彻底剖析numpy的array对象
1.原生python对象和numpy对象的比较
| 分析主体 | 特点 |
|---|---|
| Python对象 | ①封装程度相对较高的基础数据类型:整数、浮点小数;②容器类:list(插入操作)、dict(快速检索操作) |
| numpy对象 | ①封装程度相对较低的基础数据类型:如int64、float64、uint32;②充分利用了硬件的缓存机制(迭代操作速度更快); |
下面就来对比一下python原生list和numpy的array对象之间的性能差异。
In [1]: L = range(1000)
In [2]: %timeit [i**2 for i in L]
1000 loops, best of 3: 403 us per loop
In [3]: a = np.arange(1000)
In [4]: %timeit a**2
100000 loops, best of 3: 12.7 us per loop
2.加载numpy
正如其他被广泛使用的python库那样,我们在实际编程中常常并不是直接使用它们的全名,而是为它们取一个别名,比如pandas→pd、tensorflow→tf、matplotlitb.pyplot→plt。
import numpy as np
3.生成array的各种方式
3.1通过传入list给构造函数
>>> a = np.array([0, 1, 2, 3])
>>> a
array([0, 1, 2, 3])
>>> a.ndim
1
>>> a.shape
(4,)
>>> len(a)
4
3.2指定范围和增长步长
>>> a = np.arange(10) # 0 .. n-1 (!)
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> b = np.arange(1, 9, 2) # start, end (exclusive), step
>>> b
array([1, 3, 5, 7])
3.3指定范围和元素个数
>>> c = np.linspace(0, 1, 6) # start, end, num-points
>>> c
array([ 0. , 0.2, 0.4, 0.6, 0.8, 1. ])
>>> d = np.linspace(0, 1, 5, endpoint=False)
>>> d
array([ 0. , 0.2, 0.4, 0.6, 0.8])
3.4特殊矩阵
>>> a = np.ones((3, 3)) # 全1矩阵(注意:要传进去一个tuple)
>>> a
array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]])
>>> b = np.zeros((2, 2)) # 全零矩阵(注意:要传进去一个tuple)
>>> b
array([[ 0., 0.],
[ 0., 0.]])
>>> c = np.eye(3) # 单位矩阵
>>> c
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
>>> d = np.diag(np.array([1, 2, 3, 4])) # 对角矩阵
>>> d
array([[1, 0, 0, 0],
[0, 2, 0, 0],
[0, 0, 3, 0],
[0, 0, 0, 4]])
3.5随机数
>>> a = np.random.rand(4) # [0, 1]的均匀分布
>>> a
array([ 0.95799151, 0.14222247, 0.08777354, 0.51887998])
>>> b = np.random.randn(4) # [0, 1]的高斯分布
>>> b
array([ 0.37544699, -0.11425369, -0.47616538, 1.79664113])
>>> np.random.seed(1234) # 设置随机种子值
4.基本数据类型
请注意:numpy的array生成函数默认使用的是float64数据类型,这可能与你的编程习惯有所不同,如下:
>>> a = np.ones((3, 3))
>>> a.dtype
dtype('float64')
如果我们想指定要生成array的元素使用哪种数据类型,可以多传入一个dtype参数。
>>> a = np.array([1, 2, 3])
>>> a.dtype
dtype('int64')
>>> c = np.array([1, 2, 3], dtype=float)
>>> c.dtype
dtype('float64')
除了最常使用的int64和float64外,numpy还提供了以下的数据类型:
| 示例 | 数据类型 |
|---|---|
| d = np.array([1+2j, 3+4j, 5+6*1j]) | dtype(‘complex128’) |
| e = np.array([True, False, False, True]) | dtype(‘bool’) |
| f = np.array([‘Bonjour’, ‘Hello’, ‘Hallo’,]) | dtype(‘S7’) |
除此之外,还有int32、int64、uint32、uint64等等。
6.切片操作和视图
切片操作(slice)是Python语言的一个十分强大的语法特性,同样地numpy也对此有很好地支持,而且进一步拓展到多维array同样适用,用法如下图所示:
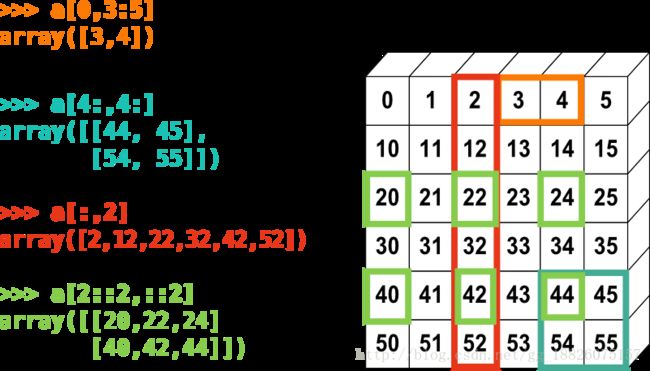
但是对于numpy来说,切片操作通常不会真的把原array对应的元素复制一遍,而只是对应的视图罢了(共享内存存储)。意识到这一点相当重要,因为如果我们修改原array或者视图的任意一方,都会同时影响到另一方的数据,为此我们可以使用np.may_share_memory()函数进行进一步的确认。
>>> a = np.arange(10)
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> b = a[::2]
>>> b
array([0, 2, 4, 6, 8])
>>> np.may_share_memory(a, b) # a和b共享内存对象
True
>>> b[0] = 12
>>> b
array([12, 2, 4, 6, 8])
>>> a # (!)
array([12, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> a = np.arange(10)
>>> c = a[::2].copy() # 强制进行复制操作
>>> c[0] = 12
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.may_share_memory(a, c)
False
7.魔法索引
对于numpy的array,不光可以使用切片操作,而且还支持一些非数字索引下标,我们称此为魔法索引。值得注意的是,使用魔法索引得到的array在存储上与原array完全分离,即采用的是拷贝操作而不是视图操作。
7.1逻辑掩码
>>> np.random.seed(3)
>>> a = np.random.random_integers(0, 20, 15)
>>> a
array([10, 3, 8, 0, 19, 10, 11, 9, 10, 6, 0, 20, 12, 7, 14])
>>> (a % 3 == 0)
array([False, True, False, True, False, False, False, True, False,
True, True, False, True, False, False], dtype=bool)
>>> mask = (a % 3 == 0)
>>> extract_from_a = a[mask] # or, a[a%3==0]
>>> extract_from_a # extract a sub-array with the mask
array([ 3, 0, 9, 6, 0, 12])
我们可以使用它完成一些相对看似十分复杂的任务,比如把array中某些元素集体赋值(如机器学习中常常需要进行缺失值填充)。
>>> a[a % 3 == 0] = -1
>>> a
array([10, -1, 8, -1, 19, 10, 11, -1, 10, -1, -1, 20, -1, 7, 14])
7.2下标数组
>>> a = np.arange(0, 100, 10)
>>> a
array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
>>> a[[2, 3, 2, 4, 2]] # note: [2, 3, 2, 4, 2] is a Python list
array([20, 30, 20, 40, 20])
>>> a[[9, 7]] = -100
>>> a
array([ 0, 10, 20, 30, 40, 50, 60, -100, 80, -100])
或者更加神奇地,我们可以由一个一维array生成一个二维array
>>> a = np.arange(10)
>>> idx = np.array([[3, 4], [9, 7]])
>>> idx.shape
(2, 2)
>>> a[idx]
array([[3, 4],
[9, 7]])