Artemis高可用性和故障转移(19)
我们将高可用性定义为系统在一个或多个服务器发生故障后继续运行的能力。高可用性的一部分是故障转移,我们将其定义为客户端连接在服务器发生故障时从一台服务器迁移到另一台服务器的能力,以便客户端应用程序可以继续运行。
1.实时备份群组
Artemis运行服务器作为有效备份组链接在一起,每个活动服务器可以有一个或多个备份服务器。一个备份服务器仅被一个活动服务器拥有。在发送故障转移之前,备份服务器无法运行,但是作为选定的备份服务器(处于被动状态)会播报自己的状态并且等待接管活动服务器的工作。
在故障转移之前,只有活动服务器为Artemis客户端提供服务,而备份服务器保持被动或等待成为备份服务器。当活动服务器崩溃或正常关闭时,当前处于被动模式的备份服务器将变为活动状态,而另一个备份服务器将变为被动状态。如果活动服务器在故障转移后重新启动,那么它将具有优先级并且是当前存活服务器关闭时成为活动服务器的首选。如果当前的活动服务器配置为允许自动故障恢复,则它将检测到之前活动服务器重新上线并自动停止。
2.HA策略
Artmis支持两种不同的策略来备份服务器共享存储和主从复制。这是通过ha-policy元素配置的,如下主从复制:
或者如下共享存储
除了这两种策略外,还有第三种叫做live-only的策略。这意味着没有备份策略,这个是默认的策略,没有提供备份。
注意,只有持久化消息数据才能在故障切换时存储下来,任何非持久化消息数据在故障切换后都将不可用。
ha-policy配置配置集群使用哪种策略来提供服务器数据的备份。还可以在此元素中配置服务器在集群中的角色,可以是主服务器(活动),从服务器(备份)或共享服务器(活动和备份),主服务器配置:
从服务器配置:
活动和备份服务器:
3.数据主从复制
当使用主从复制时,活动和备份服务器不共享相同的数据目录,所有数据同步都通过网络完成。活动服务器接收所有(持久)数据并复制到备份服务器。当备份服务器启动时,备份服务器先需要同步来自活动服务器的所有现有数据,然后才能在活动服务器失效后替换其地位。与使用共享存储时不同,主从复制备份在启动后在完成与活动服务器同步数据完成之前,备份服务器不是完全可操作的。发生这种情况所需的实际取决于要同步的数据量和连接速率。
注意,通常同步是在当前网络中并行执行的,因此不会对当前的客户端造成任何堵塞。但是在此过程结束时,有一个关键时刻,备份服务器必须完成同步并确保副本确定复制完成,备份服务器和副本之间的这种交流将阻止任何与日志相关的操作,由此交流将阻塞的最长时间由initial-replication-sync-timeout配置选项定义。
需要注意的是,当成功进行故障转移后备份服务器的数据将比活动服务器的数据更新。如果将活动服务器配置为在重新启动时对活动服务器进行故障恢复,则会同步备份服务器数据。如果两个服务器都被关闭,管理员需确定哪个服务器具有最新数据。
主从复制的活动和备份服务器必须是集群的一部分,集群连接还定义了备份服务器如何找到要匹配的远程活动服务器,注意如下:
- 活动和备份服务器必须属于同一个集群,即使是简单的活动/备份复制也需要集群配置。
- 他们使用的集群用户和密码必须匹配。
在集群中,备份服务器有两种方式来定位一个活动服务器进行复制,如下:
- 指定节点主,可以指定备份服务器可以连接到的活动服务器。通过在主和从服务器中配置group-name,备份服务器只连接到相同组名的活动服务器。
- 连接到任何活动服务器,如果group-name没有配置,运行备份服务器连接到任何活动服务器。
使用group-name例子,假设有5个活动服务和6个备份服务器:
live1,live2,live3:with group-name = fish
live4,live5:with group-name = bird
backup1,backup2,backup3,backup4:with group-name = fish
backup5,backup6:with group-name = bird
即加入集群后,group-name = fish的备份服务器将搜索与group-name = fish配对的实时服务器。 由于有多一个备份,因此将保留一个备用备份。group-name = bird(backup5和backup6)的2个备份将与live服务器live4和live5配对。
备份服务器将搜索配置为需要连接任何的活动服务器。它会尝试连接每个活动服务器,直到找到当前没有备份的活动服务器,如果没有可用的活动服务器,它将等待直到收到集群拓扑发送改变信息并重复该过程。
注意,在共享存储备份中,如果备份服务器启动但未找到活动服务器,这服务器仅将被激活并开始为客户端请求提供服务。在主从复制的情况下,备份服务器需要等待实时服务器与之配对。在主从复制中,备份服务器不知道它具有的数据是否是最新的,因此它无法决定自动激活。要使用其拥有的数据并激活备份服务器,管理员需要通过更改其配置将slave更改为master来使其成为活动服务器。
和共享存储的情况类似,当活动服务器停止或崩溃时,备份服务器将变为活动状态并接管活动服务器职责。具体来说当备份服务失去与活动服务器的连接时,备份服务器将变为活动状态,这可能会有问提,因为这可能是由于临时网络问题而发生的。为了解决这个问题,备份服务器将尝试确定它是否可以连接到集群中的其他服务器。如果它可以连接到超过一半服务器,它将变为活动状态,如果超过一半的服务器也随着实时服务器消失,备份服务器将等待并尝试重新连接到活动服务器,避免了脑裂问题。
如下主从复制的主服务器配置如下:
...
...
主从复制策略的ha-policy的所有主服务器配置元素如下:
- check-for-live-server:是否在启动时使用自己的服务器ID来检测机器中的(活动)服务器,只有在复制服务器上执行故障恢复(fail-back)时才需要此选项。
- cluster-name:主从复制的集群名称,仅在配置多个不同的集群时才需要设置此值。如果已配置,在连接到集群时使用具有此名称的集群所配置的连接器进行连接,以发现活动服务器是否已在运行。如果没有设置,则使用默认的集群连接(第一个配置)。
- group-name:如果设置,备份服务器仅会匹配拥有相同组名的活动服务器。
- initial-replication-sync-timeout:复制服务器在完成初始复制过程时等待确认它是否已经接受到所有必须数据的等待时间。默认值为30000s,注意在此期间,将阻止任何与日志相关的操作。
主从复制策略的ha-policy的所有备服务器配置元素如下:
- cluster-name:是有主从复制的集群名称,仅在配置多个不同的集群时才需要设置此值。如果已配置,在连接到集群时使用具有此名称的集群所配置的连接器进行连接,以发现活动服务器是否已在运行。如果没有设置,则使用默认的集群连接(第一个配置)。
- group-name:如果设置,备份服务器仅会匹配拥有相同组名的活动服务器。
- max-saved-replicated-journals-size:指定了复制备份服务器在开始迁移其文件后可以重启的次数,一旦有这么多备份日志文件,服务器将在故障恢复后永久停止。
- allow-failback:当一个服务器请求取代它的位置时,服务器是否会自动停止,此配置用于故障恢复的时候。
- initial-replication-sync-timeout:故障转移后,从服务器做为新的活动服务器启用此设置。复制服务器在完成初始复制过程时等待确认它是否已经接受到所有必须数据的等待时间。默认值为30000s,注意在此期间,将阻止任何与日志相关的操作。
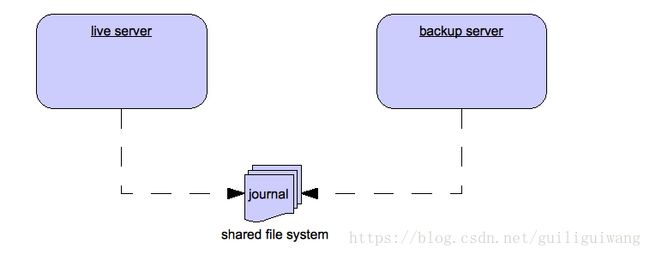
4.共享存储
使用共享存储是活动服务器和备份服务器共享同一目录数据。当发生故障转移时备份服务器接管后,备份服务器将从共享文件中加载持久化数据,并且客户端可以连接到它。
共享存储需要一个备份服务器和活动服务器可访问的共享文件系统,通常可以使用高性能的存储区域网络(SAN)。不建议使用网络附属存储(NAS),例如NFS用来存储共享日志(NFS很慢)。
共享存储高可用性的优点是活动和备份节点之间不会发生复制,这意味着它不会因正常操作期间的复制开销而受到任何性能损失。缺点是需要共享文件系统,并且当备份服务器激活时,需要从共享存储加载数据,需要一些时间,具体取决存储的数据量。如果在正常操作期间需要最高性能,则可以访问快速SAN但是稍慢的故障转移(取决于数据量)。
共享存储主服务器配置例子如下:
...
...
从服务器配置例子如下;
需要注意活动节点和备份节点都需要定义集群连接,即使当不作为集群一部分的时候。 群集连接信息定义备份服务器如何向其实时服务器或群集中的任何其他节点通知其存在。
共享存储策略的ha-policy的所有主服务器配置元素如下:
- failover-on-server-shutdown:如果设置为true,当服务器停止时,其备份服务器将进行故障转移变为活动状态。如果为false,则备份服务器继续保持被动状态不进行故障转移。
- wait-for-activation:如果设置为true,服务器等待被激活后开始启动。如果设置为false,这服务器将在后台完成启动。默认为false。
共享存储策略的ha-policy的所有从服务器配置元素如下:
- failover-on-server-shutdown:在备份服务器已经被激活的情况下。设置为true,表示当服务器停止时,其备份服务器将进行故障转移变为活动状态。如果为false,则备份服务器继续保持被动状态不进行故障转移。
- allow-failback:当一个服务器请求取代它的位置时,服务器是否会自动停止,此配置用于故障恢复的时候。
5 故障恢复
在活动服务器发生故障并且备份服务器已经接替其职责之后,如果需要重新启动活动服务器并进行故障恢复。
5.1 共享存储故障恢复
要启用当主服务器关闭时进行故障转移,在主服务器或者从服务器上的ha-policy配置元素failover-on-shutdown设置为true,如下所示:
true
默认情况下failover-on-shutdown为false,在此参数为false情况下仍然希望主服务器停止时进行故障转移,可以使用管理API进行操作。
在共享存储情况下,需要重新启动原始的活动服务器并终止新的活动服务器进程。可以在从服务器中将allow-fail-back设置成true,这将强制已生效的备份服务器自动停止,进行故障恢复。配置如下:
true
5.2 主从复制故障恢复
在主从复制模式下,需要在主服务器中配置check-for-live-server设置为true,用来开启在主服务器启动期间,主服务器将使用其nodeID在集群汇总搜索另一个服务器,如果找到一个,它将连接该服务器并尝试故障恢复。由于这是远程复制方案,其开始成为主服务器必须与使用其ID相对运行的服务器进行数据同步,一旦同步成功,它将请求这个服务器要接替它的职责并让其关闭服务器进程。这个配置是必须的,否则主服务器无法知道是否需要故障转移,以及是否有存在执行其职责的服务器仍然在运行,配置如下:
true
需要注意的是,如果在发生故障转移后重新启动活动服务器,则必须将check-for-live-server设置为true。 如果不是,则实时服务器将重新启动并为服务器提供备份已处理的相同消息,从而导致重复复制。
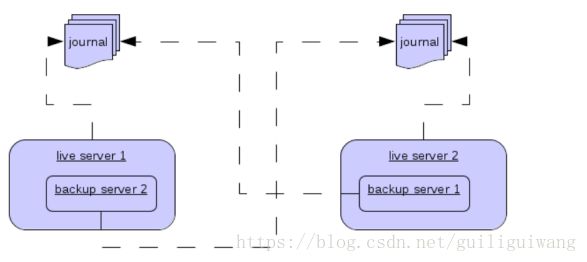
6.托管备份服务器
可以在单机同一JVM中同时运行一个备份服务和活动服务(共享服务)。活动服务可以配置使用与另一个活动服务在同一个JVM中的备份服务作为它的备份服务器,这个备份服务可以使用共享存储或主从复制。这个新的备份服务将从启动它的活动服务中继承除了名称之外的其他配置,其名称将会自动被设置为colocated_backup_n 其中n为创建的备份服务器的个数,以及后面要说的任何目录、连接器、接收器的名称规则。活动服务可以被配置为允许备份请求同时还可以配置可以启动的备份服务的数量,这样可以在集群周围均匀的分布备份服务。配置例子如下:
托管备份策略的所有ha-policy元素配置选项如下:
- request-backup:如果为true,服务器将向另一个节点请求备份服务。
- backup-request-retries:活动服务器尝试请求备份服务的次数,-1值以为着永远。
- backup-request-retry-interval:每次尝试请求备份服务的等待间隔时间。
- max-backups:一个活动服务器能创建多少个备份服务器。
- backup-port-offset:创建新备份服务器的接收器和连接器的端口偏移量。
如上配置例子使用主从复制,在这种情况下,主服务和从服务必须与正常的主从复制相匹配。也支持共享存储,如下图。
日志目录、大型消息和分页的配置根据HA的策略而定。如果是共享存储,请求服务器会通知目标服务器所使用的目录。如果是主从复制则将从创建其服务的服务器中继承,但是会在备份目录下添加新的备份名称目录。
如果HA的策略是托管备份,其连接器和接收器从活动服务中继承,并根据backup-port-offset中的值对端口进行偏移。例如如果值为100,且连接器使用端口61616,则对于创建的第一个服务器,将设置为5545,第二个服务器将设置为5645,依次类推。对于接收器和连接器的id将被附加到colocated_backup_n,其中n是备份服务器编号。
可能存在某些连接器配置为外部服务器,应该从偏移中排除,不应该对其进行偏移。例如,集群连接使用的连接器用于复制备份服务器的仲裁投票,我们在托管备份策略中配置来忽略这些连接器。
remote-connector
.........
7.集群规模缩小
另一种使用活动/备份组是通过配置缩小规模,当配置为缩小规模时,服务器可以将其所有消息和事务状态复制到另一个服务器。这样做的好处是不需要完全备份来提供某种形式的HA,缺点是它只处理服务器被正常停止而不是服务器崩溃,另一个缺点是可能丢失消息排序。例如有两个实时服务器,并且来自一个生产者的消息在两个服务器之间均匀分布,如果其中一个服务器关闭,那么在这台服务器中的消息将发送给另外一个服务器中的队列。服务器1有消息1,3,5,7,9而服务器2有消息2,4,6,8,10,如果服务器2关闭,服务器中的消息顺序为1,3,5,7,9,2,4,6,8,10。
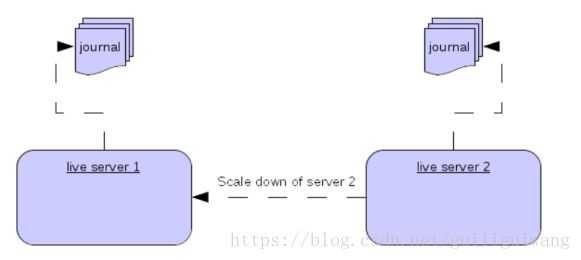
集群规模缩小配置如下:
server1-connector
除了指定连接器,也可以使用发现组,如下配置例子:
也可以配置规模缩小,仅将消息发送到同一组服务器,配置例子如下:
...
my-group
7.1 规模缩小和备份
缩小规模也可以和备份服务混合使用。如果在备份服务器中配置了scale-down,当故障转移后,备份服务器不会完全启动,而是将消息转移到另一个实时服务器。最合适的是通过使用托管备份,意味着当启动实时服务器时,它们将自动由实时服务器自动备份,并且当关闭实时服务器时,可以在另一个实时服务器上使用。配置例子如下:
44
33
3
false
33
purple
true
abcdefg
tiddles
22
33rrrrr
false
boo!
7.2 缩小规模和客户端
当服务器停止并准备缩小集群规模时,其将向所有客户端发送一条消息,通知它们断开连接,此时客户端将重新连接,但是只有在服务器完成scaledown后,客户端才会连接成功。这是为了确保重新连接的客户端的任何状态如队列和事务。当客户端重新连接时,将应用正常的重新连接设置,因此这些设置应足够高以处理规模缩小所需的时间。
8.故障转移模式
Artemis定义了两种类型的客户端故障转移
- 客户端自动故障转移
- 应用程序级客户端故障转移
Apache ActiveMQ Artemis还提供100%透明的自动重新连接到同一服务器的连接(例如,在出现暂时的网络问题时)。 这与故障转移类似,不同之处在于它重新连接到同一服务器。在故障转移期间,如果客户端在任何非持久或临时队列上具有消费者,则在备份节点上的故障转移期间将自动重新创建这些队列,因为备份节点不知道非持久性队列。
8.1 客户端自动故障转移
Artemis客户端可以配置为接收所有活动和备份服务器的信息,以便能收到连接失败事件,客户端检测到此情况并重新连接到备份服务器。然后,备份服务器将在故障转移之前会自动为每个连接创建会话和消费者。从而使用户不必手动编写自动重新连接逻辑。
Artemis客户端在client-failure-check-period设定的时间内未接受到服务器数据包时检测出链接失败,客户端会尝试进行故障转移,此外,如果操作系统关闭套接字,如果服务器进程被终止而不是机器本身崩溃,则客户端将立即进行故障转移。Artemis客户端配置为以多种不同方式发现实时-备份服务器组列表。它们可以显式配置,或者最常见的方法是使用服务器发现来让客户端自动发现列表。有关如何配置服务器发现的完整详细信息,请参阅群集。或者,客户端可以显式连接到特定服务器并下载当前服务器和备份,请参阅群集。
要启用自动客户端故障转移,必须将客户端配置为允许non-zero重新连接尝试。默认情况下,故障转移仅在与实时服务器建立至少一个连接后才会发生。换句话说,默认情况下,如果客户端无法与实时服务器建立初始连接,则不会发生故障转移 - 在这种情况下,它将根据reconnect-attempts属性重新尝试连接到实时服务器,并在此数量后尝试连接失败。
8.2 初始连接故障转移
由于客户端在获取第一次连接之后才获悉完整拓扑,因此存在不知道备份的窗口。如果此时发生故障。则客户端只能尝试重新连接到原始活动服务器,需要配置客户端尝试连接次数,可以在URL中设置参数initialConnectAttempts,默认值为0,即尝试一次,一旦尝试次数超过配置,将抛出异常。
8.3 在故障转移期间处理阻塞调用
如果客户端代码对服务器处于阻塞调用中,等待响应后开始继续执行,当发生故障转移时,新会话将不知道正在进行的调用,此调用可能会永远挂起,等待永远不会发生的响应。为了防止这种情况,Artemis在使用JMS将会抛出javax.jms.JMSException或抛出异常ActiveMQException异常代码为ActiveMQException.UNBLOCKED的来取消在故障转移时正在进行的任何阻塞调用。 客户端代码可以捕获此异常并根据需要重试任何操作。
如果被解除阻塞的为调用方法commit()或prepare(),那么事务将自动回滚,Artemis如果使用JMS将抛出javax.jms.TransactionRolledBackException,若使用CORE API抛出异常ActiveMQException异常代码为ActiveMQException.TRANSACTION_ROLLED_BACK。
8.4 处理事务故障转移
如果会话是事务性的并且已在当前事务中发送或确认消息,则服务器无法确保在故障转移期间发送的消息或确认没有丢失。因此,事务将被标记为仅回滚,并且任何后续提交它的尝试将抛出javax.jms.TransactionRolledBackException(如果使用JMS),若使用CORE API抛出异常ActiveMQException异常代码为ActiveMQException.TRANSACTION_ROLLED_BACK。
注意,对此规则的告警是用过使用JMS或者CORE API使用XA(分布式事务)时。如果使用2阶段提交并且已经调用了prepare(),那么回滚将导致HeuristicMixedException异常,因为此时调用commit将抛出XAException.XA_RETRY异常。这通常事务管理器应该在稍后的某个时间点重试提交,这样做的副作用是任何非持久性消息都将丢失。为避免这种情况,请在使用XA时使用持久消息。通过使用确认消息,这不是问题,因为它们在准备调用之前被刷新到服务器。
用户可以捕获异常,并根据需要执行任何客户端的代码回滚。无需手动回滚会话-它已经回滚了。然后可以在同一会话上再次重试事务操作。如果在执行提交调用时发生故障转移,则服务器(如前所述)将取消阻塞调用以防止挂起,因为没有响应返回。在这种情况下,客户端不容易确定在发生故障之前是否在实时服务器上实际处理了事务提交。
注意。如果通过JMS或CORE API使用XA,则抛出XAException.XA_RETRY。这是为了通知事务管理器在某个时刻应该重试。在稍后的某个时间点,事务管理器将重试提交。如果原始提交尚未发生,那么它仍将存在并被提交,如果它不存在则假定已提交,尽管事务管理器可能会记录告警。
为了解决这个问题,客户端可以简单地启用事务中的重复检查(重复消息检测)。如果事务在故障转移之前已经在活动服务器上提交了,那么事务重试时,重复检测将确保在服务器重新发送的任何持久消息将被忽略,以防止它们被多次发送。
注意,通过部分回滚异常并重试,不会解除阻塞调用并启用重复检测,可以在发生故障时提供有且只有一次的消息传递保证,保证100%不丢失或者发送重复消息。
8.5 处理非事务消息的故障转移
如果会话是非事务性的,则在发生故障转移时可能会丢失消息或消息确认。如果希望为非事务会话提供有且只有一次的消息传递保证,需要启用重复检测,并且捕获接触阻塞异常如8.3所述(在故障转移期间处理阻塞调用)。
8.6 获取连接失败通知
JMS提供了一种标准的机制,用于异步通知连接失败:java.jms.ExceptionListener。
Artemis的core API以类似的方式提供了此功能:org.apache.activemq.artemis.core.client.SessionFailureListener
ExceptionListener或者SessionFailureListener实例将在连接失败时被调用,无论连接是否成功进行故障转移、重新连接或者重连成功。但是可以通过在连接失败时SessionfailureListener传入的failedOver 标志或者javax.jms.JMSException的异常代码来发现是否进行了重新连接或重连成功。
JSMException异常码如下:
- FAILOVER:发生故障转移时并且已经重新连接或者重连成功。
- DISCONNECT:没有故障转移并且连接断开。
8.7 应用程序级故障转移
在某些情况下,您可能不希望自动客户端故障转移,并且更喜欢自己处理任何连接故障,并在您自己的故障处理程序中编写您自己的手动重新连接逻辑。 我们将其定义为应用程序级故障转移,因为故障转移是在用户应用程序级别处理的。
要实现应用程序级故障转移,如果您正在使用JMS,则需要在JMS连接上设置ExceptionListener类。 如果检测到连接失败,Artemis将调用ExceptionListener。 在ExceptionListener中,您将关闭旧的JMS连接,可能从JNDI查找新的连接工厂实例并创建新连接。
如果使用的是CORE API,过程类似,在ClientSession实例上设置FailureListener。
9.服务器复制说明
Artemis不会在活动和备份服务器自己复制完整的服务器状态。当在备份上自动重新创建新会话时,它将不知道该会话中的消息已发送或已确认。故障转移时的任何正在进行的发送或确认也可能丢失。
通过复制完整的服务器状态,理论上我们可以提供100%透明的无缝故障转移,这将避免任何丢失的消息或确认,但是这需要很高的成本:复制完整的服务器状态(包括队列,会话等)。这将需要复制整个服务器状态机;实时服务器上的每个操作都必须以完全相同的全局顺序复制到副本服务器上,以确保一致的副本状态。以高性能和可伸缩的方式执行此操作非常困难,尤其是当考虑多个线程同时更改实时服务器状态时。可以使用诸如虚拟同步之类的技术提供完整的状态机复制,但是这不能很好地扩展并且有效地将所有操作序列化到单个线程,从而大大降低了并发性。存在用于多线程主动复制的其他技术,例如复制锁定状态或复制线程调度,但这在Java中很难实现。
因此其决定了不值得为了实现100%透明的故障转移来降低性能和和并发性。即使没有100%透明的故障转移,通过使用重复检测和重试事务的组合,即使在发生故障的情况下也可以保证一次且仅一次交付。但是,这对客户端代码不是100%透明的。。
注:此系列文章为Apache Artemis V2.6.2官方使用文档的简要翻译文档(非完全按照官方文档排版进行翻译,有删减),个人能力有限如有错误请谅解。源文档地址:http://activemq.apache.org/artemis/docs/latest/index.html