centos6.5搭建hadoop完整教程
1,软件版本
Centos 6.5 jdk 1.8, hadoop 2.6
软件安装包地址:
https://pan.baidu.com/s/1eUm0n5o
密码:33a2
2.开始安装前的准备工作
2.1前情说明
由于一般hadoop的测试都是多台机器测试。在这里用三台虚拟机代替。具体的环境等其中一台搭好后(包括Vmtool的安装,hadoop的安装),后期利用Vmvare的克隆功能克隆出其他两台机器即可。
2.2Vmtool的安装(方便复制粘贴)
点击虚拟机左上角菜单栏虚拟机——>安装 Vmtools
点击之后,在Centos的桌面下会出现 VMwareTools...tar.gz 的文件。路径(/media/VMware Tools)
切记:当文件夹名称有空格时会出现问题,正确切换路径 cd / “VMware Tools”
2.将此文件复制到/tmp文件下进行解压
cp VMwareTools...gz /tmp
cd /tmp
tar -xzvf VMwareTools...gz
这时可能会出现解压后的目录。( vmware-tools-distrib目录)。然后执行安装操作
cd VMwareTools...
./vmware-install.pl
开始进行安装,一路回车就好了。。。
如果无法编译,可能权限不够。可以sudo ./vmware-install.pl 。如果执行过程中出现“...致命错误:Linux/smp_lock.h没有那个文件或目录,编译中断....”的错误,不用理会只管一路回车即可
2.3jdk安装(建议所有的安装先用root用户登录)
在目录 /opt 下创建software文件夹,将jdk的tar包放在此目录下,不止是jdk,或者是其他的tar包,安装包都建议放在这个新的目录里,目的是为了方便管理。
创建 soft文件夹的命令是 cd /opt mkdirsoftware 两条命令
其中在第一步安装的vmtool放在桌面上的jdk 的tar包应该copy到这个文件夹下来解压
放在桌面上的文件copy到指定目录的命令如下
如果登录用户是普通用户的话 桌面文件所在的位置是/home/用户名/Desktop
如果登录用户是root用户的话,那么桌面的文件所在的位置就是 /root/Desktop
知道了桌面文件的位置,接下来就要把文件copy到相应的位置了(以root为例)。
Copy 文件的命令是 cp /root/Desktop/jdk-linux-i586.tar.gz /opt/software
将jdk文件拷贝完之后,接下来就要解压jdk了
解压jdk tar包命令
tar –xzvf jdk-linux-i586.tar.gz
在/opt/software下创建javahome 文件夹, 然后将jdk解压之后的文件拷贝到此文件夹下。
配置环境变量(配置环境变量的文件 /etc/profile)
使用vi编辑器打开环境变量的配置文件 vi /etc/profile
在最后面加上下面的命令(具体的javahome的位置由环境而定)
#setjava environment
JAVA_HOME=/opt/software/javahome/jdk1.8.0_131
JRE_HOME=/opt/software/javahome/jdk1.8.0_131/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
exportJAVA_HOME JRE_HOME PATH CLASSPATH
保存退出
启用刷新配置 source /etc/profile
测试jdk是否安装成功。命令 java –version 如下显示了jdk的版本号就证明 jdk安装成功了。
[root@hserver1 ~]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) Client VM (build 25.131-b11, mixed mode)
2.4安装hadoop
安装hadoop的过程跟jdk安装差不多,在这里就不过多赘述了。我这的安装目录如下
/opt/software/hadoop 下为hadoop 解压之后的文件。
配置hadoop的环境变量 vi /etc/profile
在文件的最后边加上如下的命令
#set hadoop environment
export HADOOP_HOME=/opt/software/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
保存退出
配置刷新配置 source /etc/profile
验证hadoop是否配置成功如下所示 则说明hadoop配置成功了。
[root@hserver1 opt]# hadoop version
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -re3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /opt/software/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar
2.5使用VMware的克隆功能克隆两台一模一样的机器
具体方法点击Vmware左上角虚拟机---》管理———>克隆选第二项创建完整克隆即可。
3.hadoop具体配置
3.1修改主机名称
由于克隆出来的机器主机名都是一样的,故要修改主机名。
Centos 6.5修改主机名的方法有两种,一种是暂时修改主机名,二是永久修改(重启机器之后还有效)
暂时修改主机名:
命令1: hostname 查看主机名
命令2: hostname XXX 修改主机名为XXX
永久修改主机名:vi /etc/sysconfig/network 修改hostname为 XXX 保存退出 重启电脑即可
我这配置三台电脑的主机名称分别为 hserver1, hserver2, hserver3
3.2.配置ssh
一般安装的centos 都自带ssh功能 可以用如下命令检测是否安装了ssh
[root@hserver1 opt]# rpm -qa | grep ssh
openssh-askpass-5.3p1-94.el6.i686
openssh-clients-5.3p1-94.el6.i686
openssh-server-5.3p1-94.el6.i686
openssh-5.3p1-94.el6.i686
libssh2-1.4.2-1.el6.i686
如果没有ssh功能,需要先安装完此功能后才可进行下一步操作
以hserver1 为例,生成空字符串的秘钥(后面要使用公钥)
ssh-keygen -t rsa -P ''
直接按下一步即可生成
生成完成后 以登录用户root为例
在/root/.ssh 下会有生成的 id_rsa和 id_rsa.pub文件 其中id_rsa.pub保存的就是生成的公钥(公钥格式内容
ssh-rsaAAAAB3NzaC1yc2EAAAABIwAAAQEAqcRuWHCgMGk9CyJsPTR2YH6qvp/yPPLQ7sB08jQ8TaJBt/rI6JS/hCoOTbPxSJYlvMX9cR0VffsCB+G2LSpJJq/XtZoQwzWj8B5FXmPXlIbrNkKi+jElfgGZ0CLokdJ84A/PuDRHBhhmDwREcIkmpXg6vwKYxbqvamRXVmQcFS8szJSRhEH3QP9f9miZZ8kFtOrSGvMwB92L1o1VNea5L6cnD7LEu3eafsc9f5VLDl4tf/vLWCH39n18yqMm6Oi5LMQAh0mwMF+RrtrFWZHEJ66SCWxlD2HQo+nkHlxiP5jn/qvqguR5SC1bSNLHbVrJl9ci1XZ7G5wkHs+vHSeM4w==root@hserver1 )
[root@hserver1~]# cd /root/.ssh
[[email protected]]# ls -a
. .. authorized_keys id_rsa id_rsa.pub known_hosts
同理分别生成hserver2和hserver3 的公钥
待三台机器的公钥都生成完毕之后 分别在hserver1,hserver2,hserver3的/root/.ssh目录下创建authorized_keys 创建文件的命令是 touch /root/.ssh/authorized_keys
以hserver1为例,将hserver1,hserver2,hserver3的机器上id_rsa的内容复制到 新建的authorized_keys里,hserver2,hserver3 同理。
附上 authorized_keys文件内容格式:
ssh-rsaAAAAB3NzaC1yc2EAAAABIwAAAQEAqcRuWHCgMGk9CyJsPTR2YH6qvp/yPPLQ7sB08jQ8TaJBt/rI6JS/hCoOTbPxSJYlvMX9cR0VffsCB+G2LSpJJq/XtZoQwzWj8B5FXmPXlIbrNkKi+jElfgGZ0CLokdJ84A/PuDRHBhhmDwREcIkmpXg6vwKYxbqvamRXVmQcFS8szJSRhEH3QP9f9miZZ8kFtOrSGvMwB92L1o1VNea5L6cnD7LEu3eafsc9f5VLDl4tf/vLWCH39n18yqMm6Oi5LMQAh0mwMF+RrtrFWZHEJ66SCWxlD2HQo+nkHlxiP5jn/qvqguR5SC1bSNLHbVrJl9ci1XZ7G5wkHs+vHSeM4w==root@hserver1
ssh-rsaAAAAB3NzaC1yc2EAAAABIwAAAQEAxe+joUhPZdw6VhVPlPPwjYZHGkrYeDb+YiPyjv76MsbWi86uFnH4YjQypVh9VGe67LfXNdVeRQ8MX1mCRrr8jj+4PyGoELckxr1ldPheU/Hyy0guHbULzz5kujRicg2WiuIX8dKpKk18usCcS9LWTilRlu/lNNnbeOt0IQbOZcoiAOoGrLK9cN7MilTUaoHGEVIN/yvHsFj4ppejpXk+GIfQy50OBq9C4nGsCcCFf38EttEhxYsfzpABKgN4d0hua5eJ1MHhQoNaV0HOt+vgoFQZcWF0JSXc/CedXkLd5bb3w4gzC5NRexBpdXLvqqRE5lqZp/s9UXi5ZT82qw88vQ==root@hserver2
ssh-rsaAAAAB3NzaC1yc2EAAAABIwAAAQEAzQUKWuKKVZLBCVZFyU2nWZJnheuYJ8AegzDNmbMW41mB5YppXMEeWKS991kYDOVWtp/R3kG+hlmSieYf5PRlg1ByNtPUywAwT56idQ+SXzgAKA/UwI2DBtf7oetAE3EzbrGXlgcO7xASiJ6I6pojedvzyBAkq1JJTFHk9ZF4cwof4t7uVo+dTkc7BaWjbVIkTlZtN/vj8egXEhVmrTa7ynOOdnhHUtS6ezT6LipDHaRA1MT21/FGDdKH+6LrFSgwf4texzpHX0FfOjWxCeOS+Dp8qWppWOb6BRHoijuKy0akOvQlh9z3TQcck8ip5kO3Rp602cuiC+ODyo4Z3pQ2Yw==root@hserver3
3.3修改hosts文件(使hserver1和hserver2,hserver3相互通信)
打开hosts文件 vi /etc/hosts
将如下内容添加文件最后面(172.22.41.48 代表hserver1对应的ip,其他同理)查看ip方法输入 ifconfig即可
172.22.41.48hserver1
172.22.41.47hserver2
172.22.41.55hserver3
同理将hserver2和hserver3的hosts内容也加上上边的内容。
最后测试ssh登录功能在hserver1上输入 ssh hserver2 验证登录。
3.4配置hadoop具体文件
在配置之前,得先建立几个目录,这些目录在后续的配置里会用得着。
1. mkdir /root/hadoop
2. mkdir /root/hadoop/tmp
3. mkdir /root/hadoop/var
4. mkdir /root/hadoop/dfs
5. mkdir /root/hadoop/dfs/name
6. mkdir /root/hadoop/dfs/data
接下来就是修改etc/hadoop 目录下的各个文件了, etc/hadoop 全路径在我这是 /opt/software/hadoop/etc/hadoop
它的目录如下
[root@hserver1hadoop]# ls -a
. hdfs-site.xml mapred-env.sh
.. httpfs-env.sh mapred-queues.xml.template
capacity-scheduler.xml httpfs-log4j.properties mapred-site.xml
configuration.xsl httpfs-signature.secret mapred-site.xml.template
container-executor.cfg httpfs-site.xml slaves
core-site.xml kms-acls.xml ssl-client.xml.example
hadoop-env.cmd kms-env.sh ssl-server.xml.example
hadoop-env.sh kms-log4j.properties yarn-env.cmd
hadoop-metrics2.properties kms-site.xml yarn-env.sh
hadoop-metrics.properties log4j.properties yarn-site.xml
hadoop-policy.xml mapred-env.cmd
3.4.1修改core-site.xml (以hserver1为例,其他两台机器同理,配置不用变)
在
<property>
<name>hadoop.tmp.dirname>
<value>/root/hadoop/tmpvalue>
<description>Abasefor other temporary directories.description>
property>
<property>
<name>fs.default.namename>
<value>hdfs://hserver1:9000value>
property>
configuration>
3.4.2修改hadoop-env.sh(以hserver1为例,其他两台机器同理,配置不用变)
将export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/opt/software/javahome/jdk1.8.0_121
说明:修改为自己的JDK路径
3.4.3修改hdfs-site.xml(以hserver1为例,其他两台机器同理,配置不用变)
在
<property>
<name>dfs.name.dirname>
<value>/root/hadoop/dfs/namevalue>
<description>Pathon the local filesystem where theNameNode stores the namespace and transactionslogs persistently.description>
property>
<property>
<name>dfs.data.dirname>
<value>/root/hadoop/dfs/datavalue>
<description>Commaseparated list of paths on the localfilesystem of a DataNode where it shouldstore its blocks.description>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
说明:dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true。
3.4.4 新建并且修改mapred-site.xml(以hserver1为例,其他两台机器同理,配置不用变)
hadoop在该版本中,有一个名为mapred-site.xml.template的文件,复制该文件,然后命名
mapred-site.xml 复制命令是 cp mapred-site.xml.template mapred-site.xml
然后修改mapred-site.xml在
<property>
<name>mapred.job.trackername>
<value>hserver1:49001value>
property>
<property>
<name>mapred.local.dirname>
<value>/root/hadoop/varvalue>
property>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
3.4.5修改slaves文件(hserver1为例,其他两台机器同理,配置不用变)
将slaves文件中的内容将文件中的localhost去掉
替换为hserver2 hserver3 如下所示
[root@hserver1 hadoop]# cat slaves
hserver2
hserver3
3.4.6修改yarn-site.xml(hserver1为例,其他两台机器同理,配置不用变)
在
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hserver1value>
property>
<property>
<description>The address of the applications managerinterface in the RM.description>
<name>yarn.resourcemanager.addressname>
<value>${yarn.resourcemanager.hostname}:8032value>
property>
<property>
<description>The address of the scheduler interface.description>
<name>yarn.resourcemanager.scheduler.addressname>
<value>${yarn.resourcemanager.hostname}:8030value>
property>
<property>
<description>The http address of the RM webapplication.description>
<name>yarn.resourcemanager.webapp.addressname>
<value>${yarn.resourcemanager.hostname}:8088value>
property>
<property>
<description>The https adddress of the RM webapplication.description>
<name>yarn.resourcemanager.webapp.https.addressname>
<value>${yarn.resourcemanager.hostname}:8090value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>${yarn.resourcemanager.hostname}:8031value>
property>
<property>
<description>The address of the RM admin interface.description>
<name>yarn.resourcemanager.admin.addressname>
<value>${yarn.resourcemanager.hostname}:8033value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>2048value>
<discription>每个节点可用内存,单位MB,默认8182MBdiscription>
property>
<property>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>2.1value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
说明:yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
3.5各项配置,各个机器完成配置后即可测试
3.5.1启动hadoop
在master机器上进行格式化node操作(此项操作一般在搭建后只执行一次,多次执行此操作,可能会使datanode无法启动)
具体格式化命令 进入 cd/opt/software/hadoop/bin
执行 ./hadoop namenode -format 点击y 按要求执行即可
启动命令:
进入 cd /opt/software/hadoop/sbin
执行 ./start-all.sh
3.5.2验证hadoop是否启动成功
浏览器验证 端口50070验证(datanode个数2)

浏览器验证 8088
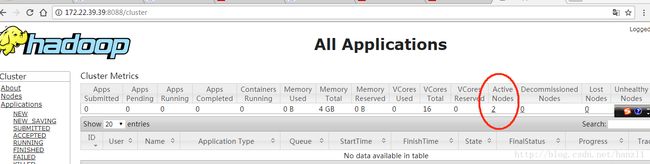
命令验证 hserver1即master机器
输入Jps显示
[root@hserver1 sbin]# jps
4608 ResourceManager
4289 NameNode
4866 Jps
4468 SecondaryNameNode
Hserver2 输入jps显示
[root@hserver2 ~]# jps
3264 DataNode
3367 NodeManager
3518 Jps
Hserver3 输入jps显示
[root@hserver3 ~]# jps
3365 NodeManager
3294 DataNode
3535 Jps
以上就是正常启动hadoop的效果
3.6配置完后多次格式化造成datanaode 启动不了的问题
解决方式先关闭hadoop 然后在从节点那(hserver2,hserver3)在目录 /root/hadoop/dfs/data 中的文件current清空。
重新启动hadoop即可。
本文主要在
博客地址http://blog.csdn.net/pucao_cug/article/details/71698903的文章的指导下完成。