机器学习算法实现解析——libFM之libFM的训练过程概述
本节主要介绍的是libFM源码分析的第四部分——libFM的训练。
FM模型的训练是FM模型的核心的部分。
4.1、libFM中训练过程的实现
在FM模型的训练过程中,libFM源码中共提供了四种训练的方法,分别为:Stochastic Gradient Descent(SGD),Adaptive SGD(ASGD),Alternating Least Squares(ALS)和Markov Chain Monte Carlo(MCMC),其中ALS是MCMC的特殊形式,实际上其实现的就是SGD,ASGD和MCMC三种训练方法,三者的类之间的关系如下图所示:
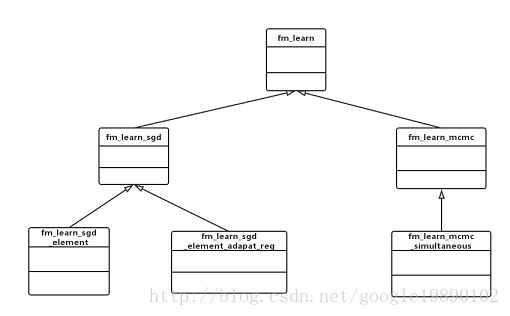
FM模型训练的父类为fm_learn,其定义在文件fm_learn.h中,fm_learn_sgd类和fm_learn_mcmc类分别继承自fm_learn类。其中,fm_learn_sgd是基于梯度的实现方法,fm_learn_mcmc是基于蒙特卡洛的实现方法。
fm_learn_sgd_element类和fm_learn_sgd_element_adapt_reg类是fm_learn_sgd类的子类,是两种具体的基于梯度方法的实现,分别为SGD和ASGD。
fm_learn_mcmc_simultaneous类是fm_learn_mcmc类的子类,是具体的基于蒙特卡洛方法的实现。
4.2、训练过程的父类
在所有的训练过程中,fm_learn类为所有模型训练类的父类。
4.2.1、头文件
#include 4.2.2、第一部分的protected属性和方法
在这部分中定义了交叉项中需要用到两个数据,分别为sum和sum_sqr,这两个数的具体使用可以参见“机器学习算法实现解析——libFM之libFM的模型处理部分”。除此之外,还定义了预测predict_case函数,具体代码如下所示:
protected:
DVector<double> sum, sum_sqr;// FM模型的交叉项中的两项
DMatrix<double> pred_q_term;
// this function can be overwritten (e.g. for MCMC)
// 预测,使用的是fm_model中的predict函数
virtual double predict_case(Data& data) {
return fm->predict(data.data->getRow());
}其中,预测predict_case函数使用的是fm_model类中的predict函数,对于该函数,可以参见“机器学习算法实现解析——libFM之libFM的模型处理部分”。
4.2.3、第二部分的public属性和方法
在这部分中,主要构造函数fm_learn函数,初始化init函数以及评估evaluate函数,其具体代码如下所示:
public:
DataMetaInfo* meta;
fm_model* fm;// 对应的fm模型
double min_target;// 设置的预测值的最小值
double max_target;// 设置的预测值的最大值
// task用于区分不同的任务:0表示的是回归,1表示的是分类
int task; // 0=regression, 1=classification
// 定义两个常量,分别表示的是回归和分类
const static int TASK_REGRESSION = 0;
const static int TASK_CLASSIFICATION = 1;
Data* validation;// 验证数据集
RLog* log;// 日志指针
// 构造函数,初始化变量,实例化的过程在main函数中
fm_learn() { log = NULL; task = 0; meta = NULL;}
virtual void init() {
// 日志
if (log != NULL) {
if (task == TASK_REGRESSION) {
log->addField("rmse", std::numeric_limits<double>::quiet_NaN());
log->addField("mae", std::numeric_limits<double>::quiet_NaN());
} else if (task == TASK_CLASSIFICATION) {
log->addField("accuracy", std::numeric_limits<double>::quiet_NaN());
} else {
throw "unknown task";
}
log->addField("time_pred", std::numeric_limits<double>::quiet_NaN());
log->addField("time_learn", std::numeric_limits<double>::quiet_NaN());
log->addField("time_learn2", std::numeric_limits<double>::quiet_NaN());
log->addField("time_learn4", std::numeric_limits<double>::quiet_NaN());
}
// 设置交叉项中的两项的大小
sum.setSize(fm->num_factor);
sum_sqr.setSize(fm->num_factor);
pred_q_term.setSize(fm->num_factor, meta->num_relations + 1);
}
// 对数据的评估
virtual double evaluate(Data& data) {
assert(data.data != NULL);// 检查数据不为空
if (task == TASK_REGRESSION) {// 回归
return evaluate_regression(data);// 调用回归的评价方法
} else if (task == TASK_CLASSIFICATION) {// 分类
return evaluate_classification(data);// 调用分类的评价放啊
} else {
throw "unknown task";
}
}在评估evaluate函数中,根据task的值判断是分类问题还是回归问题,分别调用第四部分中的evaluate_regression和evaluate_classification函数。
4.2.4、第三部分的public属性和方法
在这部分中分别定义了模型的训练函数,模型的预测函数和debug输出函数,代码的具体过程如下所示:
public:
// 模型的训练过程
virtual void learn(Data& train, Data& test) { }
// 纯虚函数
virtual void predict(Data& data, DVector<double>& out) = 0;
// debug函数,用于打印中间的结果
virtual void debug() {
std::cout << "task=" << task << std::endl;
std::cout << "min_target=" << min_target << std::endl;
std::cout << "max_target=" << max_target << std::endl;
}其中模型的训练learn函数没有定义具体的实现,由上述的继承关系,其具体的训练过程在具体的子类中实现;模型的预测predict函数是一个纯虚函数。对于纯虚函数的概念,可以参见;最后一个函数是一个debug函数,debug函数用于打印中间的结果。
4.2.5、第四部分的protected属性和方法
在这部分中定义了两个评价函数,分别用于处理分类问题和回归问题,代码的具体过程如下所示:
protected:
// 对分类问题的评价
virtual double evaluate_classification(Data& data) {
int num_correct = 0;// 准确类别的个数
double eval_time = getusertime();
for (data.data->begin(); !data.data->end(); data.data->next()) {
double p = predict_case(data);// 对样本进行预测
// 利用预测值的符号与原始标签值的符号是否相同,若相同,则预测是准确的
if (((p >= 0) && (data.target(data.data->getRowIndex()) >= 0)) || ((p < 0) && (data.target(data.data->getRowIndex()) < 0))) {
num_correct++;
}
}
eval_time = (getusertime() - eval_time);
// log the values
// log文件
if (log != NULL) {
log->log("accuracy", (double) num_correct / (double) data.data->getNumRows());
log->log("time_pred", eval_time);
}
return (double) num_correct / (double) data.data->getNumRows();// 返回准确率
}
// 对回归问题的评价
virtual double evaluate_regression(Data& data) {
double rmse_sum_sqr = 0;// 误差的平方和
double mae_sum_abs = 0;// 误差的绝对值之和
double eval_time = getusertime();
for (data.data->begin(); !data.data->end(); data.data->next()) {
// 取出每一条样本
double p = predict_case(data);// 计算该样本的预测值
p = std::min(max_target, p);// 防止预测值超出最大限制
p = std::max(min_target, p);// 防止预测值超出最小限制
double err = p - data.target(data.data->getRowIndex());// 得到预测值与真实值之间的误差
rmse_sum_sqr += err*err;// 计算误差平方和
mae_sum_abs += std::abs((double)err);// 计算误差的绝对值之和
}
eval_time = (getusertime() - eval_time);
// log the values
// log文件
if (log != NULL) {
log->log("rmse", std::sqrt(rmse_sum_sqr/data.data->getNumRows()));
log->log("mae", mae_sum_abs/data.data->getNumRows());
log->log("time_pred", eval_time);
}
return std::sqrt(rmse_sum_sqr/data.data->getNumRows());// 返回均方根误差
}其中,在分类问题中,使用的评价标准是准确率:
在回归问题中,使用的评价标准是均方根误差:
其中, y^ 表示的是对样本的预测值, y 表示的是样本的原始标签, #(y^⋅y>0) 表示的是预测值 y^ 与原始标签 y 同号的样本的个数(原始标签 y∈{−1,1} ), m 表示的是样本的个数。
在对样本进行预测时用到了predict_case函数,该函数在“第一部分的protected属性和方法“中定义。在回归问题中,为预测值设置了最大的上限(std::max(min_target, p))和最小的下限(std::min(max_target, p))。为了能够记录时间,代码中使用到了getusertime函数,该函数的定义在util.h文件中。
参考文献
- Rendle S. Factorization Machines[C]// IEEE International Conference on Data Mining. IEEE Computer Society, 2010:995-1000.
- Rendle S. Factorization Machines with libFM[M]. ACM, 2012.