浅谈PageRank
1996年,两位还在斯坦福大学攻读计算机理学博士学位的研究生,开始了一项研究:如何对互联网上“成万上亿”的网页进行排序。在当时看来,这只是发生在斯坦福的一个普通课题研究而已,然而包括其研究者在内,都没有意识到,这项研究最后的成果,会引发互联网搜索引擎领域一个划时代的变革。
这两位博士的名字相信大家都很熟悉了,他们正是后来大名鼎鼎的Google公司的创始人:拉里佩奇(Larry Page)和谢尔盖布林(Sergey Brin)。而Google作为全球最大的搜索引擎,在其创立之初,使用的核心算法正是我们今天要讲的PageRank.
搜索引擎的发展瓶颈
搜索引擎的根本用途在于根据用户的查询,快速而准确地从网络的海洋中找到用户最需要的网页。这是针对网页的一类特殊的信息检索过程。它主要有以下两个特点:
- 搜索的数据量相当大
- 搜索的数据之间质量参差不齐
因此,基本的解决思路是根据查询,对这些网页进行排序,按照对用户搜索目的的判断,将最符合用户需求的网页依次排在最前面。也就是说,搜索引擎要解决的最主要问题是对网页排序模型的设计。
佩奇和布林两个人开始这项研究的缘由来自于导师的提议,因为当时搜索引擎的发展遇到了瓶颈——缺乏合理的排序算法。在1998年之前(也就是PageRank正式问世的那一年之前),即便是当时最先进的搜索引擎,也是主要依靠以关键词词频为核心的排序技术(这一点在文档检索中保持了旺盛的生命力,我们到现在还主要依靠” TF(词频)×IDF(逆向文件频率) ”模型为搜索结果排序)。但是在搜索引擎技术中,依赖于词频的模型有其天然缺陷:网页排序的结果仅仅考虑了基于关键词的相关度判断,而未考虑网页本身的质量。显而易见的是,海量的网页来自不同的制造者,质量一定是参差不齐的。可以想象,如果有一些低质量的网页对于某些词的词频很高,这相当于是一个人一直在无意义的絮叨某句话,虽然毫无信息量可言的垃圾,却在基于关键词的模型下如鱼得水,一旦其中某个词被查到,立即能“崭露头角”。这一点在当时正是阻碍搜索引擎发展的最大困难。比如,令人感到讽刺的是,在1997年,堪称早期互联网巨子的当时四大搜索引擎在搜索自己公司的名字时, 居然只有一个能使之出现在搜索结果的前十名内,其余全被这种垃圾网页挤到后面去了[1]。
总结一下,网页排序的任务中,最核心的难点在于判别网页质量。如果网页数量很少,这件事就简单了,靠人工赋予其得分即可,但实际情况是:互联网山网页如大海般浩瀚,且新的网页不断产生,旧的网页也在不停变化,这是人工所不可能完成的任务。我们只能依靠计算机和算法,自动评估网页质量。于是,当时正在读博的佩奇和布林想到了学术论文的质量判别方法:依靠文章的引用情况。一篇论文的好坏当然与它的引用直接相关,有多少文章引用,什么样级别的文章在引用,才是判断一个文章质量最“靠谱”的标准。这一点放在网页排序上也是一样,论文的引用相当于就是网页的链接,不论某个网页再怎么在关键词方面做“手脚”,没人愿意链接你,那还是白扯。于是,作为一门学问的“链接分析”就此产生了,这一点也是PageRank算法最基本的原理。
链接分析
根据上面的分析,我们可以将互联网上的网页模拟为一个节点,而这个网页的“出链”看做是指向其他节点的一条“有向边”,而“入链”则是其他节点指向这个节点的有向边。这样整个网络就变成了一张有向图。事情到此就显得容易解决了,因为我们用图论中最普通的有向图模型,完成了对此类问题的建模。具体的说,网页质量的评估是遵循以下两个假设的:
- 数量假设:一个节点(网页)的入度(被链接数)越大,页面质量越高
- 质量假设:一个节点(网页)的入度的来源(哪些网页在链接它)质量越高,页面质量越高
但是现在还面临着一个问题,就是既然一个网页A的质量与链接它的页面质量相关,而链接A的那些页面(我们记为B)的质量又与链接B们的页面相关。以此类推下去,好像进入了一个无穷无尽的死循环。为了解决这个问题,两颗聪明的大脑又想到,也许可以用数学中随机过程的“随机游走模型”解决这个问题。随机游走模型又称“醉汉模型”,指的是事物当前的状态只与其上一个状态有关,而与其再之前的状态无关。就好比一个醉汉,他这一步走到哪里只跟他上一步在哪里有关,这有点接近于物理学中常讲的“布朗运动”。用户上网也可以看做是一个类似的过程。我们可以假设,初始状态时,用户访问所有页面的概率都是等大的,而每次访问过后,用户会依照此时该页面中给出的链接以相等概率访问链接所指向的页面,那这就好比是用户在刚刚我们所说的有向图上做“随机游走”。所以,通过对这种随机游走的概率分析,我们就能得到用户在上网时,停留在哪一个网页上的概率要大一些,概率越大的,表示其质量越高。
PageRank
现在,我们将上面的两个假设以及随机游走模型数学化。如果说最终的目的是要为每个网页赋予一个得分的话,那么在初始化阶段,所有网页的得分应该是相等的,假设现在一共有 N 个网页,那么初始阶段用户访问每个网页的概率就是 1N ,比如下图中的初始概率向量为 (1/4,1/4,1/4,1/4) ,而因为每个网页都可能存在着到其他任何网页的链接,所以,我们可以将这些链接以平均的概率表示成一个概率转移向量。比如下面这张图,(图的来源:PageRank算法–从原理到实现)网页A中有3个链接,分别指向B, C, D,则A的概率转移向量为 (0,1/3,1/3,1/3) ,向量的维度依次对应的是网页A指向A, B, C, D四个网页的概率。
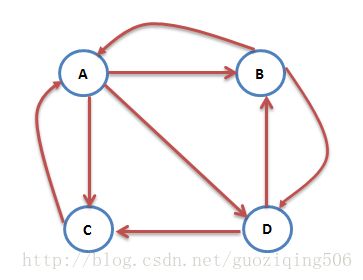
显然,每个网页都有这样一个概率转移向量,我们把这些向量转置后(按列放置)合起来就是随机过程中经典的概率转移矩阵了,如下:
不难理解,这种概率转移矩阵的一个显著的特征是每个元素都 ≥0 ,且列和为1,含义表示从当前网页跳转到其他网页的概率和为1。我们记这个矩阵为 T , T[i][j] 的含义是既可以表示由网页 i 跳转至网页 j 的概率,又可以表示由网页 j 跳转至网页 i 的概率。
根据这个矩阵,我们能够计算出经过一次网页跳转之后,用户访问到每个网页的概率分布,比如上图中,经过一次跳转之后,用户访问到各个网页的概率可以如下计算:
其中, T 为概率转移矩阵。同理,我们可以按照这个方法持续计算到用户第 n 次跳转之后的概率分布,公式如下:
佩奇和布林发现,当 n→+∞ ,且概率转移矩阵 T 满足以下3个条件时, limn→+∞Vn 最终收敛,保持在一个稳定值附近。
T 为随机矩阵。即所有 T[i][j]≥0 ,且的所有列向量的元素加和为1, ∑ni=1T[i][j]=1
T 是不可约的。所谓不可约是说 T 所对应的图示强连通的,即图中任何一个节点都可以达到其他任何一个节点,它要求概率转移矩阵不存在某些特殊情况,比如某个列向量都为0,即有一个网页没有链接到任何其他网页,我们把这类情况又称为终止点;或者是在概率转移矩阵的主对角线上,存在有一个元素为1的情况,即这个网页链接只链接它自己,我们把这类情况又称为陷阱。这两类特殊的情形在后面会详细说。
T 是非周期的。所谓周期性,体现在Markov链的周期性上。即若A是周期性的,那么这个Markov链的状态就是周期性变化的。因为A是素矩阵(素矩阵指自身的某个次幂为正矩阵的矩阵),所以A是非周期的
比如上面这个例子中, limn→+∞Vn=limn→+∞Tn⋅V0=(3/9,2/9,2/9,2/9)T
这表明,经过足够多次的网页跳转,用户停留在网页A的概率要比停留在B, C, D的概率高,而后三者基本是等概率的。经过这样的计算得到的每个网页的概率值也叫PR值,是评估网页质量的依据。也就是说,在我们使用搜索引擎时,在保持网页与查询一定相关度的基础上,PR值可以提供非常不错的排序依据。
终止点和陷阱
然而,现在存在的问题是,上面的所有推导都是建立在理想状态下的,即假设所有网页组成的这个有向图是强连通的。但是实际上,网页形形色色,总有那么一些“奇葩”存在,从而在PageRank中,对算法会产生“恶劣”影响,基本上有2种情况:终止点和陷阱。
终止点
终止点指的是没有任何出链的网页。可以想象,按照上面这种随机游走模型,用户访问到这个网页后,因为找不到链接,就会“四顾茫然”,不知下一步该怎么办了。比如下图中,网页C没有出链。这种情况下,概率转移矩阵在终止点对应的那一列,所有元素都是0,代入上面的PR值计算公式,会发现经过无穷多次跳转后,所有网页的PR值都是0:
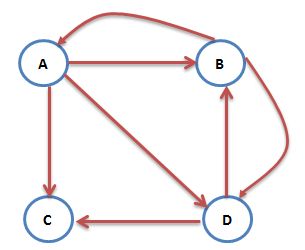
上图对应的概率转移矩阵为:
可见,对应C的第3列全为0,迭代计算PR值,最后的结果都是0:
那这样的计算结果当然是毫无意义的。
陷阱
陷阱指的是只有指向自身链接的网页。这种情况下,所有“随机游走”的用户到了这个网页后,就如同进了黑洞一般,一直在里面“打转”,出不来了。比如下图中,网页C只有一条出链,并且还是指向它自己的,这就把C变成了陷阱。
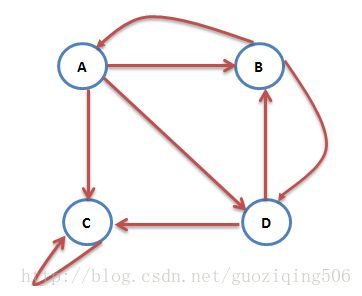
有陷阱的网络对应的概率转移矩阵中,主对角线上存在至少一个为1的元素(主对角线存在 n 个1,就代表整个网络中有 n 个陷阱)。
这种情况下,陷阱的PR值为1,而其他正常网页的PR值为0。迭代计算的结果大致如下:
当然,这种结果也是毫无参考意义的。
解决思路
为了解决这两个致命的问题,佩奇和布林想到,他们最初定义的用户的上网模型是不够准确的,因为用户不是傻乎乎的机器,他们是具有聪明大脑的人,当一个人遇到终止点或者陷阱的话,他不会不止所错,也不会无休止地自己打转,他会通过浏览器的地址栏输入新的地址,以逃离这个网页。也就是说,用户从一个网页转至另一个网页的过程中,会以一定的概率不点击当前网页中的链接,而是访问一个自己重新输入的新地址。我们可以依照这个原理修正之前的概率转移公式,如下:
其中, α 为用户继续点击当前网页中的链接的概率, (1−α) 为用户通过地址栏“逃离”的概率。关于这里的 α ,其实很讲究,首先 α 不能太大,因为 α 的大小与算法的收敛速度呈反比,
α 太大会导致算法收敛慢而影响性能;其次, α 也不能太小,因为PageRank的精华就在于上面的公式中前一部分——由概率转矩阵的多次迭代计算得到PR值。所以,最终两位博士将 α 值定为0.85.
我们来看经过这样处理之后,上面的终止点和陷阱问题能否得到解决:
当存在终止点时,迭代的结果为:
当存在陷阱时,迭代的结果为:
这样就解决了终止点与陷阱的问题。
PageRank的不足
PageRank的优点太明显,从它取得的巨大成功就可见一斑。但是他也并非十全十美,文献[2]总结了PageRank的一些缺点,我将它们摘抄如下:
第一,没有区分站内导航链接。很多网站的首页都有很多对站内其他页面的链接,称为站内导航链接。这些链接与不同网站之间的链接相比,肯定是后者更能体现PageRank值的传递关系。
第二,没有过滤广告链接和功能链接(例如常见的“分享到微博”)。这些链接通常没有什么实际价值,前者链接到广告页面,后者常常链接到某个社交网站首页。
第三,对新网页不友好。一个新网页的一般入链相对较少,即使它的内容的质量很高,要成为一个高PR值的页面仍需要很长时间的推广。
结语
当今的搜索引擎当然与20年前不可同日而语,PageRank早已不是唯一的网页质量评估算法了,比较主流的搜索引擎用到的搜索算法数量成百,是一个多算法,多层次的系统。但是我们依然不能忘记搜索引擎系统曾经这一次巨大的变革,彻底改变了我们对信息检索的认识。
不得不说,PageRank是20世纪末计算机科学史上的一大奇迹,它以及其简明的逻辑,发明了迄今为止在搜索引擎领域还相当有代表性的算法,解决了数以亿计的网页质量评估问题,抛开它难以估量的商业价值不谈,就说其学术方面,这种依靠数据自身结构的学习方法,也依然还在当前很多信息检索领域启发着我们。
最后,我想以一个故事结束[1]: 2001年, 佩奇为”PageRank”申请到了专利,专利的发明人为佩奇,拥有者则是他和布林的母校斯坦福大学。2004 年 8 月, 谷歌成为了一家初始市值约17亿美元的上市公司。不仅公司高管在一夜间成为了亿万富翁,就连当初给过他们几十美元 “赞助费” 的某些同事和朋友也得到了足够终身养老所用的股票回报。作为公司摇篮的斯坦福大学则因拥有”PageRank”的专利而获得了180万股谷歌股票。2005 年 12 月,斯坦福大学通过卖掉那些股票获得了3.36亿美元的巨额收益,成为美国高校因支持技术研发而获得的有史以来最巨额的收益之一。从投资角度讲, 斯坦福大学显然是过早卖掉了股票,否则获利将更为丰厚。不过,这正是美国名校的一个可贵之处,它们虽擅长从支持技术研发中获利,却并不唯利是图。 它们有自己的原则,那就是不能让商业利益干扰学术研究。为此,它们通常不愿长时间持有特定公司的股票,以免在无形中干扰与该公司存在竞争关系的学术研究的开展。
我这里没有崇洋媚外的意思,不过我想说,美国的大学,至少是一部分名校,是有所谓的“大学精神”的。你们可以想象一下,假如两个中国学生发明了PageRank,建立了Google这样的企业,会不会有哪个学校像斯坦福这般处理所持有的股票呢?中国想建设世界一流的大学,任重而道远!
[1] 谷歌背后的数学
[2] PageRank算法–从原理到实现