hadoop namenode HA 高可用概念及配置说明
完全分布式
可以看到之前配置的完全分布式中只有一个nn节点,不能高可用。
在1x版本中存在这些问题:
hdfs:nn单点故障,压力过大,内存受限,扩展受阻。
MapReduce(MR):jboTracker访问压力大,扩展受阻;难以支持MR以外的计算框架,如spark,storm等。
##1.HA 高可用
hdfs ha :主备切换方式解决单点故障
hdfs Federation联邦:解决鸭梨过大。支持水平扩展,每个nn分管一部分目录,所有nn共享dn资源。
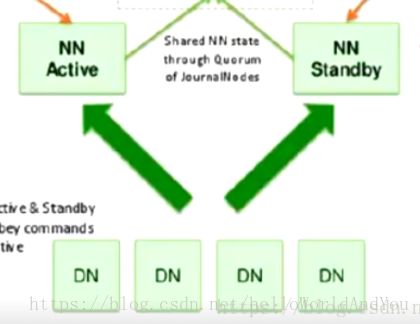
上图,NN实现高可用,nn副本数据得和nn主节点保持一致。
dn可以同时向两个NN汇报数据存储情况。而客户端则只能访问nn主节点,数据的一致性就需要nn主节点向nn副本同步数据了。存在常见的问题:强一致性,若一致性。
强一致性:nn主节点必须等到nn副本返回成功后,才能向客户端返回成功。主和副本之间可能会有如网络延迟、阻塞等问题,就造成了nn的不可用,违背了HA初衷。
弱一致性:采用异步方式,nn主无需等待nn副本返回成功,则会有nn副本数据同步失败,造成两个nn数据不一致。
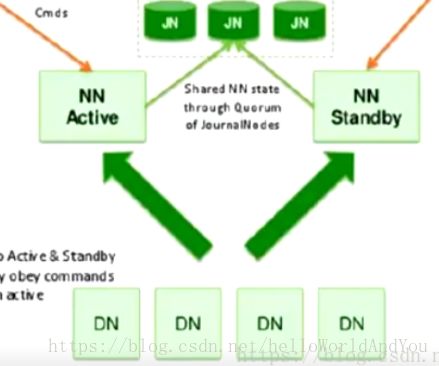
上图,加入nfs系统,如图中的jn集群。当Active节点执行任何名称空间修改时,它会将修改记录持久地记录到大多数这些JN中。待机节点能够从JN读取编辑,并且不断观察它们对编辑日志的更改。当备用节点看到编辑时,它会将它们应用到自己的命名空间。这可确保在发生故障转移之前完全同步命名空间状态,保证两个nn数据最终的一致性。
这里nn主节点挂掉后,nn副本不能自动升级为主节点,还需人为干涉。
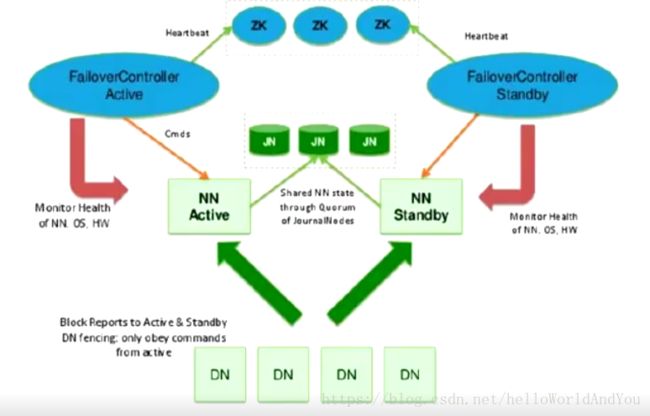
上图,加入zookeper集群,当nn主节点挂掉,通过zk自动将nn副本升级为主节点。
为了提供快速故障转移,备用节点还必须具有关于群集中块的位置的最新信息。为了实现这一点,DataNode配置了所有NameNode的位置,并向NN发送块位置信息和心跳
1)如何确定哪个nn是主节点
图中还新增了一个zkfc角色,是一个jvm进程,用于监控nn状态。当nn启动后,zkfc检测到各自nn都已启动正常运行后,zkfc向zk发送创建锁(创建在某个节点上)的消息,谁的锁创建成功,则对应的nn标识为主节点,其它的zkfc则会对该节点进行watch,即监控,并注册回调方法。
2)nn主节点挂掉后,nn副本如何升级为主节点
当nn主节点挂掉后,对应的zkfc检测到nn状态,向zk发送删除锁的消息,锁删除成功后,则触发一个事件,该事件回调副本对应的zkfc,zkfc得到消息后先取zk争夺创建锁,完成后检测nn主节点是否挂掉,挂掉则升级副本为主节点,没挂掉则将主节点降级为副本,将自己对应的nn升级为主节点。
3)主节点zkfc挂掉,主节点没挂
zkfc在zk创建的锁属于临时节点,该节点属于对应的回话session。
zkfc挂掉,zkfc和zk之间tcp链接会随之断开,session随之消失,锁被删除,触发一个事件回调副本的zkfc,zkfc得到消息后先取zk争夺创建锁,完成后检测nn主节点是否挂掉,挂掉则升级副本为主节点,没挂掉则将主节点降级为副本,将自己对应的nn升级为主节点。
##2. hdfs Federation 联邦
通过多个namenode/namespace把元数据的存储和管理分散到多个节点,以使能通过增加服务器进行水平扩展。
将单个nn的负载分散到多个节点中,保证了对大规模数据的处理能力。通过多个namespace隔离不同类型的应用,将不同类型应用的hdfs元数据的存储和管理分派到不同的namenode中。
HA with QJM搭建
###Configuration details
配置的先后顺序不重要,但其中某些配置之间存在依耐。例如:
dfs.ha.namenodes.[nameservice ID] 依耐 dfs.nameservices 即如果dfs.nameservices配置value为a那么dfs.ha.namenodes.[nameservice ID]则写成dfs.ha.namenodes.a
####hdfs-site.xml
- dfs.nameservices
hdfs-site.xml名称可自定义,建议取个合理的名字。该配置影响到其它配置,也会影响到hdfs文件系统存储的绝对路径。
如果您还在使用HDFS Federation,则此配置设置还应包括其他名称服务列表,HA或其他,用逗号作为分隔列表。
dfs.nameservices
mycluster
- dfs.ha.namenodes.[nameservice ID]
让dn确定集群中有多少个nn。nn至少两个,推荐3个,不建议超过5个。
dfs.ha.namenodes.mycluster
nn1,nn2, nn3
- dfs.namenode.rpc-address.[nameservice ID].[name node ID]
侦听的每个NameNode的完全限定的RPC地址。
dfs.namenode.rpc-address.mycluster.nn1
machine1.example.com:8020
dfs.namenode.rpc-address.mycluster.nn2
machine2.example.com:8020
dfs.namenode.rpc-address.mycluster.nn3
machine3.example.com:8020
- dfs.namenode.http-address.[nameservice ID].[name node ID]
侦听的每个NameNode的完全限定HTTP地址。
注意:如果启用了Hadoop的安全功能,则还应为每个NameNode设置https-address。
dfs.namenode.http-address.mycluster.nn1
machine1.example.com:9870
dfs.namenode.http-address.mycluster.nn2
machine2.example.com:9870
dfs.namenode.http-address.mycluster.nn3
machine3.example.com:9870
- dfs.namenode.shared.edits.dir
配置JournalNodes (jn)地址。如果是管理脚本,则会根据改地址启动jn,如果是active nn,则会通过该地址传输命名空间变更信息。备用的nn则会通过该配置地址拉取变更数据。配置值最后的/mycluster作为存储的根路径,多个HA可公用服务器进行数据存储,节约服务器成本。因此每个HA服务的根路径不能一样,便于区分。
dfs.namenode.shared.edits.dir
qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster
- dfs.journalnode.edits.dir
这是JournalNode本地存储绝对路径。
dfs.journalnode.edits.dir
/path/to/journal/node/local/data
- dfs.client.failover.proxy.provider.[nameservice ID]
便于客户端确定哪个nn是主节点。对于第一次调用,它同时调用所有名称节点以确定活动的名称节点,之后便直接调用主节点(active nn )
ConfiguredFailoverProxyProvider 和RequestHedgingProxyProvider 选其一即可。
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
- dfs.ha.fencing.methods
当发生故障转移时,以前的Active NameNode仍可能向客户端提供读取请求,这可能已过期,直到NameNode在尝试写入JournalNode时关闭。因此,即使使用Quorum Journal Manager,仍然需要配置一些防护方法。但是,为了在防护机制失败的情况下提高系统的可用性,建议配置防护方法,能确保不会发生此类情况。请注意,如果您选择不使用实际的防护方法,则仍必须为此设置配置某些内容,例如“shell(/ bin / true)”。 故障转移期间使用的防护方法配置为回车分隔列表,将按顺序尝试,直到指示防护成功为止。 Hadoop有两种方法:shell和sshfence。有关实现自定义防护方法的信息,请参阅org.apache.hadoop.ha.NodeFencer类。
0.1) sshfence
sshfence选项通过SSH连接到目标节点,并使用fuser来终止侦听服务TCP端口的进程。为了使此防护选项起作用,它必须能够在不提供密码的情况下SSH到目标节点。因此,还必须配置dfs.ha.fencing.ssh.private-key-files选项,该选项是以逗号分隔的SSH私钥文件列表。
如果使用ssh免密的方式,那么两个nn需要互相免密登陆,因为涉及到zkfc需要登陆另一台nn将其降序的操作。
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/exampleuser/.ssh/id_rsa
可选项,可以配置非标准用户名或端口以执行SSH。也可以为SSH配置超时(以毫秒为单位),之后将认为此防护方法已失败。
dfs.ha.fencing.methods
sshfence([[username][:port]])
dfs.ha.fencing.ssh.connect-timeout
30000
0.2) shell
通过脚本终止active nn
dfs.ha.fencing.methods
shell(/path/to/my/script.sh arg1 arg2 ...)
core-site.xml
- fs.defaultFS
配置和nameservice ID值一样。将通过mycluster结合hdfs配置中的dfs.nameservices和dfs.ha.namenodes.mycluster找到该服务下的所有nn,确认主节点。
fs.defaultFS
hdfs://mycluster