Python学习---第1天---语法、循环、数据结构
一、布尔运算
因为Python把0、空字符串''和None看成 False,其他数值和非空字符串都看成 True,所以:
True and 'a=T' 计算结果是 'a=T'
继续计算 'a=T' or 'a=F' 计算结果还是 'a=T'
要解释上述结果,又涉及到 and 和 or 运算的一条重要法则:短路计算。
1. 在计算 a and b 时,如果 a 是 False,则根据与运算法则,整个结果必定为 False,因此返回 a;如果 a 是 True,则整个计算结果必定取决与 b,因此返回 b。
2. 在计算 a or b 时,如果 a 是 True,则根据或运算法则,整个计算结果必定为 True,因此返回 a;如果 a 是 False,则整个计算结果必定取决于 b,因此返回 b。
所以Python解释器在做布尔运算时,只要能提前确定计算结果,它就不会往后算了,直接返回结果。
二、list列表
1、创建
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,就可以用一个list表示:
>>> ['Michael', 'Bob', 'Tracy']
['Michael', 'Bob', 'Tracy']
list是数学意义上的有序集合,也就是说,list中的元素是按照顺序排列的。
构造list非常简单,按照上面的代码,直接用 [ ] 把list的所有元素都括起来,就是一个list对象。通常,我们会把list赋值给一个变量,这样,就可以通过变量来引用list:
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates # 打印classmates变量的内容
['Michael', 'Bob', 'Tracy']
由于Python是动态语言,所以list中包含的元素并不要求都必须是同一种数据类型,我们完全可以在list中包含各种数据:
>>> L = ['Michael', 100, True]
一个元素也没有的list,就是空list:
>>> empty_list = []
2、访问
L = [95.5, 85, 59]
print L[-1] #输出倒数第一
print L[-2] #输出倒数第二
print L[-3] #输出倒数第三,注意!不要输出倒数第四,否则会报数组下标越界异常
print L[0] #输出顺数第一,以下类推
print L[1]
print L[2]
3、添加新元素
yang= [95.5, 85, 59]
yang.append("zhang san feng") #追加元素到末尾
yang.insert(0, "diyi ") #插入元素到指定的位置,原来位置及其以后的元素全部向后移动一个位置
4、从list删除元素

五、替换元素
yang= ["zhangSan", "LiSI", "wang Wu"]
yang[-1]="new" #直接给对应的位置直接重新赋值即可
print yang
三、tuple
1、tuple数组
tuple是另一种有序的列表,中文翻译为“ 元组 ”。tuple 和 list 非常类似,但是,tuple一旦创建完毕,就不能修改了。同样是表示班里同学的名称,用tuple表示如下:
>>> t = ('Adam', 'Lisa', 'Bart')
创建tuple和创建list唯一不同之处是用( )替代了[ ]。
现在,这个 t 就不能改变了,tuple没有 append()方法,也没有insert()和pop()方法。所以,新同学没法直接往 tuple 中添加,老同学想退出 tuple 也不行。
获取 tuple 元素的方式和 list 是一模一样的,我们可以正常使用 t[0],t[-1]等索引方式访问元素,但是不能赋值成别的元素,不信可以试试:
>>> t[0] = 'Paul'会报错的
2、创建单元素tuple
t=(1)
Print t #输出数字 1
因为()既可以表示tuple,又可以作为括号表示运算时的优先级,结果 (1) 被Python解释器计算出结果 为数字1,导致我们得到的不是tuple,而是整数 1。
正是因为用()定义单元素的tuple有歧义,所以 Python 规定,单元素 tuple 要多加一个逗号“,”,这样就避免了歧义:
>>> t = (1,)
>>> print t
(1,)
Python在打印单元素tuple时,也自动添加了一个“,”,为了更明确地告诉你这是一个tuple。
多元素 tuple 加不加这个额外的“,”效果是一样的:
>>> t = (1, 2, 3,)
>>> print t
(1, 2, 3)
3、“可变”的tuple
前面我们看到了tuple一旦创建就不能修改。现在,我们来看一个“可变”的tuple:
>>> t = ('a', 'b', ['A', 'B'])
注意到 t 有 3 个元素:'a','b'和一个list:['A', 'B']。list作为一个整体是tuple的第3个元素。list对象可以通过 t[2] 拿到:
>>> L = t[2]
然后,我们把list的两个元素改一改:
>>> L[0] = 'X'
>>> L[1] = 'Y'
再看看tuple的内容:
>>> print t
('a', 'b', ['X', 'Y'])
不是说tuple一旦定义后就不可变了吗?怎么现在又变了?
别急,我们先看看定义的时候tuple包含的3个元素:
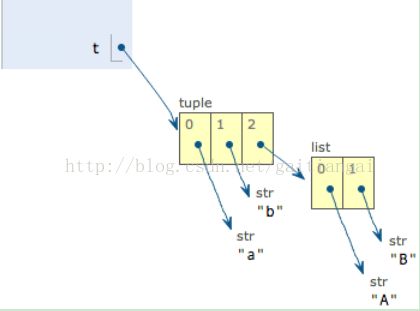
当我们把list的元素'A'和'B'修改为'X'和'Y'后,tuple变为:
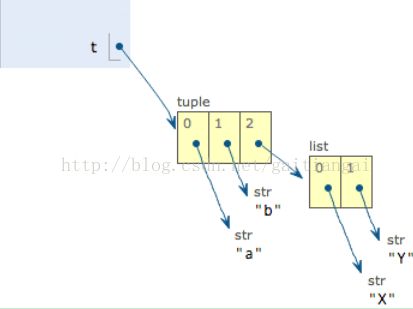
表面上看,tuple的元素确实变了,但其实变的不是 tuple 的元素,而是list的元素。
tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
理解了“指向不变”后,要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变。
四、if语句
相同缩进的是一个代码块
age=10
if age>=10 :
print 'age is :',age
print ‘我也属于这个if成立的代码块’
print '我不属于IF成立的代码块’
注意: Python代码的缩进规则。具有相同缩进的代码被视为代码块,上面的3,4行 print 语句就构成一个代码块(但不包括第5行的print)。如果 if 语句判断为 True,就会执行这个代码块。
缩进请严格按照Python的习惯写法:4个空格,不要使用Tab,更不要混合Tab和空格,否则很容易造成因为缩进引起的语法错误。
注意: if 语句后接表达式,然后用 : 表示代码块开始。
五、if-else
age=10
if age<18:
print "teenager"
else:
print "adult"
利用 if ... else ... 语句,我们可以根据条件表达式的值为 True 或者False ,分别执行 if 代码块或者 else 代码块。
注意: else 后面有个“:”。
六、if-elif-else
Age=1
if age>18:
print "adult"
elif age>=6:
print "kid"
elif age>3:
print "child"
else:
print "baby"
elif 意思就是 else if。这样一来,我们就写出了结构非常清晰的一系列条件判断。
特别注意: 这一系列条件判断会从上到下依次判断,如果某个判断为 True,执行完对应的代码块,后面的条件判断就直接忽略,不再执行了。
七、for循环
yang=["zhang san",'li si','wang wu','er gou',100]
for name in yang:
print name
注意: name 这个变量是在 for 循环中定义的,意思是,依次取出list中的每一个元素,并把元素赋值给 name,然后执行for循环体(就是缩进的代码块)。
这样一来,遍历一个list或tuple就非常容易了。
八、while循环
和 for 循环不同的另一种循环是 while 循环,while 循环不会迭代 list 或 tuple 的元素,而是根据表达式判断循环是否结束。
比如要从 0 开始打印不大于 N 的整数:
N = 10
x = 0
while x < N:
print x
x = x + 1
九、break退出循环
用 for 循环或者 while 循环时,如果要在循环体内直接退出循环,可以使用 break 语句。
比如计算1至100的整数和,我们用while来实现:
sum = 0
x = 1
while True:
sum = sum + x
x = x + 1
if x > 100:
break
print sum
咋一看, while True 就是一个死循环,但是在循环体内,我们还判断了 x > 100 条件成立时,用break语句退出循环,这样也可以实现循环的结束。
十、continue继续循环
统计及格分数的平均分
L = [60, -98, 59, 41, 23, 43, 70, 80]
sum=0
n=0
for x in L:
if x < 60:
发 continue #结束本次循环,不结束这个循环
sum = sum + x
n = n + 1
print sum/n
十一、多重循环
在循环内部,还可以嵌套循环,我们来看一个例子:
for x in ['A', 'B', 'C']:
for y in ['1', '2', '3']:
print x + y
x 每循环一次,y 就会循环 3 次,这样,我们可以打印出一个全排列:
A1
A2
A3
B1
B2
B3
C1
C2
C3
十二、什么是dict
存放键值对:
'Adam' ==> 95
'Lisa' ==> 85
'Bart' ==> 59
给定一个名字,就可以直接查到分数。
Python的 dict 就是专门干这件事的。用 dict 表示“名字”-“成绩”的查找表如下:
创建:(类比json)
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
使用:
list 必须使用索引返回对应的元素,而dict使用key:
1、x=d['Lisa']
2、print d.get('Lisa') #输出为85
3、d["yang"]=100 #存在yang这个键的话就替换原来的值,不存在的话就新建一个键值对,此时相当于插入
4、遍历
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
for key in d:
print d[key]
Dict特点:
第一个特点是查找速度快,但是占用内存大,key不能重复
第二个特点是dict存储的key-value序对是没有顺序的!
第三个特点是key不可变
十三、什么是set(2.3以后的)
定义:无序不重复的元素集合
创建 :创建一个set 的方式是调用 set() 并传入一个 list,list的元素将作为set的元素:
>>> s = set(['A', 'B', 'C'])
可以查看 set 的内容:
>>> print s
set(['A', 'C', 'B'])
请注意,上述打印的形式类似 list, 但它不是 list,仔细看还可以发现,打印的顺序和原始 list 的顺序有可能是不同的,因为set内部存储的元素是无序的。
因为set不能包含重复的元素,所以,当我们传入包含重复元素的 list 会怎么样呢?
>>> s = set(['A', 'B', 'C', 'C'])
>>> print s
set(['A', 'C', 'B'])
>>> len(s)
3
结果显示,set会自动去掉重复的元素,原来的list有4个元素,但set只有3个元素。
十四、什么是函数
1、定义:
可见,借助抽象,我们才能不关心底层的具体计算过程,而直接在更高的层次上思考问题。
写计算机程序也是一样,函数就是最基本的一种代码抽象的方式。
Python不但能非常灵活地定义函数,而且本身内置了很多有用的函数,可以直接调用。
2、调用函数
Python内置了很多有用的函数,我们可以直接调用。
Eg: functionName(args)
要调用一个函数,需要知道函数的名称和参数,比如求绝对值的函数 abs,它接收一个参数。
可以直接从Python的官方网站查看文档:
http://docs.python.org/2/library/functions.html#abs
也可以在交互式命令行通过 help(abs) 查看abs函数的帮助信息。
调用 abs 函数:
>>> abs(100)
100
>>> abs(-20)
20
>>> abs(12.34)
12.34
调用函数的时候,如果传入的参数数量不对,会报TypeError的错误,并且Python会明确地告诉你:abs()有且仅有1个参数,但给出了两个:
>>> abs(1, 2)
Traceback (most recent call last):
File "
TypeError: abs() takes exactly one argument (2 given)
如果传入的参数数量是对的,但参数类型不能被函数所接受,也会报TypeError的错误,并且给出错误信息:str是错误的参数类型:
>>> abs('a')
Traceback (most recent call last):
File "
TypeError: bad operand type for abs(): 'str'
而比较函数 cmp(x, y) 就需要两个参数,如果 x
>>> cmp(1, 2)
-1
>>> cmp(2, 1)
1
>>> cmp(3, 3)
0
Python内置的常用函数还包括数据类型转换函数,比如 int()函数可以把其他数据类型转换为整数:
>>> int('123')
123
>>> int(12.34)
12
str()函数把其他类型转换成 str:
>>> str(123)
'123'
>>> str(1.23)
'1.23'
3、编写函数
在Python中,定义一个函数要使用 def 语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用 return 语句返回。
我们以自定义一个求绝对值的 my_abs 函数为例:
def my_abs(x):
if x >= 0:
return x
else:
return -x
请注意,函数体内部的语句在执行时,一旦执行到return时,函数就执行完毕,并将结果返回。因此,函数内部通过条件判断和循环可以实现非常复杂的逻辑。
如果没有return语句,函数执行完毕后也会返回结果,只是结果为 None。
return None可以简写为return。
4、返回多值
函数可以返回多个值吗?答案是肯定的。
比如在游戏中经常需要从一个点移动到另一个点,给出坐标、位移和角度,就可以计算出新的坐标:
# math包提供了sin()和 cos()函数,我们先用import引用它:
import math
def move(x, y, step, angle):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny
这样我们就可以同时获得返回值:
>>> x, y = move(100, 100, 60, math.pi / 6)
>>> print x, y
151.961524227 70.0
但其实这只是一种假象,Python函数返回的仍然是单一值:
>>> r = move(100, 100, 60, math.pi / 6)
>>> print r
(151.96152422706632, 70.0)
用print打印返回结果,原来返回值是一个tuple!
但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,Python的函数返回多值其实就是返回一个tuple,但写起来更方便。
5、递归函数
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
举个例子,我们来计算阶乘 n! = 1 * 2 * 3 * ... * n,用函数
def yang(n):
if n==1:
return 1
else:
return n*yang(n-1)
print yang(4)
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。可以试试计算 fact(10000)。
6、定义默认参数
定义函数的时候,还可以有默认参数。
由于函数的参数按从左到右的顺序匹配,所以默认参数只能定义在必需参数的后面:
def yang(a,b=1,c=1):
return a+b+c
print yang(4) #输出6
print yang(2,3,4) #输出9
七、定义可变参数
如果想让一个函数能接受任意个参数,我们就可以定义一个可变参数:
def fn(*args):
print args
可变参数的名字前面有个 * 号,我们可以传入0个、1个或多个参数给可变参数:
>>> fn()
()
>>> fn('a')
('a',)
>>> fn('a', 'b')
('a', 'b')
>>> fn('a', 'b', 'c')
('a', 'b', 'c')
可变参数也不是很神秘,Python解释器会把传入的一组参数组装成一个tuple传递给可变参数,因此,在函数内部,直接把变量 args看成一个 tuple 就好了。
定义可变参数的目的也是为了简化调用。假设我们要计算任意个数的平均值,就可以定义一个可变参数:
def average(*args):
...
这样,在调用的时候,可以这样写:
>>> average()
0
>>> average(1, 2)
1.5
>>> average(1, 2, 2, 3, 4)
2.4
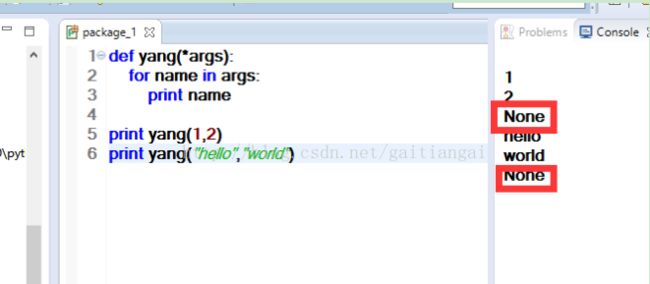
此处是笔误啊,应为函数没有返回值,所以会出现两个none。