NO.31——Python爬虫分析马蜂窝十一假期城市旅游数据
十一假期开始,打开朋友圈,看到小伙伴们纷纷晒出了自己的车票,不是出去玩就是回家。因为不可抗拒的因素,可怜的我只能坚守工作岗位,哪都去不了,心急难耐之余,虽然自己去不了,那就看看全国各地的广大旅友都喜欢去什么地方吧。
这里,数据来源是马蜂窝http://www.mafengwo.cn/。首先,马蜂窝对爬虫相对友好,另外,使用马蜂窝也是我和女友出游的习惯,在计划去某地前都会先在马蜂窝上查查攻略,不得不佩服很多小伙伴写的游记真的超级棒,起到事半功倍的效果。
目标:
通过分析马蜂窝中提及到某目的地的景点、餐饮、娱乐三个方面的游记做定量分析,客观程度上反映出某目的地的热门程度。
工具:
selenium自动化测试工具
ChromeDriver
pandas
pyecharts
原理:
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。在这里可以利用Selenium模拟点击,做一些翻页操作。
步骤1:获取城市编号
马蜂窝中的所有城市或目的地都有一个专属的五位数字编号,要想获得该城市或目的地的具体信息,首先要获取该目的地(直辖市或地级市)的城市编号,然后进行后续的分析。
如上图所示,在目的地栏进入某个省份,以云南为例,总共有206个目的地。以上两个页面就是我们的城市编码来源,首先在目的地页面获得各省编码,之后进入各省的城市列表获得城市编码。这里采用Selenium进行动态数据爬取,获取城市编码的代码如下:
# -*- coding: utf-8 -*-
"""
Created on Tue May 29 21:53:47 2018
@author: slash
"""
import os
import time
from urllib.request import urlopen
from urllib import request
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
os.chdir('/Users/Macx/Desktop/python_demo/mafengwo_data-master')
## 获得地区url地址
def find_cat_url(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req=request.Request(url,headers=headers)
html=urlopen(req)
#指定使用html.parser解析器进行解析,目前支持lxml, html5lib, 和 html.parser
bsObj=BeautifulSoup(html.read(),"html.parser")
#按照属性名和标签名找到所有目的地,目的地名放在dt标签里
bs = bsObj.find('div',attrs={'class':'hot-list clearfix'}).find_all('dt')
cat_url = []
cat_name = []
#遍历所有目的地
for i in range(0,len(bs)):
#遍历某个目的地的所有地区名,地区名放在a标签里
for j in range(0,len(bs[i].find_all('a'))):
#通过href属性查找地区网址进行添加
cat_url.append(bs[i].find_all('a')[j].attrs['href'])
#通过a标签查找地区名进行添加
cat_name.append(bs[i].find_all('a')[j].text)
cat_url = ['http://www.mafengwo.cn'+cat_url[i] for i in range(0,len(cat_url))]
return cat_url
## 获得城市url地址
def find_city_url(url_list):
city_name_list = []
city_url_list = []
for i in range(0,len(url_list)):
driver = webdriver.Chrome()
driver.maximize_window()
url = url_list[i].replace('travel-scenic-spot/mafengwo','mdd/citylist')
driver.get(url)
while True:
try:
time.sleep(2)
bs = BeautifulSoup(driver.page_source,'html.parser')
url_set = bs.find_all('a',attrs={'data-type':'目的地'})
city_name_list = city_name_list +[url_set[i].text.replace('\n','').split()[0] for i in range(0,len(url_set))]
city_url_list = city_url_list+[url_set[i].attrs['data-id'] for i in range(0,len(url_set))]
#模拟滚动条向下滚动800个像素
js="var q=document.documentElement.scrollTop=1000"
#调用JS脚本
driver.execute_script(js)
time.sleep(2)
driver.find_element_by_class_name('pg-next').click()
except:
break
driver.close()
return city_name_list,city_url_list
## 执行代码
url = 'http://www.mafengwo.cn/mdd/'
url_list = find_cat_url(url)
city_name_list,city_url_list=find_city_url(url_list)
#从字典构造DataFrame
city = pd.DataFrame({'city_name':city_name_list,'city_code':city_url_list})
city.to_csv('city.csv')
最后,将爬取的城市编码作为一个二维数组放入一个表格里。总共得到3281条数据。
步骤2:获取城市具体信息
这里,主要获取马蜂窝中的城市印象标签、景点、餐饮、娱乐四个板块的信息。
(1)城市印象标签
(2)景点页面
(2)餐饮页面
(3)娱乐页面
将每个城市获取数据的过程封装成函数,每次传入之前先获得城市编码:
# -*- coding: utf-8 -*-
"""
Created on Sat Jun 2 16:46:19 2018
@author: slash
"""
import os
from urllib.request import urlopen
from urllib import request
from bs4 import BeautifulSoup
import pandas as pd
from pyecharts import Bar,Geo,Grid
os.chdir('/Users/Macx/Desktop/python_demo/mafengwo_data-master')
## 获得城市url内容
def get_static_url_content(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req=request.Request(url,headers=headers)
html=urlopen(req)
bsObj=BeautifulSoup(html.read(),"html.parser")
return bsObj
## 获得城市信息
def get_city_info(city_name,city_code):
this_city_base = get_city_base(city_name,city_code)
#景点
try:
this_city_jd = get_city_jd(city_name,city_code)
this_city_jd['city_name'] = city_name
this_city_jd['total_city_yj'] = this_city_base['total_city_yj']
except:
this_city_jd=pd.DataFrame()
#餐饮
try:
this_city_food = get_city_food(city_name,city_code)
this_city_food['city_name'] = city_name
this_city_food['total_city_yj'] = this_city_base['total_city_yj']
except:
this_city_food=pd.DataFrame()
#娱乐
try:
this_city_yl = get_city_yl(city_name,city_code)
this_city_yl['city_name'] = city_name
this_city_yl['total_city_yj'] = this_city_base['total_city_yj']
except:
this_city_yl=pd.DataFrame()
return this_city_base,this_city_jd,this_city_food,this_city_yl
#从这里开始进入!!!!
## 获得城市各类标签信息
def get_city_base(city_name,city_code):
url = 'http://www.mafengwo.cn/xc/'+str(city_code)+'/'
bsObj = get_static_url_content(url)
#
#酒吧 4088
#在社区行程页面寻找城市印象的标签,如丽江印象
node = bsObj.find('div',{'class':'m-box m-tags'}).find('div',{'class':'bd'}).find_all('a')
#寻找印象提及次数的标签
tag_node = bsObj.find('div',{'class':'m-box m-tags'}).find('div',{'class':'bd'}).find_all('em')
#将提及次数的text文本信息转化成整型
tag_count = [int(k.text) for k in tag_node]
#
#其中不同标签有不同代号,看该标签是属于娱乐还是餐饮还是景点还是购物
#
par = [k.attrs['href'][1:3] for k in node]
#所有印象被提及次数的总和
tag_all_count = sum([int(tag_count[i]) for i in range(0,len(tag_count))])
#有多少人的游记中提到该城市的景点
tag_jd_count = sum([int(tag_count[i]) for i in range(0,len(tag_count)) if par[i]=='jd'])
#有多少人的游记中提到该城市的餐饮
tag_food_count = sum([int(tag_count[i]) for i in range(0,len(tag_count)) if par[i]=='cy'])
#有多少人的游记中提到该城市的娱乐
tag_yl_count = sum([int(tag_count[i]) for i in range(0,len(tag_count)) if par[i] in ['gw','yl']])
#第一页
url = 'http://www.mafengwo.cn/yj/'+str(city_code)+'/2-0-1.html '
bsObj = get_static_url_content(url)
#共391页 / 5860条
#下滑后查看页码和记录条数,记录总的游记数量
total_city_yj = int(bsObj.find('span',{'class':'count'}).find_all('span')[1].text)
return {'city_name':city_name,'tag_all_count':tag_all_count,'tag_jd_count':tag_jd_count,
'tag_food_count':tag_food_count,'tag_yl_count':tag_yl_count,
'total_city_yj':total_city_yj}
## 获得某个城市具体那些食物的信息
def get_city_food(city_name,city_code):
#进到目的地餐饮页面
#
# -
#
#
 1
#
1
# 牛肉面
# 501 501 游记提及
# 4 推荐美食
#
#
url = 'http://www.mafengwo.cn/cy/'+str(city_code)+'/gonglve.html'
bsObj = get_static_url_content(url)
#餐饮名称
food=[k.text for k in bsObj.find('ol',{'class':'list-rank'}).find_all('h3')]
#餐饮推荐次数
food_count=[int(k.text) for k in bsObj.find('ol',{'class':'list-rank'}).find_all('span',{'class':'trend'})]
return pd.DataFrame({'food':food[0:len(food_count)],'food_count':food_count})
## 获得某个城市具体那些景点的信息
def get_city_jd(city_name,city_code):
url = 'http://www.mafengwo.cn/jd/'+str(city_code)+'/gonglve.html'
bsObj = get_static_url_content(url)
#找到景点名称标签
node=bsObj.find('div',{'class':'row row-top5'}).find_all('h3')
jd = [k.text.split('\n')[2] for k in node]
#5833 条点评
node=bsObj.find_all('span',{'class':'rev-total'})
#将字符串格式转化成整型
jd_count=[int(k.text.replace(' 条点评','')) for k in node]
return pd.DataFrame({'jd':jd[0:len(jd_count)],'jd_count':jd_count})
## 获得某个城市具体那些娱乐的信息
def get_city_yl(city_name,city_code):
url = 'http://www.mafengwo.cn/yl/'+str(city_code)+'/gonglve.html'
bsObj = get_static_url_content(url)
#娱乐标签名称
yl=[k.text for k in bsObj.find('ol',{'class':'list-rank'}).find_all('h3')]
#娱乐推荐次数
yl_count=[int(k.text) for k in bsObj.find('ol',{'class':'list-rank'}).find_all('span',{'class':'trend'})]
return pd.DataFrame({'yl':yl[0:len(yl_count)],'yl_count':yl_count})
## 执行函数
city_list = pd.read_csv('city.csv')
#数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列
city_base = pd.DataFrame()
city_food = pd.DataFrame()
city_jd = pd.DataFrame()
city_yl = pd.DataFrame()
#读取矩阵第一维度的长度
for i in range(0,city_list.shape[0]):
try:
#iloc是根据标签所在的位置,从0开始计数
#loc根据列的具体名称进行选取
k = city_list.iloc[i]
#city_name是str类型 city_code是64int型
this_city_base,this_city_jd,this_city_food,this_city_yl=get_city_info(k['city_name'],k['city_code'])
city_base=city_base.append(this_city_base,ignore_index=True)
#axis=0,按照行数首尾链接
city_food = pd.concat([city_food,this_city_food],axis=0)
city_jd = pd.concat([city_jd,this_city_jd],axis=0)
city_yl = pd.concat([city_yl,this_city_yl],axis=0)
print(i)
print('正确:'+k['city_name'])
except:
print(i)
print('错误:'+k['city_name'])
continue
## 绘制图片
#######################################对城市作分析##########################################
#ascending=False 降序排列 ,ascending=True, 升序排列 inplace默认为True
city_base.sort_values('total_city_yj',ascending=False,inplace=True)
attr1 = city_base['city_name'][0:10]
#提到某城市的游记总数量
v1 = city_base['total_city_yj'][0:10]
#提到某城市景点的游记总数量
v2 = city_base['tag_jd_count'][0:15]
#提到某城市餐饮的游记总数量
v3 = city_base['tag_food_count'][0:15]
#提到某城市娱乐的游记总数量
v4 = city_base['tag_yl_count'][0:15]
bar1 = Bar("游记TOP15")
#"游记总数"为标题,attr为横坐标城市名称,v1为纵坐标游记总数
bar1.add("游记总数", attr1, v1, is_stack=True)
bar1.render('游记总数量TOP10.html')
city_base.sort_values('tag_jd_count',ascending=False,inplace=True)
attr_jd = city_base['city_name'][0:15]
bar2 = Bar("景点类标签排名")
bar2.add("景点类标签分数", attr_jd, v2, is_splitline_show=False,xaxis_rotate=30)
city_base.sort_values('tag_food_count',ascending=False,inplace=True)
attr_food = city_base['city_name'][0:15]
bar3 = Bar("餐饮类标签排名")
bar3.add("餐饮类标签分数", attr_food, v3, legend_top="30",is_splitline_show=False,xaxis_rotate=30)
city_base.sort_values('tag_yl_count',ascending=False,inplace=True)
attr_yl = city_base['city_name'][0:15]
bar4 = Bar("休闲类标签排名")
bar4.add("休闲类标签分数", attr_yl, v4, legend_top="67.5",is_splitline_show=False,xaxis_rotate=30)
grid = Grid(height=800)
grid.add(bar2,grid_bottom="75%")
grid.add(bar3,grid_bottom="37.5%",grid_top="37.5%")
grid.add(bar4,grid_top="75%")
grid.render('城市分类标签.html')
'''
#遍历CSV中的每一行数据,城市名称和每个城市提到的游记数量
data=[(city_base['city_name'][i],city_base['total_city_yj'][i]) for i in range(0,
city_base.shape[0])]
#地理坐标系Geo
geo = Geo('马蜂窝全国城市旅游热力图', title_color="#fff",
title_pos="center", width=1200,
height=600, background_color='#404a59')
attr, value = geo.cast(data)
geo.add("", attr, value, visual_range=[0, 30000], visual_text_color="#fff",
symbol_size=15, is_visualmap=True,is_roam=False)
geo.render('蚂蜂窝全国城市旅游热力图.html')
'''
#########################################对景点作分析#####################################
city_jd.sort_values('jd_count',ascending=False,inplace=True)
city_food.sort_values('food_count',ascending=False,inplace=True)
city_yl.sort_values('yl_count',ascending=False,inplace=True)
attr2 = city_jd['jd'][0:15]
attr3 = city_food['food'][0:15]
attr4 = city_yl['yl'][0:15]
v22 = city_jd['jd_count'][0:15]
v33 = city_food['food_count'][0:15]
v44 = city_yl['yl_count'][0:15]
bar11=Bar("景点人气排名")
bar11.add("景点人气分数", attr2, v22, is_splitline_show=False,xaxis_rotate=30)
bar22=Bar("餐饮人气排名")
bar22.add("餐饮人气分数", attr3, v33, legend_top="30",is_splitline_show=False,xaxis_rotate=30)
bar33 = Bar("休闲人气排名")
bar33.add("休闲人气分数", attr4, v44, legend_top="67.5",is_splitline_show=False,xaxis_rotate=30)
grid = Grid(height=800)
grid.add(bar11,grid_bottom="75%")
grid.add(bar22,grid_bottom="37.5%",grid_top="37.5%")
grid.add(bar33,grid_top="75%")
grid.render('人气排名.html')
步骤3:数据可视化分析
(1)热门城市Top10

通过提炼提及到每个城市的游记数量,排列出受欢迎程度前十名的城市如图所示,不出意料,小清新的厦门果然受到广大旅友的青睐。在年初三月份的时候和女友一同去了鼓浪屿、曾厝垵等地方,印象真的很好。
(2)城市分类标签

按提及到的景点、餐饮、娱乐对城市进行排名,果然,厦门又英勇夺魁。
(3)人气排名
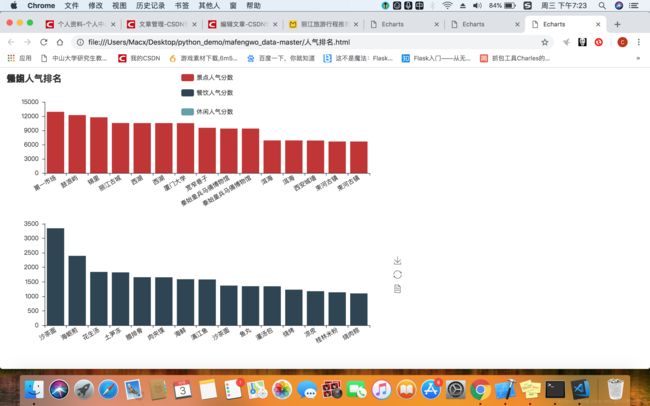

然后再分别看看景点、餐饮、休闲类的人气排名,看看大家到底喜欢什么地方。出乎意料的是,大家最喜欢逛的景点是第一市场,这个第一市场是什么鬼,没听过!!!!不过后几名的鼓浪屿、锦里、丽江古城、西湖还是在情理之中的。
因为去厦门的最多,自然而然排名前二的美食就是沙茶面和海蛎煎喽,本人也超级喜欢哈哈。
(4)马蜂窝全国城市旅游热力图。
在这里,主要想看看大家的足迹都涉及到哪些城市。过程中遇到了个问题,首先从马蜂窝提取出的目的地名称是不包含“市”、“县”、“区”这些字眼的,然而pyecharts带的地图资源包的json文件中的键名包含了这些字眼,因此画图时总出现键名不匹配的bug。除了对json包进行修改,暂时没想到其他方法,但3281条数据量比较大,就不修改了,这里仅修改了云南的50个目的地做演示。
