【Sqoop】数据转换工具Sqoop
1、Sqoop概述
HiveQL对数据进行分析,并将结果集存储到hdfs 文件或hive 表中,当前端需要使用数据处理的结果时,需要将结果集导出到RDBMS中,而Sqoop就是将常用的MapReduce(数据导入导出)进行封装,通过传递参数的形式,运行MapReduce任务,将hdfs文件系统、Hive或HBase中的数据导出到RDBMS,或将RDBMS中的数据导入到hdfs文件系统、Hive或HBase中的。sqoop,即SQL to HADOOP的简写。以Hadoop 为主体,RDBMS为客体,sqoop import,就是将RDBMS数据放入hadoop 中,就是导入import;sqoop export,就是将hadoop中的数据放入到RDBMS中,就是导出export。sqoop 是依赖于hadoop的,需要导入导出的数据,存储在hdfs中,而且底层的数据传输的实现使用MapReduce或YARN,Sqoop 底层的实现就是MapReduce,充分利用了MapReduce并行计算的特点,使用批处理方式进行数据传输。sqoop无论是导入还是导出都是没有reduce过程的,只有map过程。
2、Sqoop版本
Sqoop1和Sqoop2版本是两个不同版本,完全不兼容。其版本号划分方式:Apache:1.4.x~ ,1.99.x~。
Sqoop2比Sqoop1的改进有:
(1)引入sqoop server,集中化管理Connector等;
(2)多种访问方式:CLI,Web UI,REST API;
(3)引入基于角色的安全机制。
一般的Apache官方适应于Hadoop版本的编译好的sqoop二进制文件并不适用于我们的hadoop版本,所以我们需要依据hadoop 版本编译sqoop。实际生产环境中我们使用CDH(Cloudera Hadoop)版本的Hadoop,里面有适合我们Hadoop 2.5.0版本的编译好的sqoop。
CDH 5.3.6 版本非常的稳定和好用,我们使用的是hadoop-2.5.0-cdh5.3.6.tar.gz, hive-0.13.1-cdh5.3.6.tar.gz,zookeeper-3.4.5-cdh5.3.6.tar.gz, sqoop-1.4.5-cdh5.3.6.tar.gz,flume-ng-1.5.0-cdh5.3.6,oozie-4.0.0-cdh5.3.6和hue-3.7.0-cdh5.3.6.tar.gz,下载地址:http://archive.cloudera.com/cdh5/cdh/5/。
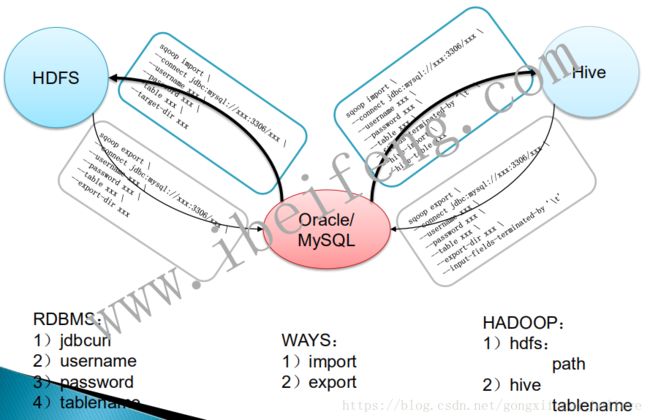
3、Sqoop与RDBMS的结合
Sqoop连接RDBMS的四要素: JDBCurl、username、password、tablename。
RDBMS以MySQL数据库为例,拷贝jdbc驱动包到 S Q O O P H O M E / l i b 目 录 下 , ‘ SQOOP_HOME/lib目录下, ` SQOOPHOME/lib目录下,‘ cp /opt/software/mysql-libs/mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/lib/`
Sqoop列出MySQL中的数据库:
bin/sqoop list-databases \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306 \
--username root \
--password 123456
4、Sqoop将RDBMS中的数据导入到HDFS中
(1)在MySQL中建表my_user,并插入数据:
CREATE TABLE `my_user` (
`id` tinyint(4) NOT NULL AUTO_INCREMENT,
`account` varchar(255) DEFAULT NULL,
`passwd` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
);
INSERT INTO `my_user` VALUES ('1', 'admin', 'admin');
INSERT INTO `my_user` VALUES ('2', 'pu', '12345');
INSERT INTO `my_user` VALUES ('3', 'system', 'system');
INSERT INTO `my_user` VALUES ('4', 'zxh', 'zxh');
INSERT INTO `my_user` VALUES ('5', 'test', 'test');
INSERT INTO `my_user` VALUES ('6', 'pudong', 'pudong');
INSERT INTO `my_user` VALUES ('7', 'qiqi', 'qiqi');
(2)将MySQL中的my_user表导入HDFS,不指定HDFS路径默认导入到/user/beifeng下,以表的名字 my_user创建的目录中,默认执行仅有map的MapReduce任务,默认使用的map数为4个:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user
(3)指定导入的HDFS目录,指定map数为1,因为我们的测试仅有7条数据:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--delete-target-dir \
--target-dir /user/beifeng/sqoop/imp_my_user \
--num-mappers 1
–delete-target-dir \:删除目标目录
–num-mappers 1:指定mapper个数
(4)数据存储文件格式:textfile、orcfile、parquet。导入HDFS,并存储为parquet格式:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/beifeng/sqoop/imp_my_user_parquet \
--fields-terminated-by ',' \
--num-mappers 1 \
--as-parquetfile
Input parsing arguments:输入指定分隔符
Output line formatting arguments:输出指定分隔符
–fields-terminated-by ‘,’ \:指定输出分隔符为“,”
(5)导入HDFS,指定要导入的列:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/beifeng/sqoop/imp_my_user_column \
--num-mappers 1 \
--columns id,account
(6)将SQL查询出来的指定内容导入HDFS:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--query 'select id, account from my_user where $CONDITIONS' \
--target-dir /user/beifeng/sqoop/imp_my_user_query \
--num-mappers 1
(7)导入HDFS并压缩为Snappy格式:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/beifeng/sqoop/imp_my_snappy \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--fields-terminated-by '\t'
(8)在Hive上创建表,并将导入到HDFS上的数据插入到Hive的表中:
drop table if exists default.hive_user_snappy ;
create table default.hive_user_snappy(
id int,
username string,
password string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
load data inpath '/user/beifeng/sqoop/imp_my_snappy' into table default.hive_user_snappy ;
Sqoop在MySQL、HDFS和Hive之间的协作:
(1)在MySQL中创建表;
(2)Sqoop将MySQL中的表import到HDFS中,默认存储为TEXTFILE格式,可以存储为Snappy格式;
(3)在Hive中创建表;
(4)将导入到HDFS中的数据load到Hive表中;
(5)在Hive中进行查询,可以使用HiveServer2等工具以JDBC方式查询。
(9)增量数据导入HDFS:
通常表中字段有一个唯一标识符,类似于插入时间createtime,这样,在查询语句中可以添加查询条件:
where createtime => 20150924000000000 and createtime < 20150925000000000
Incremental import arguments:
--check-column Source column to check for incremental
change
--incremental Define an incremental import of type
'append' or 'lastmodified'
--last-value Last imported value in the incremental
check column
增量导入HDFS:
Incremental import arguments:
--check-column Source column to check for incremental
change
--incremental Define an incremental import of type
'append' or 'lastmodified'
--last-value Last imported value in the incremental
check column
--check-column:检查列,将某一列作为一个增量导入的依据,一般是主键;
--incremental:增量实现导入方式: 'append' or 'lastmodified';
--last-value:根据最后插入的值来判断 ,--last-value指的是上一次最后插入的值,或者是最后导入的那条记录的时间
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/beifeng/sqoop/imp_my_incr \
--num-mappers 1 \
--incremental append \
--check-column id \
--last-value 4
注意:如果是增量导入,原目录是不能删除的。
(10)使用direct参数将MySQL中的数据直接导入到HDFS中:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/beifeng/sqoop/imp_my_incr \
--num-mappers 1 \
--delete-target-dir \
--direct
–direct:快速导入模式
(11)将sqoop打包成一个job
ImportTool: (Consider saving this with ‘sqoop job --create’)
可以将sqoop打包成一个job来代表这个sqoop任务,使用定时实现增量导入。
$ bin/sqoop job --help
创建sqoop job
bin/sqoop job \
--create stu_info \
-- \
import \
--connect \
jdbc:mysql://bigdata-senior01.ibeifeng.com:3306/sqoop \
--username root \
--password 123456 \
--direct \
--table tohdfs \
--target-dir /sqoop \
--num-mappers 1 \
--fields-terminated-by '\t' \
--check-column id \
--incremental append \
--last-value 8
或者:--last-value '2017-05-14 15:00:30'
查看sqoop任务:
$ bin/sqoop job --show stu_info
5、Sqoop将HDFS中的数据导出到RDBMS中
(1)准备数据,并上传到HDFS:
touch /opt/datas/user.txt
vi /opt/datas/user.txt
8,beifeng,beifeng
9,xuanyun,xuanyu
bin/hdfs dfs -mkdir -p /user/beifeng/sqoop/exp/user/
bin/hdfs dfs -put /opt/datas/user.txt /user/beifeng/sqoop/exp/user/
(2)将HDFS上的数据导出到RDBMS的表my_user中:
bin/sqoop export \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--export-dir /user/beifeng/sqoop/exp/user/ \
--num-mappers 1
(3)也可以使用–options-file选项,相当于hive中-f选项导出数据
执行sqoop 文件:bin/sqoop --options-file sqoop.file
sqoop.file文件内容:
export
--connect
jdbc:mysql://bigdata-senior01.ibeifeng.com:3306/sqoop
--username
root
--password
123456
--table
filetomysql
--export-dir
/sqoop
--num-mappers
1
--input-fields-terminated-by
'\t'
6、导入导出Hive表
(1)将MySQL中的表导入到Hive的表中:
在Hive中创建表:
use default ;
drop table if exists user_hive ;
create table user_hive(
id int,
account string,
password string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
将MySQL中的my_user表导入Hive中的user_hive表:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--fields-terminated-by '\t' \
--delete-target-dir \
--num-mappers 1 \
--hive-import \
--hive-database default \
--hive-table user_hive
和MySQL导入到HDFS一样,先将数据文件放到HDFS上,然后将结果集移动到Hive的表对应的文件夹下。
(2)将Hive中的表导出到MySQL中:
在MySQL中创建表:
CREATE TABLE `my_user2` (
`id` tinyint(4) NOT NULL AUTO_INCREMENT,
`account` varchar(255) DEFAULT NULL,
`passwd` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
);
Hive中的表存储在HDFS上,将Hive中的表user_hive中数据导出到MySQL中创建的表my_user2中:
bin/sqoop export \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user2 \
--export-dir /user/hive/warehouse/user_hive \
--num-mappers 1 \
--input-fields-terminated-by '\t'
7、脚本执行
可以将bin/hive和bin/sqoop的执行语句都写成脚本,然后用Shell脚本来在命令行执行。
bin/sqoop脚本格式如下:
## sqoop-import-hdfs.txt
import
--connect
jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test
--username
root
--password
123456
--table
my_user
--target-dir
/user/beifeng/sqoop/imp_my_user_option
--num-mappers
1
Shell脚本格式如下:
shell scripts
## step 1
load data ...
## step 2
bin/hive -f xxxx
## step 3
bin/sqoop --options-file /opt/datas/sqoop-import-hdfs.txt