Openstack并行性能加速
版权声明:欢迎大家转载,转载请注明出处blog.csdn.net/tantexian。
目录(?)[-]
- 摘要
- 引言
- Techniques that Dont Reuire Patches
- Running N nova-api workers
- Use quantum for Security Groups not nova-compute
- Store Keystone Tokens Using memcached
- Disable rootwrap scripts
- Increase libvirts Concurrency Limits
- Upgrade to libvirt-103
- Disable control groups
- Disable libvirt Security Drivers
- Techniques that Require Patches
- Run N nova-conductor workers
- Run N keystone Processes
- Run N quantum-server Processes
- Reduce Libvirt Call Frequency
- Coalesce Resource Manager Updates
- Make Quantums dnsmasq Callback Faster
- Make Firewall Updates More Efficent
- Speed Up OVS Agents Periodic Updates
- Backprot Race Condition Fixes
- 评测
- Benchmark
- Results
- Conclusions and Future Work
- Feedback
- Acknowledgements
在google时,看到一篇极佳的博客,Boosting OpenStack’s Parallel Performance,内容聚焦于OpenStack并发性能的,在接触OpenStack以来,很少有看到谈论OpenStack性能的文章,而这篇博客作者Peter Feiner对此问题写的极其用心,详尽而全面,故将其转载过来,并翻译一下,帖在这儿。
在开始正式的翻译之前,需要先明确一下简单的背景: Peter Feiner的这篇博客发表在今年6月份,性能改善都是在OpenStack Grizzly版本上进行的,作者贴出的诸多改善OpenStack Grizzly的parallel performance的patches目前大部分已经集成到了OpenStack Havana代码中了,还有部分patches可能会在Icehouse中集成。尽管现在在Havana版中已经享受到大神的成果,但是还是看看这篇博客,知道OpenStack中会涉及哪些性能问题,有什么改进方法,还有大神严谨的工作态度,这些都受益匪浅。
翻译过程中努力理解作者的意思,若翻译错处,敬请谅解。
好,正式开始!
摘要
OpenStack Grizzly 在并行性能(原文是:parallel performance)上表现不好。例如,在单台计算节点上,创建虚拟机的过程必须是串行的,这样就导致OpenStack在单台节点上横向扩展虚拟机数量时不是高效的。但是通过重新配置计算节点和对OpenStack Grizzly 打上一些补丁,可以将在同台计算节点上同时创建40台虚拟机并且通过ssh访问它们所需的时间降低74%。
引言
在充分利用服务器性能方面,虚拟化技术就是一个好的机制。一般,在服务器上,虚拟机作为应用的基本单元,当应用的负载增加时,就需要创建更多的机器来处理负载了,而虚拟机不能立刻创建出来,所以负载量往往被提前充分的预测了而允许创建新的虚拟机来准备服务用户请求。系统创建虚拟机的时间越长,那么就需要预测更长时期内的负载情况,而这样会导致预测的准确度下降。为了防止不准确的负载预测问题,操作人员往往需要超额配置虚拟机(over-provision virtual machines)。然而,在最理想的情况下,超额配置是低效率的,在最坏的情况,超额配置又可能不足够。因此,能够迅速的创建虚拟机是对于使用虚拟机的应用横向扩展的必须要求。此外,当横向扩展时,多个虚拟机常常会同时被请求提供服务(例如,多租户,虚拟桌面云平台),因此对于扩展来说,迅速的并行创建虚拟机是必须要具备的特征。
在几个月前的OpenStack Summit 上(作者写此文是的前几个月),我做了一个关于Scaling the Boot Barrier: Identifying $ Eliminating Contention in Openstack的演讲,主要关于在Ubuntu 12.04使用libvirt,kvm,然后在上部署OpenStack Grizzly,并行的创建虚拟机较慢的问题。我观察到,创建20台虚拟机实例比创建单台虚拟机实例多20多倍的时间,并且,并行创建虚拟机的数量增加了,创建的时间也线性增加。因为,我做实验的机器有足够的硬件资源去并行的运行20台虚拟机实例,显然的,软件资源的竞争(原文是:software contention)(例如,锁) 序列化了实例的创建。
在我演讲中,我介绍了一些鉴别software contention的技术,并举例说明了虚拟机实例创建过程中导致串行化最为糟糕的原因,还解释了我为解决一些software contention问题而写的patches。不幸的是,最初,我提供的patches并没有如我所期待的大幅提高启动时间。后面,我总结了我的演讲和大家的一些评论。现在,我要开始不负众望的实现我的承诺。
在这篇博文中,我将呈现我提供OpenStack 性能的技术。最初,我从OpenStack中移除了software contention的代码,让创建实例更加并行化。然而,一旦足够的序列化被移除了,硬件又成为了导致并行启动性能瓶颈的因子。所以,下面我将讨论的技术将高效并且消除竞争。
这些技术分为两类: 需要对OpenStack打补丁的和不要的。一般的patches已经被接受了或快完成review了。所以我希望所有的patches都能够包含到OpenStack Havana中。 后者只是OpenStack配置上的改变,你可以应用到OpenStack Grizzely集群中去(在havana版本中,这些配置应该同样很有帮助。)
Techniques that Don’t Reuire Patches
在Ubuntu12.04上,OpenStack和libvirt的默认配置导致了虚拟机实例创建的高度串行化。这一节就讨论改变配置来提升并行性能。
Running N nova-api workers
Nova-api直接访问数据库(注意:这是说的Grizzly版)。 Since the database connection driver is typically implemented in a library beyond the purview of eventlet's monkeypatching(ie, a native python extension like _mysql.so),(这句话我的理解是:数据库连接驱动的实现是基于一个库,而这个库不能用eventletmokeypatch改造。从后文中还提到过,应该是这个意思),阻塞的数据库调用操作会阻塞所有的eventlet协程。因为nova-api的大部分工作就是访问数据库, 一个nova-api进程处理请求是串行的。
你可以简单的运行多个nova-api进程来缓解这个问题。 假如,你需要并行的启动40个虚拟机实例,那么在nova.conf中设置osapi_compute_workers=40。所有的nova-api进程都会在主进程在http socket上调用了listen函数之后创建出来。 现在,当一个client连接到server上来时,那么会存在一个nova-api进程从中竞争获胜出来处理请求。因此,你有N个nova-api进程,至少可以并行处理N个client请求。一个进程不太可能在一个时刻处理1个以上的请求, 因此在一个nova-api进程中串行处理数据库调用没多大实际意义。
需要注意的是,还存在其他方法可以用来阻止数据库调用时导致eventlet thread阻塞。然而,这些方法没有一个比创建多个nova-api更管用。
-
替代原生的数据库驱动,例如_mysql.so。可以使用pure-python driver, 例如通过在nova.conf中设置
sql_connection=mysql+pymsql://....来使用pymysql,这个驱动eventlet将会通过使用monkeypatch来避免阻塞。这种方式相比使用原生的驱动,更加的消耗更多的CPU。因为pure-python driver是一个CPU密集型的驱动, eventlet thread 将花费更多的时间来于数据库交互,这导致我们前面提到的问题更严重。 -
代替从eventlet thread中发起数据库调用,可以提交数据库调用到eventlet pool的workers,然后等待结果。可以通过所设置
dbapi_use_tpool=True达到上述的目的。我发现的这个方法主要在workers threads之间同步的花销。特别的, worker thread 结束到等待协程恢复的时间开销往往比数据库调用的花费的时间还要多。
Use quantum for Security Groups, not nova-compute
尽管你在使用quantum来代替nova-network,而你可能还在使用nova-compute来处理firewall rules。
security groups的firewall rules可以通过nova,也可以通过quantum实现,二者皆可。使用Nova时,当一个新的虚拟机实例被创建,nova-compute将会序列的处理所有的security group工作和其他的实例创建工作,而对于quantum来说,会并行的处理security group与其他实例创建的工作。
配置nova使用quantum来代理防火墙更新的工作,可以在nova.conf配置:
[DEFAULT]
firewall_driver = nova.virt.firewall.NoopFirewallDriver
service_quantum_metadata_proxy = True
security_group_api = quantum
quantum_url = http://quantum_host:9696
quantum_admin_tenant_name = service
quantum_auth_strategy = keystone
quantum_admin_auth_url = http://keystone_host:35357/v2.0
quantum_admin_password = your_quantum_password
quantum_admin_username = you_quantum_username
network_api_class = nova.network.quantumv2.api.API
配置quantum更新防火墙,可以编辑/etc/quantum/plugins/openvswitch/ovs_quantum_plugin.ini文件:
quantum.agent.linux.iptables_firewall.OVSHybridIptablesFirewallDriver
Store Keystone Tokens Using memcached
创建虚拟机实例时,会触发多个api请求,例如:
- user to nova
- nova to glance to retrieve an image
- nova to quantum to create network ports and instantiate firewall rules.
- nova to cinder to attach volumes
每个API请求都包含了一个从keystone获取的授权token。当API Server接收到一个HTTP请求时,它需要在处理请求之前来通过keystone验证token 的有效性。
keystone检查token的有效性主要是通过执行 cryptographic算法和查询之前授权的token记录。显然,cryptographic是一个消耗cpu的计算,在就说明了检索token记录也是一个cpu耗时的过程。
那么,怎样配置keystone来存储授权的tokens了?典型的一个配置方法是使用数据库。不幸的是,在keystone的数据层这没有比较完美的实现细节。
- 过期的tokens不会从数据库中删除了。
- 在python中就被过滤了。
上面两条的原文是:
- expired tokens aren’t evicted from the database, and
- filter id done in python(i.e. no WHERE clause in the query)
token聚集时,这些细节将会导致keystone花费大量的cpu周期来过滤大量增长的tokens列表。
因为keystone是cpu稠密型的,并且仅有一个thread,在一些负载情况下,keystone无法跟上处理不停发过来的授权检查请求,将会导致限制openstack的性能。这有几个方法解决这个问题:
- 使keysthone的数据层更高效
- 增加keystone中cpu的并行度
- 使keysthone的client减少请求
可以通过使用memcached来代替数据存储tokens是数据层更加高效,具体操作可以参考这些步骤。memcached的实现似乎删除了过期的tokens。查询的实现似乎更加高效了。
增加CPU的并行需要打一些补丁,将在后文中讨论。
这儿有一些讨论来将少频繁的keystone请求。 我没有去实验这些patches,计划以后再尝试。
Disable rootwrap scripts
rootwrap scripts(nova-rootwrap, quantum-rootwrap等等)制定了OpenStack进程能够以root身份执行的命令,类似于一个细粒度的/etc/sudoers文件。 不幸的是, 这些rootwrap scripts对于他们包含的命令增加了大量的时间消耗, 例如, 在ip link例子中,导致超过 6倍的时间。
% time sudo ip link >/dev/null
sudo ip link > /dev/null 0.00s user 0.00s system 43% cpu 0.009 total
% sudo time quantum-rootwrap /etc/quantum/rootwrap.conf ip link > /dev/null
quantum-rootwrap /etc/quantum/rootwrap.conf ip link > /dev/null 0.04s user 0.02s system 87% cpu 0.059 total
这些消耗增加了OpenStack中触发这些命令的时间。而且,这些消耗导致了锁和CPU竞争。锁竞争是因为锁被更长时间的持有了而这是因为命令执行耗时更长了,(例如 global iptables lock), CPU竞争是因为在运行rootwrap scripts的几秒内,CPU核将达到100%的使用率。只要频繁的触发rootwrap,那么我们就需要管理好rootwrap’s的消耗。
可以使用sudo来代替rootwrap,通过设置root_helper=sudo来实现,在这些配置文件中你将看到root_helper:
/etc/nova/nova.conf
/etc/quantum/quantum.conf
/etc/quantum/l3_agent.ini
/etc/quantum/dhcp_agent.ini
/etc/quantum/metadata_agent.ini
/etc/quantum/plugins/openvswitch/ovs_quantum_plugin.ini
现在,确保你的sudoers file授权openstack用户足够的权限来执行这些命令。因为,sudoers有将近和rootwrap.conf一样的表达力,尽管存在一点语法的不同和很少的抽象惯用语,你同样可以确保sudoers授权仅必须的权限。当然,你还可以很懒的通过授权OpenStack用户carte blanche passwordless sudo privileges(全权委托无密码)。
nova ALL=(ALL) NOPASSWD: ALL
quantum ALL=(ALL) NOPASSWD: ALL
# etc.
Increase libvirt’s Concurrency Limits
几个参数限制了libvirtd能够并发处理请求的能力,这些参数中的大部分默认值都是20. 设置这些参数为N能够确保libvirtd能够迅速的处理请求。假如N=40,那么更新/etc/libvirt/libvirtd.conf文件,如下所示:
max_clients = 40
max_workers = 40
max_requests = 40
max_client_requests = 40
Upgrade to libvirt-1.0.3+
在1.0.3之前的版本中,libirt存在一个big lock导致请求服务的串行化。在1.0.3版本中,Daniel P.Berragnge 的一系列patches将这个巨大的锁变成了多个更加细粒度的锁了。
不幸的是, libvirt-1.0.3+ packages 只在还没有release的主流linux上有效(例如,Ubuntu 13.10, Ubuntu 12.04 Cloud Archives havana-proposed, Fedora 19),所以如果你不能使用最新版本的libvirt的话,最好自己独自编译源码。我使用了vanilla libvirt-1.0.4,我找到的ubuntu 补丁。
Disable control groups
在虚拟机实例创建的过程中,导致竞争的一个很关键的点就是在control group(cgroup) membership的锁。当libvirtd创建一个qemu process, 它将所有的线程添加到多个cgroups中。因为改变一个cgroups的membership是通过RCU 写临界区串行操作的, 添加一个线程到cgroup将会很慢。当并发的启动20个虚拟机时,我观察到每个虚拟机实例花费大约10s的时间将线程添加到cgroups中。
让libvirtd不使用cgroups可以避免这个问题。 据我所知, libvirtd使用cgroups来限制虚拟机的资源使用, prescribe NUMA placement, 和虚拟机的VCPU数据统计。因为OpenStack不使用任何任何libvirt依赖于cgroups的功能,让libvirtd不使用cgroups貌似没任何问题。然而,因为限制libvirtd不使用cgroups的唯一方法是在你的系统上禁止它,然而,禁止了cgroups将会影响其他程序来使用cgroups。
可以通过umount所有的cgroup mounts来禁止cgroup。在/proc/mounts中有详细的mounts points列表。 在Ubuntu系统上,可以运行sudo stop cgroup-lite来unmout标准的cgroups mount points.
Disable libvirt Security Drivers
Libvirt has hooks for security drivers to sandbox virtual machine execution, in particular by constraining the emulation of guest hardware. 例如,当创建一台虚拟机创建时,apparmor security driver将会加载新的profile到内核,这会仅仅允许访问/var/lib/nova/instances中的文件, 然后libivrt 创建执行运用了新的profile的qemu进程。
libvirt 通过一个global sercurity driver lock 来串行的调用security driver hooks。这个操作将会消耗几秒的时间,例如加载新的profile到内核,the serialization adds a non-trival amount of time to instance creation when many instances are being created in parallel. 在不久的以后,我计划提交一个patch来使用更加细粒度的锁来替代security driver lock。但在这个patch搞定之前,唯一的方法是将security drivers禁止,可以在/etc/libvirt/qemu.conf 中设置security_driver="none"。如果OpenStack配置了使用libvirt,并且qemu没啥bug,那么这个配置改变就是没啥问题的。
Techniques that Require Patches
下面用来改善OpenStack性能和并发度的技术需要对OpenStack打补丁。其中几个patches已经提交了或者已经被社区接受了。 我计划在Havana代码中提交一个重要的patches。
Run N nova-conductor workers
在Grizzly中,nova-conductor 唯一需要做的是访问数据库。 就像Nova-api,nova-conductor的请求高度序列化了,因为eventlet不能像_mysql.so打上monkey patch。为了解决这个问题,就像Nova-api一样,我们可以同时运行多个nova-conductor来达到我们期待的虚拟机创建并行化。 不幸的是, 不像nova-api的是, nova-conductor进程没有一个优雅的配置选项能够配置workers process的数量。所以,你需要将nova-conductor运行多次。还有一种方式,这有一个small patches来添加这个options, 用了这个patches之后,就可以在/etc/nova/nova.conf中通过设置workers=40来配置了。
当然,为了让nova-conductor process能够发挥效用,你需要使用conductor,这意味着你需要在/etc/nova/nova.conf中将use_local设置为false,如果设置成了True,那么nova-compute将会直接访问数据库。
需要注意的是,在OpenStack Havana版本中,conductor承担了更多的角色,包括管理migration tasks。然而,据我目前所知,多个nova-conductor进程仍然能够并行运行并且共享数据库的代理请求。可以在这看看社区关于conductor 扩展的讨论。
Run N keystone Processes
正如上面提到的, keystone是一个CPU密集的进程。 我们可以通过运行更多的keystone来保证并行性。keystone中的wsgi相关代码需要对fork后的accept()做出一些改变。对应的patches在此。用了这些patches之后,可以在/etc/keystone/keystone.conf中设置运行workers的数量。
Run N quantum-server Processes
像Nova-api, nova-conductor一样,quantum-server花费了很多时间访问数据库。同样,quantum-server在访问数据库上面,存在由于eventlet不能monkeypatch _mysql.so的问题,所以我们可以通过运行多个quantum-server的方式来解决此问题。可以参考这个patches
Reduce Libvirt Call Frequency
在创建虚拟机的过程中,nova-compute调用libvirt至少70次。依赖于你运行的libvirt版本和配置,这些libvirt的调用将消耗大量的时间。尽管大部分的libvirt串行化操作可以通过前面提到的升级和配置来减少,但是还是无法减少不必要的libvirt调用时间消耗。通过这个small patch可以将创建虚拟机实例过程libvirt的调用从70次减少到2次。
Coalesce Resource Manager Updates
计算节点有用的资源,例如总共可用的内存等等都是存储在nova数据库中的compute_node表中。Nova-scheduler则通过使用这些信息来做调度决策。当虚拟机分配的资源改变了(例如创建,删除),nova-compute就会更新表中的数据。
这个更新的过程就出现了性能问题; 更新的次数多(创建虚拟机时超过10次),更新过程缓慢并且串行化(nova-compute需要获取一个global resource management lock)。这个patch通过将这些需要多次更新信息打包起来加速更新过程。在我并行创建20台虚拟机的实验中,这个patch将每个虚拟机的rpc调用从10降低2次。
Make Quantum’s dnsmasq Callback Faster
Quantum-dhcp-agent 使用dnsmasq作为dhcp服务。 当一个dhcp租约创建或者删除时,quantum-dhcp-agent使用dnsmasq的 –dhcp-script flat来调用quantum-dhcp-agent-dnsmasq-lease-update, 使用这个script的结果是,Dnsmasq串行的调用这个脚本和一些DHCP处理。
不幸的是,quantum-dhcp-agent-dnsmasq-lease-update的过程较慢, 在我删除20台虚拟机的实验中,quantum-dhcp-agent-dnsmasq-lease-update还会运行1分钟左右的时间,并且CPU 核的利用率100%! 就像quantum-rootwrap, 这个script是用python写的,存在巨大的启动成本。不像quantum-rootwrap, 我们不能简单的通过减少调用频率来较少开销。 解决方法是,让这个脚本更加高效。
为了使这个脚本更加精巧,我重写了它,尽可能只import需要的packages。The new scripts功能和原始的一样,但是只有原始的运行时间的21%(i.e.: 运行两个脚本一百次的结果:3.609s vs 17.110s)。这是一个大的提升,但是通过删除40个虚拟机的产生持续的lease updates操作的过程中,当最后一个虚拟机被删除之后,这个脚本还要花费大约15s的时间。另外一个脚本实现更快,运行一百次耗时0.786s,c的实现,运行一百次是0.177s。但是,这不可能被社区接受。
Make Firewall Updates More Efficent
当存在很多虚拟机运行时,Grizzly 2013.1.2 quantum中的iptables firewall driver更新防火墙规则很慢。 这些缓慢的更新延迟了新创建的虚拟机实例访问dhcp server的请求。可以看这个bug #1194438。这个patch修复了这个bug。
Speed Up OVS Agent’s Periodic Updates
Quantum-openvswitch会周期性的像quantum-server报告所有ports的状态。在Grizzly 2013.1.2中,对于每个运行的虚拟机实例,大约耗费1s的时间来生成这些报告。因为quantum-server若接收到这些报告的频率低于5s每次的话,quantum-server可能会混乱。不需要太多的虚拟机实例就会使quantum-server混乱,可以参考这个bug # 1194438,这个patch将集成在2013.1.3中,已经解决了这个bug。
Backprot Race Condition Fixes
现在,OpenStack可以快多了,一些race condition bugs在OpenStack中出现的更频繁了,例如这两个bug,bug # 1180501 和bug #1194900。这些bug在havana中都已经解决了。如果你想运行更快的grizzly,那么可以打上这两个patch,patch for bug#1180501 和patch for bug#1194900。
评测
我做了所有的这些实验,测试的机器是牛逼猜到Ubuntu 12.04 server,12 cores, 2 hpyerthreads per core, 96GB RAM,另加一个固态盘。所有OpenStack服务都是运行在本地的。
Benchmark
测试的Benchmark是创建40个 m1.tiny(512MB RAM, 1core) 的Ubuntu Server 12.04 Clouding实例,ping, ssh这些虚拟机,然后删除他们,看整个过程花费的时间。测试过程将记录每个虚拟机在创建过程中每个阶段耗费的时间。虚拟机的创建过程从创建开始到openstack显示虚拟机实例的状态是ACTIVE结束(例如,qemu process存在到开始运行BIOS)。ping的过程是当虚拟机ACTIVE后立马开始ping,然后到虚拟机返回ping的响应。ssh阶段从ping阶段结束时开始,到虚拟机响应ssh结束。 一旦ssh响应了,那么就开始删除虚拟机,直到通过nova list看不到虚拟机为止。
这个benchmark是用来对OpenStack做压力测试的。 尽管ping和ssh阶段需要虚拟机做一些工作,任何延迟都会超过外界因素导致的几秒时间(Although the ping and the ssh phases require the guest to do some work, any delay greater than a couple of seconds is caused by external factors)。在ping的case中,虚拟机需要在OS启动并且init 脚本调用dhclient完成之后才会响应,如果OpenStack还没有使用DHCP Server给虚拟机配置ip地址,那么响应就不会发生。在ssh的case中,虚拟机需要cloudinit init scripts脚本完成设置ssh keys之后,才会响应。但是,直到OpenStack设置好NAT rules之后cloudinit才完成。
Results
首先是使用安装在Ubuntu 12.04上默认的OpenStack Grizzly的性能情况,测试图如下:

图中的两条线是通过atop命令收集到的数据,紫线是CPU的利用率,2s的取样期,蓝绿色的线是磁盘的利用率。颜色区域显示的benchmark中的每个阶段等待虚拟机实验响应的时间。需要注意的是,颜色区域的高度是通过除以每个阶段的虚拟机实例的个数来归一化了,就是每个阶段虚拟机的个数除以N。
从图中可以知道,第一个虚拟机创建仅仅花费了25s,而最后一个虚拟机创建花费了近200s。一旦,这个虚拟机创建了,立马响应了ping。然而,尽管网络栈已经设置好了,但是一些虚拟机实例花费了长达225s的时间来响应ssh操作。最终,一些虚拟机立马被删除了,而一些花费了将近50s才完成。
下面的这张图是显示使用了那些不需要打补丁的技术测试的结果:

重新配置主机,可以显著的降低虚拟机的创建时间。最大的创建时间和平均的创建时间都降低了大约50%。这些减少大多在于更新了libvirt,disabling groups 和 disabling libvirt security drivers。不幸的是,虚拟机花费在响应ssh上的时间大大增加了。 我怀疑是quantum-openvswitch-agent的周期性trash(可以参考这个bug)。在任何case下,给quantum打了补丁,那么这个现象就消失了。
运用上补丁之后,结果如下:
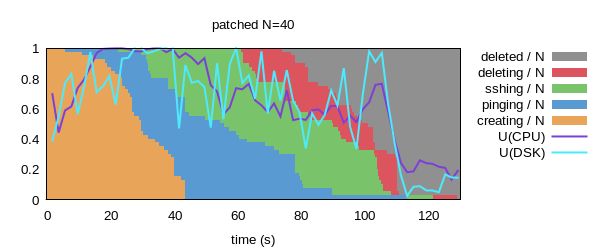
虚拟机创建时间已经大大的降低了,最大时间降到40s,平均时间降低到27s。这个减少是由于运行N个 nova-conductor和quantum-server提升了数据库访问的并发性。
需要注意的是,对比重新配置和原始的版本,ping的时间大大的增加了,而实际情况可能是没有的。因为网络创建和虚拟机创建已经大大并行化了, 我怀疑是qumu进程在dnsmasq得到更新和iptables rules添加之前就已经创建完成了。
整体上,在benchmark的结果中,时间消耗减少了74%。CPU和disk的利用率显著的提升了,这意味着我们较少了软件资源的竞争,增加了并行度。
Conclusions and Future Work
一些少量的配置和补丁显著的提升了OpenStack并发的效率。其中的几个patches已经被社区接受。余下的patches也是在等待被接收,因为很好的改善了性能而没有影响功能。
尽管已经减少了74%的时间,但是还是有很大的空间可以提升。如前面提到的,keystone的授权请求带到了大量的时间去处理请求。极少keystone的访问频率将会提升性能。另一个我没讨论的点是Rabbit MQ的性能。在我做的一些详细的性能分析中,我发现消息的延迟增减了N;因为大家都认为Rabbit在高负载下有较好的性能, 所以我怀疑可能是我使用rabbit mq的配置存在问题。最后,我意识到的一个显著的性能问题是, 大多数时间quantum’s iptables firewall driver对iptables的更新是串行化的并且完全多余。合并这些更新将是提升并发的一个很好方法。
我期待以后OpenStack serices越来越快。
如果错过了我的演讲,可以在这查看记录版本。
Feedback
可以在下面评论,email到 [email protected], 或者在openstack-dev mailing list讨论。
Acknowledgements
感谢Daniel P.Berrange帮助我找到libvirt配置问题和建议使用systemtap 工具来调试锁竞争问题。