多表设计
表与表之间的关系有三种:多对多、一对多、一对一。
 一对多
一对多
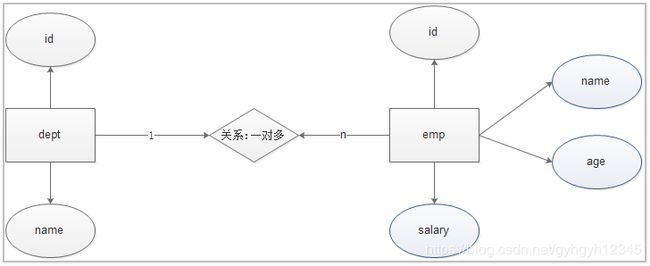
案例:记录部门中的员工信息
需求分析:
员工表和部门表
分析实体类的属性
分析实体类之间的关系
分析外键如何设置
建库》建表》添加数据》添加关系


外键约束
需求:人事部解散,将人事部删除
问题:删除人事部之后,员工表的部门id却还保留人事部。
如果删除一个部门,那么该部门中的工作人员就应该另有安排,不应该还挂在人事部下。所以,在删除一个部门之前,应该先对原人事部员工进行安排,而不应该随便就能删除一个部门。因此需要给删除一个部门添加一些限制,比如,在没有安排原人事部员工之前,无法删除部门。
给删除部门添加的限制,就可以称之为外键约束。
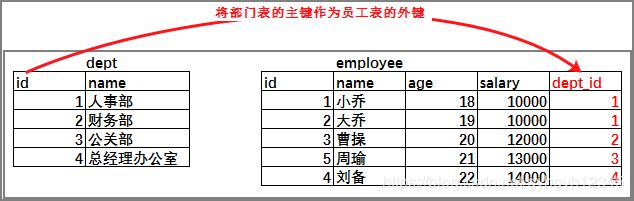 部门表和员工表之间的关系
部门表和员工表之间的关系
主表: 被引用字段的那个表—部门表(一方)
从表: 引入字段的表 — 员工表(多方)
添加外键需要注意的问题
- 如果从表要去添加一个外键约束。要求主表被引用的字段是主键或者唯一的。通常使用主键。
- 如果要删除主表中的数据。要求在从表中这个数据,要没有被引用,才可以去删除。
- 如果要向从表中去添加数据。要求在主表中,要有对应的数据。才可以去添加。
- 如果要删除表。要先删除从表。然后去删除主表。
- 新建表的时候。需要先去创建主表,然后去创建从表。
作用:保持数据的完整性,和有效性。
建表之后添加外键约束
语法 : alter table 从表名称 add foreign key (外键列的名称) references 主表名称(主键)
![]() 建表时添加外键约束
建表时添加外键约束
/创建部门表/
create table dept(
id int primary key auto_increment,
name varchar(20)
);
/创建员工表/
create table employee(
id int primary key auto_increment,
name varchar(20),
age int ,
salary double,
dept_id int,
foreign key (dept_id) references dept(id)
);
多对多
分析:程序员写项目
分析有几个实体类
分析实体类属性
分析实体类之间的关系
 表设计
表设计
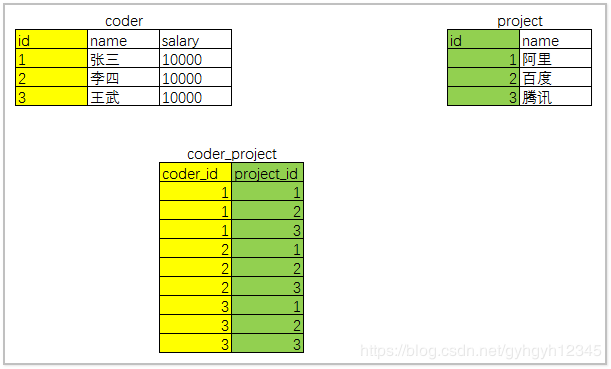 建表语句
建表语句
– 创建程序员表
create table coder (
id int primary key auto_increment,
name varchar(30),
salary double
);
– 创建项目表
create table project(
id int primary key auto_increment,
name varchar(100)
);
– 创建中间表
create table coder_project(
coder_id int,
project_id int,
foreign key (coder_id) references coder(id),
foreign key (project_id) references project(id)
);
drop table coder_project;
drop table coder;
drop table project;
注意:在创建中间表之前,先将coder和project表创建出来
由于外键约束的关系,在没有去掉中间表的外键关系之前,无法删除coder和project表中的外键相关记录。
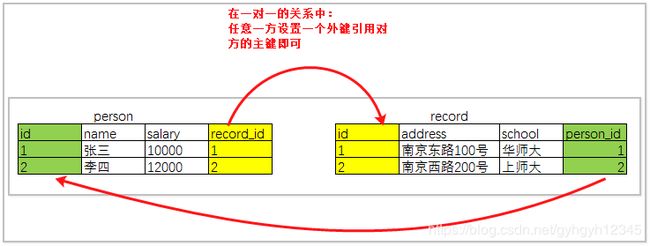
一对一
需求分析:人员信息和个人档案
分析实体类的属性
分析实体类之间的关系
分析外键如何设置
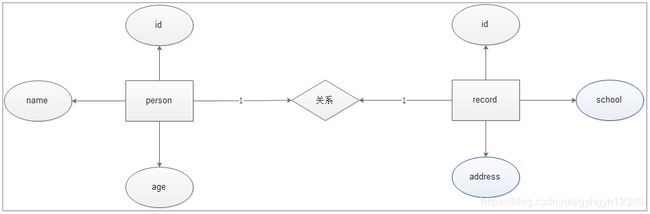 表设计
表设计
 数据库设计
数据库设计
数据库规范化
好的数据库设计对数据的存储性能和后期的程序开发,都会产生重要的影响。设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式。而范式是用来规范数据库的,并且来优化数据的设计和存储。各种范式呈递增次规范,越高的范式数据库冗余越小。也就是说性能越好。
六大范式:
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
1NF
概念:
数据库表的每一列都是不可分割的原子数据项。即表中的某个列有多个值时,必须拆分为不同的列。直到不能拆分为止。简而言之,第一范式每一列不可再拆分,称为原子性。
4.2.2 班级表
学号 姓名 班级
1 张三 一年三班
2 李四 一年二班
3 王五 二年三班
说明:
对于上述数据库表中的数据而言,由于班级这一列具有多个值(一年三班、一年二班、二年三班),可以拆分为一年,二年等。所以不满足1NF即第一范式。
举例:我想统计一年级有多少学生,那么我们会将班级这个列按照两列进行拆分,所以满足第一范式的条件。
2NF
概念:
在满足第一范式的前提下,表中的每一个字段都完全依赖于主键。
所谓完全依赖是指不能存在仅依赖主键一部分的列。简而言之,第二范式就是在第一范式的基础上所有列完全依赖于主键列。当存在一个复合主键包含多个主键列的时候,才会发生不符合第二范式的情况。比如有一个主键有两个列,不能存在这样的属性,它只依赖于其中一个列,这就是不符合第二范式。
第二范式的特点:
- 一张表只描述一件事情。
- 表中的每一列都完全依赖于主键
示例:
-
借书证表:
学生证号 学生证名称 学生证办理时间 借书证号 借书证名称 借书证办理时间
说明:上述表中学生证号和借书证号属于复合主键或者叫做联合主键。这两个主键可以确定唯一的记录。
上述表中描述了两种信息,一个是学生信息,一个是借书的信息。而第二范式要求一张表只能描述一件事情。所以不满足第二范式。
另外上述表中也不满足表中的每一列都完全依赖于主键。对于学生证名称仅依赖于学生证号,不依赖于借书证号。同理,借书证名称
不依赖于学生证号。 -
分成两张表
学生证号 学生证名称 学生证办理时间
借书证号 借书证名称 借书证办理时间
3NF:
概念:
在满足第二范式的前提下,表中的每一列都直接依赖于主键,而不是通过其它的列来间接依赖于主键。
简而言之,第三范式就是所有列不依赖于其它非主键列,也就是在满足2NF的基础上,任何非主键列不得传递依赖于主键。所谓传递依赖,指的是如果存在"A → B → C"的决定关系,则C传递依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系:主键列 → 非主键列x → 非主键列y。
这里:非主键列y间接依赖于主键列了,所以不满足第三范式。
示例:学生信息表
学号 姓名 年龄 所在学院 学院地点
说明:首先上述表满足所有列都依赖于主键学号,符合第二范式。
- 存在传递的决定关系:
学号>所在学院 >学院地点
说明:学院地点间接依赖于学号,这里不满足第三范式。 - 拆分成两张表
学号 姓名 年龄 所在学院的编号(外键)
学院编号 所在学院 学院地点
三大范式小结:
范式 特点
1NF 是对属性的原子性约束,要求属性具有原子性,不可再分解
2NF 是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
3NF 3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
本文小结
库的操作
创建库:create database 库名 character set 编码表;
删除库:drop database 库名;
查询库:show databases;
查看库的编码表:show create database 库名;
更改库:use 库名;
查看当前正在使用的库:select database();
修改库的编码表:alter database 库名 character set 编码表;
表本身的操作
创建表:create table 表名( 列名 列的类型(长度) 类的约束 ,列名 列的类型(长度) 类的约束… );
删除表:drop table 表名;
查询表:show tables;
查看表的结构:desc 表名;
查看表的编码表:show create table 表名;
修改表:alter table 表名 增/删/改 列名 列的类型(长度) 约束;
add/drop/change/modify
修改表名:rename table 旧表名 to 新表名;
表中数据的操作
增:insert into 表名(列名) values(值);
删:delete from 表名 where 条件; truncate
改:update 表名 set 列名=值 ,列名=值 where 条件 ;
查:select 列名 as 别名 ,列名 as 别名… from 表名 where 条件 group by 列名 having 条件 order by 排序.
查询排重:select distinct 列名 from 表名 where 条件;
聚合函数:
count 统计个数、sum求和、avg 平均值、max、min
在使用这几个函数进行数据的统计分析时,有时需要对数据表中的列进行数据的分组处理。group by
分组 group by :
排序:order by 列名 asc | desc;