Sklearn之分类器性能评估
分类器的性能评估
在回归任务中,性能评估的方式较为简单,最常用的性能度量方式为均方误差(MSE)。
但是评估分类器就要比评估回归模型要困难很多,我们通常采用以下指标对分类器进行性能评估:
1、准确率、错误率(在评估倾斜类时,不是一个好指标)
2、精度(precision)、召回率(recall)、F1
3、ROC曲线、AUC
在进行性能评估时,依旧和回归模型一样采用交叉验证。
下面我们依次介绍如何在sklearn中使用上述三类指标进行分类器性能评估。
1、准确率
通常采用cross_value_score()这个函数,具体使用方法如下
from sklearn.model_selection import cross_val_score
cross_val_score(estimator, train_x, train_y, cv, scoring="accuracy")
其中,estimator即为我们要评估的分类器
cv为整数时,默认为KFold或StratifiedKFold。我们也可以自己设计交叉验证模式,具体见以前的博客。
但是准确率在处理偏斜类时,性能指标不客观。
混淆矩阵
评估分类器性能的更好方法就是混淆矩阵。
要计算混淆矩阵,需要先有一组预测才能将其与实际目标进行比较。当然可以通过测试集来进行预测,但是现在先不要动它(测试集最好留到项目最后,准备启动分类器时再使用)。
此时我们可以用cross_val_predict()来代替。它和cross_val_score()不一样,它不是返回分数,而是返回每条样本作为cv中的测试集时,对应的模型对于该样本的预测结果。这就要求使用的cv策略能保证每一条样本都有机会作为测试数据,且不会重复,否则会报异常。
具体使用如下:
from sklearn,model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
train_y_pre = cross_val_predict(estimator, train_x, train_y, cv=cv)
matrix = confusion_matrix(train_y, train_y_pre,labels)
混淆矩阵的行代表真实类别,列代表预测类别。
train_y:样本真实分类结果
train_y_pre:样本预测分类结果
labels:是所给出的类别,通过此参数可对类别进行选择。类别顺序也可由此控制,例如labels=[2,1,0]就是依次为class2,class1,class0。
2、精度、召回率、F1
用来评判二分类器的性能好坏。如果用于多类别分类器,会报错。具体如下:
from sklearn.metrics import precision_score, recall_score
precision_score(train_y, train_y_pre)
recall_score(train_y, train_y_pre)
==精度和召回率的权衡是一个很复杂的问题。==因此我们可以很方便地将精度和召回率组合成一个单一的指标,称为F1分数。当你需要一个简单的方法来比较两种分类器时,这是个非常不错的指标。
from sklearn.metrics import f1_score
f1_score(train_y, train_y_pre)
如何绘制P-R曲线
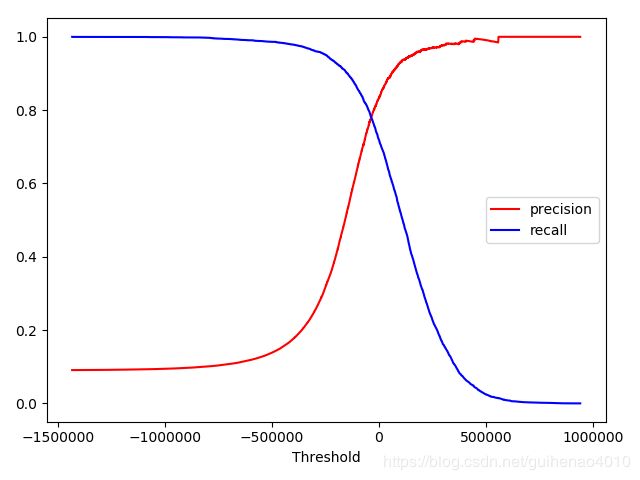
P、R的权衡和阈值切割有关系,那么如何决定使用什么阈值呢?
我们使用cross_val_predict()获取训练集中所有实例的分数,但是这次需要它返回的是决策分数而不是预测结果。
y_scores = cross_val_predict(estimator, train_x, train_y, cv=10, method="decision_function")
有了这些分数,可以使用precision_recall_curve()函数来计算所有可能的阈值的精度和召回率:
from sklearn.metrics import precision_recall_curve
precisions,recalls,thresholds = precision_recall_curve(train_y,y_scores)
plt.plot(thresholds,precisions[:-1],'r-',label='precision')
plt.plot(thresholds,recalls[:-1],'b',label='recall')
plt.xlabel('Threshold')
plt.legend()
plt.show()
还有一种找到好的精度/召回率权衡的方法是直接绘制精度和召回率的函数图
precisions,recalls,thresholds = precision_recall_curve(train_y,y_scores)
plt.plot(recalls[:-1],precisions[:-1])
plt.xlabel('recall')
plt.ylabel('precision')
plt.show()

PR曲线越往右上角越好。
3、ROC、AUC
ROC曲线是关于真正类率(即召回率)和假正类率(被错误分为的正类占负类的比例)的曲线。横轴为假正类率,总周围真正类率。
from sklearn.metrics import roc_curve
fpr,tpr,threshold = roc_curve(train_y,y_scores)
plt.plot(fpr[:-1],tpr[:-1])
plt.xlabel('假正类率')
plt.ylabel('真正类率')
plt.show()

ROC曲线越往左上角越好。
可以用AUC值评判分类器指标。AUC为ROC曲线下面的面积。
from sklearn.metrics import roc_auc_score
roc_auc_score(train_y, y_scores)