
Root common.Hash `json:"stateRoot" gencodec:"required"`
//交易树根哈希值
TxHash common.Hash `json:"transactionsRoot" gencodec:"required"`
//接收者树的的根哈希值
ReceiptHash common.Hash `json:"receiptsRoot" gencodec:"required"`
//交易收据日志组成的布隆过滤器
Bloom Bloom `json:"logsBloom" gencodec:"required"`
//本块难度
Difficulty *big.Int `json:"difficulty" gencodec:"required"`
//块号
Number *big.Int `json:"number" gencodec:"required"`
//本块Gas上限
GasLimit uint64 `json:"gasLimit" gencodec:"required"`
//Gas使用量
GasUsed uint64 `json:"gasUsed" gencodec:"required"`
//本块的产生时间戳
Time *big.Int `json:"timestamp" gencodec:"required"`
//附加数据
Extra []byte `json:"extraData" gencodec:"required"`
//一个哈希值,用NONCE组合用于计算工作量
MixDigest common.Hash `json:"mixHash" gencodec:"required"`
//区块产生的随机值,每个用户必须单调步长为1递增
Nonce BlockNonce `json:"nonce" gencodec:"required"`
}
三者的关系非常明晰,BlockChain 由Block组成,而Header是后者的重要组成部分。
在BlockChain的注释中指出:它是一个标准的以太坊的链数据结构,其内部包含了创世区块及相关数据库的配置,以太坊通过它管理链的插入,恢复,重组等操作.
通过由一系列规则组成的两阶段的验证器来插入一个区块。利用交易处理器对区块中的交易进行处理并利用验证器进行验证,一旦错误将导致上链的失败。
需要注意的是GetBlock函数可能得到任何当前链中的块,但是使用GetBlockByNumber函数却一直得到当前主链中的区块。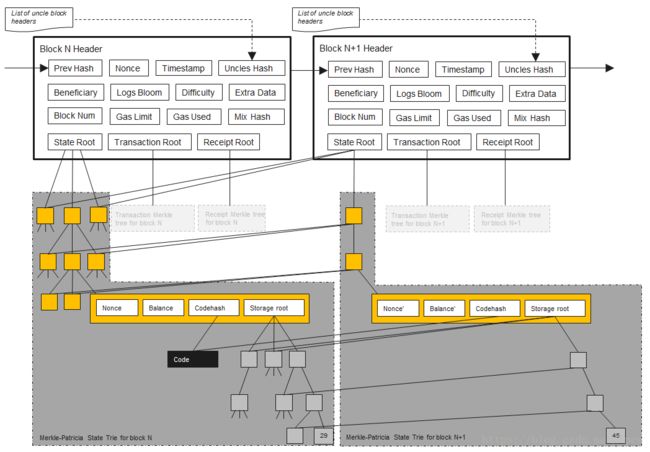
二、以太坊的存储模型
以太坊的存储分三层:
上层:业务数据
中层:MPT缓存
底层:LEVELDB
结合到实际的代码中:
type StateDB struct {
db Database
trie Trie
// This map holds 'live' objects, which will get modified while processing a state transition.
stateObjects map[common.Address]*stateObject //顶层业务
stateObjectsDirty map[common.Address]struct{}
……
}
type stateObject struct {
address common.Address
addrHash common.Hash // hash of ethereum address of the account
data Account
db *StateDB
// DB error.
// State objects are used by the consensus core and VM which are
// unable to deal with database-level errors. Any error that occurs
// during a database read is memoized here and will eventually be returned
// by StateDB.Commit.
dbErr error
// Write caches.缓存
trie Trie // storage trie, which becomes non-nil on first access
code Code // contract bytecode, which gets set when code is loaded
cachedStorage Storage // Storage entry cache to avoid duplicate reads
dirtyStorage Storage // Storage entries that need to be flushed to disk
// Cache flags.
// When an object is marked suicided it will be delete from the trie
// during the "update" phase of the state transition.
dirtyCode bool // true if the code was updated
suicided bool
touched bool
deleted bool
onDirty func(addr common.Address) // Callback method to mark a state object newly dirty
}
最终在 CommitTire实现写入数据LEVELDB。
三、区块的存储
区块的存储在以太坊中是通过leveldb实现的,leveldb是一个kv型数据库,支持高速写入。
在存储区块信息时,会将区块头和区块体分开进行存储。因此在区块的结构体中,能够看到Header和Body两个结构体。
头(Header)的存储格式为:
headerPrefix + num (uint64 big endian) + hash -> rlpEncode(header)
key是由header的前缀,Number和区块hash构成。value是header的RLP编码。
区块体(Body)的存储格式为:
bodyPrefix + num (uint64 big endian) + hash -> rlpEncode(block body)
key是由body前缀,Number和区块hash构成。value是区块体的RLP编码。
看一下database_util.go中的定义的变量:
var (
headHeaderKey = []byte("LastHeader")
headBlockKey = []byte("LastBlock")
headFastKey = []byte("LastFast")
// Data item prefixes (use single byte to avoid mixing data types, avoid `i`).
headerPrefix = []byte("h") // headerPrefix + num (uint64 big endian) + hash -> header
tdSuffix = []byte("t") // headerPrefix + num (uint64 big endian) + hash + tdSuffix -> td
numSuffix = []byte("n") // headerPrefix + num (uint64 big endian) + numSuffix -> hash
blockHashPrefix = []byte("H") // blockHashPrefix + hash -> num (uint64 big endian)
bodyPrefix = []byte("b") // bodyPrefix + num (uint64 big endian) + hash -> block body
blockReceiptsPrefix = []byte("r") // blockReceiptsPrefix + num (uint64 big endian) + hash -> block receipts
lookupPrefix = []byte("l") // lookupPrefix + hash -> transaction/receipt lookup metadata
bloomBitsPrefix = []byte("B") // bloomBitsPrefix + bit (uint16 big endian) + section (uint64 big endian) + hash -> bloom bits
preimagePrefix = "secure-key-" // preimagePrefix + hash -> preimage
configPrefix = []byte("ethereum-config-") // config prefix for the db
// Chain index prefixes (use `i` + single byte to avoid mixing data types).
BloomBitsIndexPrefix = []byte("iB") // BloomBitsIndexPrefix is the data table of a chain indexer to track its progress
// used by old db, now only used for conversion
oldReceiptsPrefix = []byte("receipts-")
oldTxMetaSuffix = []byte{0x01}
ErrChainConfigNotFound = errors.New("ChainConfig not found") // general config not found error
preimageCounter = metrics.NewCounter("db/preimage/total")
preimageHitCounter = metrics.NewCounter("db/preimage/hits")
)
这些前缀用来表明是什么样的数据类型。下面看一下具体的存储,在core/database_util.go中封装了区块存储和读取相关的代码。
// DatabaseReader wraps the Get method of a backing data store.
type DatabaseReader interface {
Get(key []byte) (value []byte, err error)
}
// DatabaseDeleter wraps the Delete method of a backing data store.
type DatabaseDeleter interface {
Delete(key []byte) error
}
写入区块:
// WriteBlock serializes a block into the database, header and body separately.
func WriteBlock(db ethdb.Putter, block *types.Block) error {
// Store the body first to retain database consistency
if err := WriteBody(db, block.Hash(), block.NumberU64(), block.Body()); err != nil {
return err
}
// Store the header too, signaling full block ownership
if err := WriteHeader(db, block.Header()); err != nil {
return err
}
return nil
}
下面是写区块调用的两个函数:
// WriteHeader serializes a block header into the database.
func WriteHeader(db ethdb.Putter, header *types.Header) error {
data, err := rlp.EncodeToBytes(header)
if err != nil {
return err
}
hash := header.Hash().Bytes()
num := header.Number.Uint64()
encNum := encodeBlockNumber(num)
key := append(blockHashPrefix, hash...)
if err := db.Put(key, encNum); err != nil {
log.Crit("Failed to store hash to number mapping", "err", err)
}
key = append(append(headerPrefix, encNum...), hash...)
if err := db.Put(key, data); err != nil {
log.Crit("Failed to store header", "err", err)
}
return nil
}
// WriteBody serializes the body of a block into the database.
func WriteBody(db ethdb.Putter, hash common.Hash, number uint64, body *types.Body) error {
data, err := rlp.EncodeToBytes(body)
if err != nil {
return err
}
return WriteBodyRLP(db, hash, number, data)
}
分为了写头和写区块体两部分。首先对区块头进行了RLP编码,然后将Number转换成为byte格式,然后拼装key。
这个过程中要先存储了hash->Number的值,然后才将区块头的数据写入数据库。
区块体类似,RLP编码,拼装KEY。
再分析一下交易的存储:
目前的以太坊交易在数据库中仅存储交易的元数据:
// TxLookupEntry is a positional metadata to help looking up the data content of
// a transaction or receipt given only its hash.
type TxLookupEntry struct {
BlockHash common.Hash
BlockIndex uint64
Index uint64
}
存储的KV对应为:
txHash(交易哈希)+txMetaSuffix(前缀)->rlpEncode(txMeta)(元数据编码)
写入函数:
// WriteTxLookupEntries stores a positional metadata for every transaction from
// a block, enabling hash based transaction and receipt lookups.
func WriteTxLookupEntries(db ethdb.Putter, block *types.Block) error {
// Iterate over each transaction and encode its metadata
for i, tx := range block.Transactions() {
entry := TxLookupEntry{
BlockHash: block.Hash(),
BlockIndex: block.NumberU64(),
Index: uint64(i),
}
data, err := rlp.EncodeToBytes(entry)
if err != nil {
return err
}
if err := db.Put(append(lookupPrefix, tx.Hash().Bytes()...), data); err != nil {
return err
}
}
return nil
}
遍历交易,构造元数据,RLP编码,然后就可以入库了。
读取代码如下:
// GetTransaction retrieves a specific transaction from the database, along with
// its added positional metadata.
func GetTransaction(db DatabaseReader, hash common.Hash) (*types.Transaction, common.Hash, uint64, uint64) {
// Retrieve the lookup metadata and resolve the transaction from the body
blockHash, blockNumber, txIndex := GetTxLookupEntry(db, hash)
if blockHash != (common.Hash{}) {
body := GetBody(db, blockHash, blockNumber)
if body == nil || len(body.Transactions) <= int(txIndex) {
log.Error("Transaction referenced missing", "number", blockNumber, "hash", blockHash, "index", txIndex)
return nil, common.Hash{}, 0, 0
}
return body.Transactions[txIndex], blockHash, blockNumber, txIndex
}
// Old transaction representation, load the transaction and it's metadata separately
data, _ := db.Get(hash.Bytes())
if len(data) == 0 {
return nil, common.Hash{}, 0, 0
}
var tx types.Transaction
if err := rlp.DecodeBytes(data, &tx); err != nil {
return nil, common.Hash{}, 0, 0
}
// Retrieve the blockchain positional metadata
data, _ = db.Get(append(hash.Bytes(), oldTxMetaSuffix...))
if len(data) == 0 {
return nil, common.Hash{}, 0, 0
}
var entry TxLookupEntry
if err := rlp.DecodeBytes(data, &entry); err != nil {
return nil, common.Hash{}, 0, 0
}
return &tx, entry.BlockHash, entry.BlockIndex, entry.Index
}
先通过交易哈希得到元数据入口,再查找块哈希,然后从块上找到交易的具体信息返回,或者如果是老的版本,则处理一下再返回。
也就是说,这个函数支持新旧两个版本的交易查询。
这样区块也就基本分析完成了。
如果对区块链和c++感兴趣,欢迎关注:
