Python 并行分布式框架 Celery
Celery 官网:http://www.celeryproject.org
Celery 官方文档英文版:http://docs.celeryproject.org/en/latest/index.html
Celery 官方文档中文版:http://docs.jinkan.org/docs/celery
celery配置:http://docs.jinkan.org/docs/celery/configuration.html#configuration
参考:http://www.cnblogs.com/landpack/p/5564768.html http://blog.csdn.net/happyAnger6/article/details/51408266
http://www.cnblogs.com/forward-wang/p/5970806.html
分布式队列神器 Celery:https://segmentfault.com/a/1190000008022050
celery最佳实践:https://my.oschina.net/siddontang/blog/284107
Celery 分布式任务队列快速入门:http://www.cnblogs.com/alex3714/p/6351797.html
异步任务神器 Celery 快速入门教程:https://blog.csdn.net/chenqiuge1984/article/details/80127446
定时任务管理之python篇celery使用:http://student-lp.iteye.com/blog/2093397
异步任务神器 Celery:http://python.jobbole.com/87086/
celery任务调度框架实践:https://blog.csdn.net/qq_28921653/article/details/79555212
Celery-4.1 用户指南: Monitoring and Management Guide:https://blog.csdn.net/libing_thinking/article/details/78592801
Celery安装及使用:https://blog.csdn.net/u012325060/article/details/79292243
Celery学习笔记(一):https://blog.csdn.net/sdulsj/article/details/73741350
Celery 简介
除了redis,还可以使用另外一个神器---Celery。Celery是一个异步任务的调度工具。
Celery 是 Distributed Task Queue,分布式任务队列,分布式决定了可以有多个 worker 的存在,队列表示其是异步操作,即存在一个产生任务提出需求的工头,和一群等着被分配工作的码农。
在 Python 中定义 Celery 的时候,我们要引入 Broker,中文翻译过来就是“中间人”的意思,在这里 Broker 起到一个中间人的角色。在工头提出任务的时候,把所有的任务放到 Broker 里面,在 Broker 的另外一头,一群码农等着取出一个个任务准备着手做。
这种模式注定了整个系统会是个开环系统,工头对于码农们把任务做的怎样是不知情的。所以我们要引入 Backend 来保存每次任务的结果。这个 Backend 有点像我们的 Broker,也是存储任务的信息用的,只不过这里存的是那些任务的返回结果。我们可以选择只让错误执行的任务返回结果到 Backend,这样我们取回结果,便可以知道有多少任务执行失败了。
Celery(芹菜)是一个异步任务队列/基于分布式消息传递的作业队列。它侧重于实时操作,但对调度支持也很好。Celery用于生产系统每天处理数以百万计的任务。Celery是用Python编写的,但该协议可以在任何语言实现。它也可以与其他语言通过webhooks实现。Celery建议的消息队列是RabbitMQ,但提供有限支持Redis, Beanstalk, MongoDB, CouchDB, 和数据库(使用SQLAlchemy的或Django的 ORM) 。Celery是易于集成Django, Pylons and Flask,使用 django-celery, celery-pylons and Flask-Celery 附加包即可。
Celery 介绍
在Celery中几个基本的概念,需要先了解下,不然不知道为什么要安装下面的东西。概念:Broker、Backend。
什么是broker?
broker是一个消息传输的中间件,可以理解为一个邮箱。每当应用程序调用celery的异步任务的时候,会向broker传递消息,而后celery的worker将会取到消息,进行对于的程序执行。好吧,这个邮箱可以看成是一个消息队列。其中Broker的中文意思是 经纪人 ,其实就是一开始说的 消息队列 ,用来发送和接受消息。这个Broker有几个方案可供选择:RabbitMQ (消息队列),Redis(缓存数据库),数据库(不推荐),等等
什么是backend?
通常程序发送的消息,发完就完了,可能都不知道对方时候接受了。为此,celery实现了一个backend,用于存储这些消息以及celery执行的一些消息和结果。Backend是在Celery的配置中的一个配置项 CELERY_RESULT_BACKEND ,作用是保存结果和状态,如果你需要跟踪任务的状态,那么需要设置这一项,可以是Database backend,也可以是Cache backend,具体可以参考这里: CELERY_RESULT_BACKEND 。
对于 brokers,官方推荐是 rabbitmq 和 redis,至于 backend,就是数据库。为了简单可以都使用 redis。
我自己演示使用RabbitMQ作为Broker,用MySQL作为backend。
来一张图,这是在网上最多的一张Celery的图了,确实描述的非常好
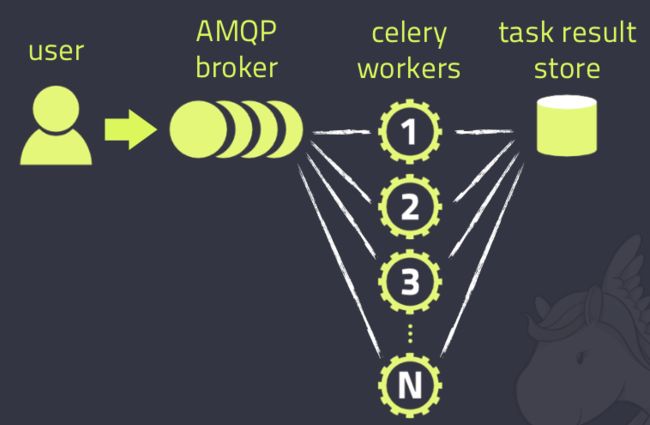
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。包括,RabbitMQ, Redis, MongoDB (experimental), Amazon SQS (experimental),CouchDB (experimental), SQLAlchemy (experimental),Django ORM (experimental), IronMQ
任务执行单元
Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
任务结果存储
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP, redis,memcached, mongodb,SQLAlchemy, Django ORM,Apache Cassandra, IronCache 等。
这里我先不去看它是如何存储的,就先选用redis来存储任务执行结果。
因为涉及到消息中间件(在Celery帮助文档中称呼为中间人
根据 Celery的帮助文档 安装和设置RabbitMQ, 要使用 Celery,需要创建一个 RabbitMQ 用户、一个虚拟主机,并且允许这个用户访问这个虚拟主机。
$ sudo rabbitmqctl add_user forward password #创建了一个RabbitMQ用户,用户名为forward,密码是password
$ sudo rabbitmqctl add_vhost ubuntu #创建了一个虚拟主机,主机名为ubuntu
# 设置权限。允许用户forward访问虚拟主机ubuntu,因为RabbitMQ通过主机名来与节点通信
$ sudo rabbitmqctl set_permissions -p ubuntu forward ".*" ".*" ".*"
$ sudo rabbitmq-server # 启用RabbitMQ服务器结果如下,成功运行:
安装Redis,它的安装比较简单
$ sudo pip install redis然后进行简单的配置,只需要设置 Redis 数据库的位置:
BROKER_URL = 'redis://localhost:6379/0'
URL的格式为:
redis://:password@hostname:port/db_number
URL Scheme 后的所有字段都是可选的,并且默认为 localhost 的 6479 端口,使用数据库 0。我的配置是:
redis://:password@ubuntu:6379/5
安装Celery,我是用标准的Python工具pip安装的,如下:
$ sudo pip install celery
Celery 是一个强大的 分布式任务队列 的 异步处理框架,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他主机上运行。我们通常使用它来实现异步任务(async task)和定时任务(crontab)。我们需要一个消息队列来下发我们的任务。首先要有一个消息中间件,此处选择rabbitmq (也可选择 redis 或 Amazon Simple Queue Service(SQS)消息队列服务)。推荐 选择 rabbitmq 。使用RabbitMQ是官方特别推荐的方式,因此我也使用它作为我们的broker。它的架构组成如下图:
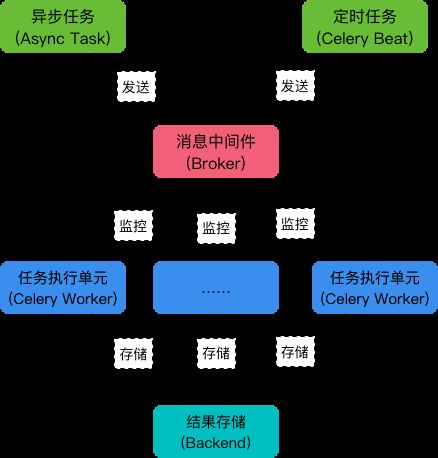
可以看到,Celery 主要包含以下几个模块:
-
任务模块 Task
包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往任务队列,而定时任务由 Celery Beat 进程周期性地将任务发往任务队列。
-
消息中间件 Broker
Broker,即为任务调度队列,接收任务生产者发来的消息(即任务),将任务存入队列。Celery 本身不提供队列服务,官方推荐使用 RabbitMQ 和 Redis 等。
-
任务执行单元 Worker
Worker 是执行任务的处理单元,它实时监控消息队列,获取队列中调度的任务,并执行它。
-
任务结果存储 Backend
Backend 用于存储任务的执行结果,以供查询。同消息中间件一样,存储也可使用 RabbitMQ, redis 和 MongoDB 等。
安装
有了上面的概念,需要安装这么几个东西:RabbitMQ、SQLAlchemy、Celery
安装rabbitmq
官网安装方法:http://www.rabbitmq.com/install-windows.html
启动管理插件:sbin/rabbitmq-plugins enable rabbitmq_management
启动rabbitmq:sbin/rabbitmq-server -detached
rabbitmq已经启动,可以打开页面来看看
地址:http://localhost:15672/#/
用户名密码都是guest 。现在可以进来了,可以看到具体页面。 关于rabbitmq的配置,网上很多 自己去搜以下就ok了。
消息中间件有了,现在该来代码了,使用 celeby官网代码。
剩下两个都是Python的东西了,直接pip安装就好了,对于从来没有安装过mysql驱动的同学可能需要安装MySQL-python。安装完成之后,启动服务: $ rabbitmq-server[回车]。启动后不要关闭窗口, 下面操作新建窗口(Tab)。
安装celery
Celery可以通过pip自动安装,如果你喜欢使用虚拟环境安装可以先使用virtualenv创建一个自己的虚拟环境。反正我喜欢使用virtualenv建立自己的环境。
pip install celery
http://www.open-open.com/lib/view/open1441161168878.html
开始使用 Celery
使用celery包含三个方面:1. 定义任务函数。2. 运行celery服务。3. 客户应用程序的调用。
创建一个文件 tasks.py输入下列代码:
from celery import Celery
broker = 'redis://127.0.0.1:6379/5'
backend = 'redis://127.0.0.1:6379/6'
app = Celery('tasks', broker=broker, backend=backend)
@app.task
def add(x, y):
return x + y上述代码导入了celery,然后创建了celery 实例 app,实例化的过程中指定了任务名tasks(和文件名一致),传入了broker和backend。然后创建了一个任务函数add。下面启动celery服务。在当前命令行终端运行(分别在 env1 和 env2 下执行):
celery -A tasks worker --loglevel=info目录结构 (celery -A tasks worker --loglevel=info 这条命令当前工作目录必须和 tasks.py 所在的目录相同。即 进入tasks.py所在目录执行这条命令。)
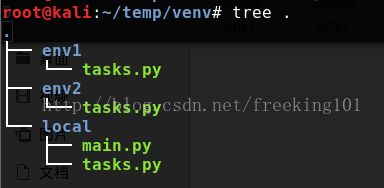
使用 python 虚拟环境 模拟两个不同的 主机。
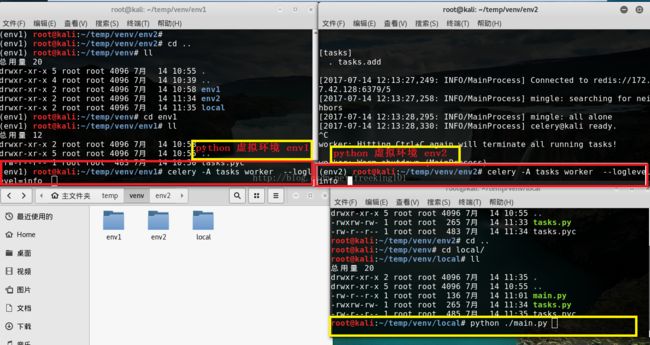
此时会看见一对输出。包括注册的任务啦。
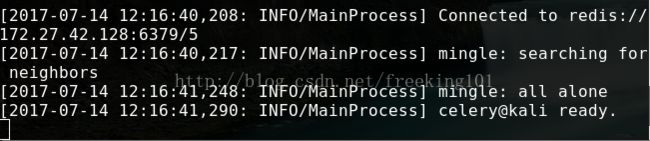
交互式客户端程序调用方法
打开一个命令行,进入Python环境。
In [0]:from tasks import add
In [1]: r = add.delay(2, 2)
In [2]: add.delay(2, 2)
Out[2]:
In [3]: r = add.delay(3, 3)
In [4]: r.re
r.ready r.result r.revoke
In [4]: r.ready()
Out[4]: True
In [6]: r.result
Out[6]: 6
In [7]: r.get()
Out[7]: 6 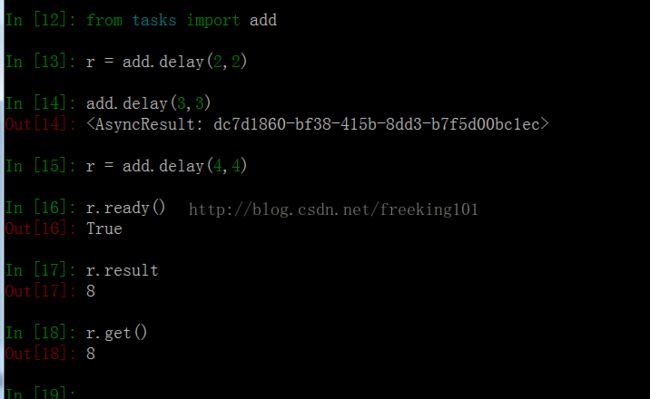
调用 delay 函数即可启动 add 这个任务。这个函数的效果是发送一条消息到broker中去,这个消息包括要执行的函数、函数的参数以及其他信息,具体的可以看 Celery官方文档。这个时候 worker 会等待 broker 中的消息,一旦收到消息就会立刻执行消息。
启动了一个任务之后,可以看到之前启动的worker已经开始执行任务了。

现在是在python环境中调用的add函数,实际上通常在应用程序中调用这个方法。
注意:如果把返回值赋值给一个变量,那么原来的应用程序也会被阻塞,需要等待异步任务返回的结果。因此,实际使用中,不需要把结果赋值。
应用程序中调用方法
新建一个 main.py 文件 代码如下:
from tasks import add
r = add.delay(2, 2)
r = add.delay(3, 3)
print r.ready()
print r.result
print r.get() 
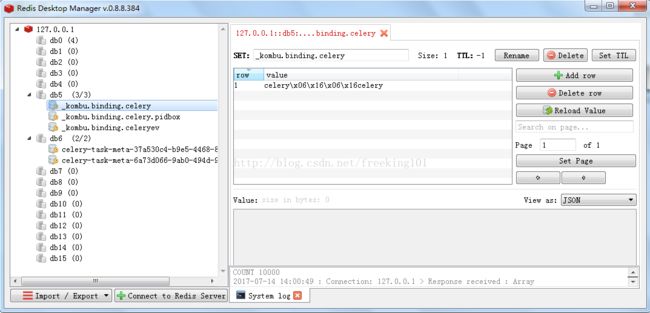
在celery命令行可以看见celery执行的日志。打开 backend的redis,也可以看见celery执行的信息。
使用 Redis Desktop Manager 查看 Redis 数据库内容如图:
使用配置文件
Celery 的配置比较多,可以在 官方配置文档:http://docs.celeryproject.org/en/latest/userguide/configuration.html 查询每个配置项的含义。
上述的使用是简单的配置,下面介绍一个更健壮的方式来使用celery。首先创建一个python包,celery服务,姑且命名为proj。目录文件如下:
☁ proj tree
.
├── __init__.py
├── celery.py # 创建 celery 实例
├── config.py # 配置文件
└── tasks.py # 任务函数首先是 celery.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from celery import Celery
app = Celery('proj', include=['proj.tasks'])
app.config_from_object('proj.config')
if __name__ == '__main__':
app.start()这一次创建 app,并没有直接指定 broker 和 backend。而是在配置文件中。
config.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
BROKER_URL = 'redis://127.0.0.1:6379/6'剩下的就是tasks.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from proj.celery import app
@app.task
def add(x, y):
return x + y使用方法也很简单,在 proj 的同一级目录执行 celery:
celery -A proj worker -l info现在使用任务也很简单,直接在客户端代码调用 proj.tasks 里的函数即可。
指定 路由 到的 队列
Celery的官方文档 。先看代码(tasks.py):
from celery import Celery
app = Celery()
app.config_from_object("celeryconfig")
@app.task
def taskA(x,y):
return x + y
@app.task
def taskB(x,y,z):
return x + y + z
@app.task
def add(x,y):
return x + y上面的tasks.py中,首先定义了一个Celery对象,然后用celeryconfig.py对celery对象进行设置,之后再分别定义了三个task,分别是taskA,taskB和add。接下来看一下celeryconfig.py 文件
from kombu import Exchange,Queue
BROKER_URL = "redis://10.32.105.227:6379/0" CELERY_RESULT_BACKEND = "redis://10.32.105.227:6379/0"
CELERY_QUEUES = (
Queue("default",Exchange("default"),routing_key="default"),
Queue("for_task_A",Exchange("for_task_A"),routing_key="task_a"),
Queue("for_task_B",Exchange("for_task_B"),routing_key="task_a")
)
CELERY_ROUTES = {
'tasks.taskA':{"queue":"for_task_A","routing_key":"task_a"},
'tasks.taskB":{"queue":"for_task_B","routing_key:"task_b"}
} 在 celeryconfig.py 文件中,首先设置了brokel以及result_backend,接下来定义了三个Message Queue,并且指明了Queue对应的Exchange(当使用Redis作为broker时,Exchange的名字必须和Queue的名字一样)以及routing_key的值。
现在在一台主机上面启动一个worker,这个worker只执行for_task_A队列中的消息,这是通过在启动worker是使用-Q Queue_Name参数指定的。
celery -A tasks worker -l info -n worker.%h -Q for_task_A然后到另一台主机上面执行taskA任务。首先 切换当前目录到代码所在的工程下,启动python,执行下面代码启动taskA:
from tasks import *
task_A_re = taskA.delay(100,200)执行完上面的代码之后,task_A消息会被立即发送到for_task_A队列中去。此时已经启动的worker.atsgxxx 会立即执行taskA任务。
重复上面的过程,在另外一台机器上启动一个worker专门执行for_task_B中的任务。修改上一步骤的代码,把 taskA 改成 taskB 并执行。
from tasks import *
task_B_re = taskB.delay(100,200)在上面的 tasks.py 文件中还定义了add任务,但是在celeryconfig.py文件中没有指定这个任务route到那个Queue中去执行,此时执行add任务的时候,add会route到Celery默认的名字叫做celery的队列中去。
因为这个消息没有在celeryconfig.py文件中指定应该route到哪一个Queue中,所以会被发送到默认的名字为celery的Queue中,但是我们还没有启动worker执行celery中的任务。接下来我们在启动一个worker执行celery队列中的任务。
celery -A tasks worker -l info -n worker.%h -Q celery 然后再查看add的状态,会发现状态由PENDING变成了SUCCESS。
Scheduler ( 定时任务,周期性任务 )
http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html
一种常见的需求是每隔一段时间执行一个任务。
在celery中执行定时任务非常简单,只需要设置celery对象的CELERYBEAT_SCHEDULE属性即可。
配置如下
config.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
BROKER_URL = 'redis://127.0.0.1:6379/6'
CELERY_TIMEZONE = 'Asia/Shanghai'
from datetime import timedelta
CELERYBEAT_SCHEDULE = {
'add-every-30-seconds': {
'task': 'proj.tasks.add',
'schedule': timedelta(seconds=30),
'args': (16, 16)
},
}注意配置文件需要指定时区。这段代码表示每隔30秒执行 add 函数。一旦使用了 scheduler, 启动 celery需要加上-B 参数。
celery -A proj worker -B -l info设置多个定时任务
CELERY_TIMEZONE = 'UTC'
CELERYBEAT_SCHEDULE = {
'taskA_schedule' : {
'task':'tasks.taskA',
'schedule':20,
'args':(5,6)
},
'taskB_scheduler' : {
'task':"tasks.taskB",
"schedule":200,
"args":(10,20,30)
},
'add_schedule': {
"task":"tasks.add",
"schedule":10,
"args":(1,2)
}
}定义3个定时任务,即每隔20s执行taskA任务,参数为(5,6),每隔200s执行taskB任务,参数为(10,20,30),每隔10s执行add任务,参数为(1,2).通过下列命令启动一个定时任务: celery -A tasks beat。使用 beat 参数即可启动定时任务。
crontab
计划任务当然也可以用crontab实现,celery也有crontab模式。修改 config.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
BROKER_URL = 'redis://127.0.0.1:6379/6'
CELERY_TIMEZONE = 'Asia/Shanghai'
from celery.schedules import crontab
CELERYBEAT_SCHEDULE = {
# Executes every Monday morning at 7:30 A.M
'add-every-monday-morning': {
'task': 'tasks.add',
'schedule': crontab(hour=7, minute=30, day_of_week=1),
'args': (16, 16),
},
}scheduler的切分度很细,可以精确到秒。crontab模式就不用说了。
当然celery还有更高级的用法,比如 多个机器 使用,启用多个 worker并发处理 等。
发送任务到队列中
apply_async(args[, kwargs[, …]])、delay(*args, **kwargs) :http://docs.celeryproject.org/en/master/userguide/calling.html
send_task :http://docs.celeryproject.org/en/master/reference/celery.html#celery.Celery.send_task
from celery import Celery
celery = Celery()
celery.config_from_object('celeryconfig')
send_task('tasks.test1', args=[hotplay_id, start_dt, end_dt], queue='hotplay_jy_queue')
Celery 监控 和 管理 以及 命令帮助
输入 celery -h 可以看到 celery 的命令和帮助
更详细的帮助可以看官方文档:http://docs.celeryproject.org/en/master/userguide/monitoring.html
Celery 官网 示例
官网示例:http://docs.celeryproject.org/en/master/getting-started/first-steps-with-celery.html#first-steps
Python 并行分布式框架 Celery 超详细介绍
一个简单例子
第一步
编写简单的纯python函数
def say(x,y):
return x+y
if __name__ == '__main__':
say('Hello','World')
第二步
如果这个函数不是简单的输出两个字符串相加,而是需要查询数据库或者进行复杂的处理。这种处理需要耗费大量的时间,还是这种方式执行会是多么糟糕的事情。为了演示这种现象,可以使用sleep函数来模拟高耗时任务。
import time
def say(x,y):
time.sleep(5)
return x+y
if __name__ == '__main__':
say('Hello','World')
第三步
这时候我们可能会思考怎么使用多进程或者多线程去实现这种任务。对于多进程与多线程的不足这里不做讨论。现在我们可以想想celery到底能不能解决这种问题。
import time
from celery import Celery
app = Celery('sample',broker='amqp://guest@localhost//')
@app.task
def say(x,y):
time.sleep(5)
return x+y
if __name__ == '__main__':
say('Hello','World')现在来解释一下新加入的几行代码,首先说明一下加入的新代码完全不需要改变原来的代码。导入celery模块就不用解释了,声明一个celery实例app的参数需要解释一下。
- 第一个参数是这个python文件的名字,注意到已经把.py去掉了。
- 第二个参数是用到的rabbitmq队列。可以看到其使用的方式非常简单,因为它是默认的消息队列端口号都不需要指明。
第四步
现在我们已经使用了celery框架了,我们需要让它找几个工人帮我们干活。好现在就让他们干活。
celery -A sample worker --loglevel=info这条命令有些长,我来解释一下吧。
- -A 代表的是Application的首字母,我们的应用就是在 sample 里面 定义的。
- worker 就是我们的工人了,他们会努力完成我们的工作的。
- -loglevel=info 指明了我们的工作后台执行情况,虽然工人们已经向你保证过一定努力完成任务。但是谨慎的你还是希望看看工作进展情况。
回车后你可以看到类似下面这样一个输出,如果是没有红色的输出那么你应该是没有遇到什么错误的。
第五步
现在我们的任务已经被加载到了内存中,我们不能再像之前那样执行python sample.py来运行程序了。我们可以通过终端进入python然后通过下面的方式加载任务。输入python语句。
from sample import say
say.delay('hello','world')我们的函数会立即返回,不需要等待。就那么简单celery解决了我们的问题。可以发现我们的say函数不是直接调用了,它被celery 的 task 装饰器 修饰过了。所以多了一些属性。目前我们只需要知道使用delay就行了。
简单案例
确保你之前的RabbitMQ已经启动。还是官网的那个例子,在任意目录新建一个tasks.py的文件,内容如下:
from celery import Celery
app = Celery('tasks', broker='amqp://guest@localhost//')
@app.task
def add(x, y):
return x + y使用redis作为消息队列
app = Celery('task', broker='redis://localhost:6379/4')
app.conf.update(
CELERY_TASK_SERIALIZER='json',
CELERY_ACCEPT_CONTENT=['json'], # Ignore other content
CELERY_RESULT_SERIALIZER='json',
CELERYD_CONCURRENCY = 8
)
@app.task
def add(x, y):
return x + y 在同级目录执行:
$ celery -A tasks.app worker --loglevel=info该命令的意思是启动一个worker ( tasks文件中的app实例,默认实例名为app,-A 参数后也可直接加文件名,不需要 .app),把tasks中的任务(add(x,y))把任务放到队列中。保持窗口打开,新开一个窗口进入交互模式,python或者ipython:
>>> from tasks import add
>>> add.delay(4, 4)到此为止,你已经可以使用celery执行任务了,上面的python交互模式下简单的调用了add任务,并传递 4,4 参数。
但此时有一个问题,你突然想知道这个任务的执行结果和状态,到底完了没有。因此就需要设置backend了
修改之前的tasks.py中的代码为:
# coding:utf-8
import subprocess
from time import sleep
from celery import Celery
backend = 'db+mysql://root:@192.168.0.102/celery'
broker = 'amqp://[email protected]:5672'
app = Celery('tasks', backend=backend, broker=broker)
@app.task
def add(x, y):
sleep(10)
return x + y
@app.task
def hostname():
return subprocess.check_output(['hostname'])除了添加backend之外,上面还添加了一个who的方法用来测试多服务器操作。修改完成之后,还按之前的方式启动。
同样进入python的交互模型:
>>> from tasks import add, hostname
>>> r = add.delay(4, 4)
>>> r.ready() # 10s内执行,会输出False,因为add中sleep了10s
>>>
>>> r = hostname.delay()
>>> r.result # 输出你的hostname
测试多服务器
做完上面的测试之后,产生了一个疑惑,Celery叫做分布式任务管理,那它的分布式体现在哪?它的任务都是怎么执行的?在哪个机器上执行的?在当前服务器上的celery服务不关闭的情况下,按照同样的方式在另外一台服务器上安装Celery,并启动:
$ celery -A tasks worker --loglevel=info发现前一个服务器的Celery服务中输出你刚启动的服务器的hostname,前提是那台服务器连上了你的rabbitmq。然后再进入python交互模式:
>>> from tasks import hostname
>>>
>>> for i in range(10):
... r = hostname.delay()
... print r.result # 输出你的hostname
>>>看你输入的内容已经观察两台服务器上你启动celery服务的输出。
Celery的使用技巧(Celery配置文件和发送任务)
在实际的项目中我们需要明确前后台的分界线,因此我们的celery编写的时候就应该是分成前后台两个部分编写。在celery简单入门中的总结部分我们也提出了另外一个问题,就是需要分离celery的配置文件。
第一步
编写后台任务tasks.py脚本文件。在这个文件中我们不需要再声明celery的实例,我们只需要导入其task装饰器来注册我们的任务即可。后台处理业务逻辑完全独立于前台,这里只是简单的hello world程序需要多少个参数只需要告诉前台就可以了,在实际项目中可能你需要的是后台执行发送一封邮件的任务或者进行复杂的数据库查询任务等。
import time
from celery.task import task
@task
def say(x,y):
time.sleep(5)
return x+y第二步
有了那么完美的后台,我们的前台编写肯定也轻松不少。到底简单到什么地步呢,来看看前台的代码吧!为了形象的表明其职能,我们将其命名为client.py脚本文件。
from celery import Celery
app = Celery()
app.config_from_object('celeryconfig')
app.send_task("tasks.say",['hello','world'])可以看到只需要简单的几步:1. 声明一个celery实例。2. 加载配置文件。3. 发送任务。
第三步
继续完成celery的配置。官方的介绍使用celeryconfig.py作为配置文件名,这样可以防止与你现在的应用的配置同名。
CELERY_IMPORTS = ('tasks')
CELERY_IGNORE_RESULT = False
BROKER_HOST = '127.0.0.1'
BROKER_PORT = 5672
BROKER_URL = 'amqp://'
CELERY_RESULT_BACKEND = 'amqp'可以看到我们指定了CELERY_RESULT_BACKEND为amqp默认的队列!这样我们就可以查看处理后的运行状态了,后面将会介绍处理结果的查看。
第四步
启动celery后台服务,这里是测试与学习celery的教程。在实际生产环境中,如果是通过这种方式启动的后台进程是不行的。所谓后台进程通常是需要作为守护进程运行在后台的,在python的世界里总是有一些工具能够满足你的需要。这里可以使用supervisor作为进程管理工具。在后面的文章中将会介绍如何使用supervisor工具。
celery worker -l info --beat注意现在运行worker的方式也与前面介绍的不一样了,下面简单介绍各个参数。
-l info 与--loglevel=info的作用是一样的。
--beat 周期性的运行。即设置 心跳。
第五步
前台的运行就比较简单了,与平时运行的python脚本一样。python client.py。
现在前台的任务是运行了,可是任务是被写死了。我们的任务大多数时候是动态的,为演示动态工作的情况我们可以使用终端发送任务。
>>> from celery import Celery
>>> app = Celery()
>>> app.config_from_object('celeryconfig')在python终端导入celery模块声明实例然后加载配置文件,完成了这些步骤后就可以动态的发送任务并且查看任务状态了。注意在配置文件celeryconfig.py中我们已经开启了处理的结果回应模式了CELERY_IGNORE_RESULT = False并且在回应方式配置中我们设置了CELERY_RESULT_BACKEND = 'amqp'这样我们就可以查看到处理的状态了。
>>> x = app.send_task('task.say',['hello', 'lady'])
>>> x.ready()
False
>>> x.status
'PENDING'
>>> x.ready()
TRUE
>>> x.status
u'SUCCESS'可以看到任务发送给celery后马上查看任务状态会处于PENDING状态。稍等片刻就可以查看到SUCCESS状态了。这种效果真棒不是吗?在图像处理中或者其他的一些搞耗时的任务中,我们只需要把任务发送给后台就不用去管它了。当我们需要结果的时候只需要查看一些是否成功完成了,如果返回成功我们就可以去后台数据库去找处理后生成的数据了。
celery使用mangodb保存数据
第一步
安装好mongodb了!就可以使用它了,首先让我们修改celeryconfig.py文件,使celery知道我们有一个新成员要加入我们的项目,它就是mongodb配置的方式如下。
ELERY_IMPORTS = ('tasks')
CELERY_IGNORE_RESULT = False
BROKER_HOST = '127.0.0.1'
BROKER_PORT = 5672
BROKER_URL = 'amqp://'
#CELERY_RESULT_BACKEND = 'amqp'
CELERY_RESULT_BACKEND = 'mongodb'
CELERY_RESULT_BACKEND_SETTINGS = {
"host":"127.0.0.1",
"port":27017,
"database":"jobs",
"taskmeta_collection":"stock_taskmeta_collection",
}把#CELERY_RESULT_BACKEND = 'amp'注释掉了,但是没有删除目的是对比前后的改变。为了使用mongodb我们有简单了配置一下主机端口以及数据库名字等。显然你可以按照你喜欢的名字来配置它。
第二步
启动 mongodb 数据库:mongod。修改客户端client.py让他能够动态的传人我们的数据,非常简单代码如下。
import sys
from celery import Celery
app = Celery()
app.config_from_object('celeryconfig')
app.send_task("tasks.say",[sys.argv[1],sys.argv[2]])任务tasks.py不需要修改!
import time
from celery.task import task
@task
def say(x,y):
time.sleep(5)
return x+y第三步
测试代码,先启动celery任务。
celery worker -l info --beat再来启动我们的客户端,注意这次启动的时候需要给两个参数啦!
mongo
python client.py welcome landpack等上5秒钟,我们的后台处理完成后我们就可以去查看数据库了。
第四步
查看mongodb,需要启动一个mongodb客户端,启动非常简单直接输入 mongo 。然后是输入一些简单的mongo查询语句。
最后查到的数据结果可能是你不想看到的,因为mongo已经进行了处理。想了解更多可以查看官方的文档。