基于tensorflow 使用seq2seq+attention+beansearch搭建一个聊天机器人教程(附github源码)
版权声明:博主原创文章,转载请注明来源,谢谢合作!!
https://blog.csdn.net/hl791026701/article/details/84404901
这篇博文主要是介绍基于tensorflow使用google的seq2seq模型来构建一个聊天机器人,主要是学习一下encoder、decoder、attention、bean search等原理和实现方式。
seq2seq是一种很常见的技术。例如,在法语-英语翻译中,预测的当前英语单词不仅取决于所有前面的已翻译的英语单词,还取决于原始的法语输入;另一个例子,对话中当前的response不仅取决于以往的response,还取决于消息的输入。其实,seq2seq最早被用于机器翻译,后来成功扩展到多种自然语言生成任务,如文本摘要和图像标题的生成。本文将介绍几种常见的seq2seq的模型原理,seq2seq的变形以及seq2seq用到的一些小trick。
—、 seq2seq模型简介

seq2seq属于encoder-decoder结构的一种,这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,如上图,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。而decoder则负责根据语义向量生成指定的序列,这个过程也称为解码,如下图,最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的rnn中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。
encoder-decoder模型对输入和输出序列的长度没有要求,应用场景也更加广泛。
详情可以参考:seq2seq模型详解
二、数据文本处理
- 构建模型的第一步是进行语料的获取和处理。
这次我们使用的中文电视剧对白语料 https://github.com/fateleak/dgk_lost_conv。
另外博主还搜集了其它市面上已有的开源中文聊天语料并系统化整理工作
wget https://lvzhe.oss-cn-beijing.aliyuncs.com/dgk_shooter_min.conv.zip
下载预料后要用unzip dgk_shooter_min.conv.zip进行解压。输出dgk_shooter_min.conv
我们可以看下原始语料格式

2. 我们要对语料进行简单的清洗处理,然后根据根据’“ / ”进行split得到一个个字。
for line in tqdm(fp):
if line.startswith('M '):
line = line.replace('\n','')
if '/' in line:
line = line[2:].split('/')
else:
line = list(line[2:])
line = line[:-1] #
group.append(list(regular(''.join(line))))
else:
lsat_line=None
if group:
groups.append(group)
group=[]
- 处理完之后我们要自己构造Q、A问答句。从上面语料我们可以看出每段会话由标识符“E”分割,所以我们根据(a1,a2),(a1+a2,a3) ,(a1,a2+a3)这样的组合来构造问答语句:
#假设 a1,a2,a3,三句话 (a1,a2),(a1+a2,a3) ,(a1,a2+a3)
if next_line:
x_data.append(line)
y_data.append(next_line)
if last_line and next_line:
x_data.append(last_line + make_split(last_line) + line)
y_data.append(next_line)
if next_line and next_next_line:
x_data.append(line)
y_data.append(next_line + make_split(next_line) + next_next_line)
构建好输入X、Y即输入的问答后 ,接下来我们要进行序列化处理。
ws_input = WordSequence()
ws_input.fit(x_data + y_data)
- 构建了一个word_sequence类:主要函数的作用分别是创建字典、句子转向量、词向量映射、根据超参定制化训练数据、基础数据标记、初始化词典。
4.1 每个句子特殊处理
(1)在训练过程中,每个batch中句子长度不一样,此时对于短句子用填充
(2)用于句子结尾,告诉decoder停止预测
(3)不在字典中的词用替换
(4) decoder第一个输入,告诉decoder预测开始
def fit(self,sentences,min_count=5,max_count=None,max_features=None):
"""
Args:
min_count 最小出现次数
max_count 最大出现次数
max_features 最大特征数
"""
assert not self.fited , 'WordSequence 只能 fit 一次'
count={}
for sentence in sentences:
arr=list(sentence)
for a in arr:
if a not in count:
count[a]=0
count[a]+=1
print(count)
if min_count is not None:
count={k : v for k,v in count.items() if v >= min_count}
if max_count is not None:
count={k : v for k,v in count.items() if v<=max_features}
self.word_dict = {
WordSequence.PAD_TAG:WordSequence.PAD,
WordSequence.UNK_TAG:WordSequence.UNK,
WordSequence.START_TAG:WordSequence.START,
WordSequence.END_TAG:WordSequence.END
}
if isinstance(max_features,int):
count = sorted(list(count.items()),key=lambda x:x[1]) #对value排序 升序 返回list元组
if max_features is not None and len(count) > max_features:
count = count[-int(max_features):]
for w,_ in count:
self.word_dict[w] = len(self.word_dict) #构建{word:index}
else:
for w in sorted(count.keys()): #按照key排序,返回keylist
self.word_dict[w]=len(self.word_dict)
self.fited=True
#采用预训练好的部分词向量
embeddings_index={}
print("正在加载预训练词向量……")
with open(self.word_vec_dic, 'rb') as f:
for line in f:
values = line.decode('utf-8').split(' ')
word = values[0]
embedding=values[1:301]
embeddings_index[word]=embedding
print("预训练词向量加载完毕。")
nb_words = len(self.word_dict)
self.word_embedding_matrix=np.zeros((nb_words,self.embedding_dim),dtype=np.float32)
for word,i in self.word_dict.items():
if word in embeddings_index:
self.word_embedding_matrix[i] = embeddings_index[word]
else:
new_embedding = np.array(np.random.uniform(-1,1,self.embedding_dim))
embeddings_index[word] = new_embedding
self.word_embedding_matrix[i] = embeddings_index[word]
print('词向量映射完成')
以上就是把文本转换成对应的索引,
[‘你’, ‘好’, ‘啊’] ——>[6, 56, 34]
[‘嗯’, ‘你’, ‘好’]——>[67, 6, 56]
最后把输入语料全部fit一遍用转换成对应的索引,pickle.dump进行序列化保存
ws_input = WordSequence()
ws_input.fit(x_data + y_data)
print('dump')
#序列化保存
pickle.dump(
(x_data,y_data),
open('./data/chatbot.pkl','wb')
)
pickle.dump(ws_input,open('./data/ws.pkl','wb'))
print('done')
三、模型构建
构建seq2seq模型我们大体上按照如下方式进行:
- 初始化训练,预测所需要的变量
- 构建编码器(encoder) build_signal_cell -> encoder_cell -> build_encoder
- seq2seq :用seq2seq模型把Encoder 和decoder联系起来
- 构建解码器(decoder) build_decoder_cell -> build_decoder
- 构建优化器(optimizer)
- 保存模型(save)
整体框架:
def build_model(self):
"""
1. 初始化训练, 预测所需要的变量
2. 构建编码器(encoder) build_encoder -> encoder_cell -> build_signal_cell
3. 构建解码器(decoder) build_decoder -> decoder_cell -> build_signal_cell
4. 构建优化器(optimizer)
5. 保存
"""
self.init_placeholders()
encoder_outputs, encoder_state = self.build_encoder()
self.build_decoder(encoder_outputs, encoder_state)
if self.mode == 'train':
self.init_optimizer()
self.saver = tf.train.Saver()
- 初始化主要是设置输入、输出词表大小,其实就是分完字之后整个语料库的大小,因为问答使用相同的语料所以他们的大小是一样的,如果是机器翻译的话大小就不一样了要另做处理。batch_size可以根据你的GPU显存来设置大小博主使用的Tesla P100 16g显存比较壕设置128,如果是10g左右的显存 建议64就行了。接下来rnn单元我们选的是LSTM,实际上GRU和LSTM在性能上不分伯仲,GRU参数更好更容易收敛罢了,但在大数据集情况下,LSTM表达性能更好。hidden_units为RNN单元Cell中隐藏神经元的数量,depth为RNN层数,同样神经元个数越多,层数越深,训练时间越长,效果越好,但是同样要注意GPU显存问题。还有一些参数就不一一介绍了,使用的时候我们在细细详谈。
def __init__(self, #
input_vocab_size, #输入词表的大小
target_vocab_size, #输出词表的大小
batch_size=32, #数据batch的大小
embedding_size=300, #输入词表与输出词表embedding的维度
mode="train", #取值为train, 代表训练模式, 取值为decide,代表预训练模式
hidden_units=256, #Rnn模型的中间层大小,encoder和decoder层相同
depth=1, #encoder和decoder的rnn层数
beam_width=0, #是beamsearch的超参数,用于解码
cell_type="lstm", #rnn的神经元类型, lstm, gru
dropout=0.2, #随机丢弃数据的比例,是要0到1之间
use_dropout=False, #是否使用dropout
use_residual=False, #是否使用residual
optimizer='adam', #使用哪一个优化器
learning_rate=1e-3, #学习率
min_learning_rate=1e-5, #最小学习率
decay_steps=50000, #衰减步数
max_gradient_norm=5.0, #梯度正则裁剪的系数
max_decode_step=None, #最大decode长度, 可以非常大
attention_type='Bahdanau', #使用attention类型
bidirectional=False, #是否使用双向encoder
time_major=False, #是否在计算过程中使用时间作为主要的批量数据
seed=0, #一些层间的操作的随机数
parallel_iterations=None, #并行执行rnn循环的个数
share_embedding=False, #是否让encoder和decoder共用一个embedding
pretrained_embedding=False): #是不是要使用预训练的embedding
self.input_vocab_size = input_vocab_size
self.target_vocab_size = target_vocab_size
self.batch_size = batch_size
self.embedding_size = embedding_size
self.hidden_units = hidden_units
self.depth = depth
self.cell_type = cell_type.lower()
self.use_dropout = use_dropout
self.use_residual = use_residual
self.attention_type = attention_type
self.mode = mode
self.optimizer = optimizer
self.learning_rate = learning_rate
self.min_learning_rate = min_learning_rate
self.decay_steps = decay_steps
self.max_gradient_norm = max_gradient_norm
self.keep_prob = 1.0 -dropout
self.seed = seed
self.pretrained_embedding = pretrained_embedding
self.bidirectional = bidirectional
if isinstance(parallel_iterations, int):
self.parallel_iterations= parallel_iterations
else:
self.parallel_iterations = batch_size
self.time_major = time_major
self.share_embedding = share_embedding
#生成均匀分布的随机数 用于变量初始化
self.initializer = tf.random_uniform_initializer(
-0.05, 0.05, dtype=tf.float32
)
assert self.cell_type in ('gru', 'lstm'), 'cell_type 应该是GRU 或者是 LSTM'
if share_embedding:
assert input_vocab_size == target_vocab_size, '如果share_embedding 为True 那么两个vocab_size 必须一样'
assert mode in ('train', 'decode'), 'mode 必须是train 或者是decode , 而不是{}'.format(mode)
assert dropout >=0.0 and dropout< 1.0, 'dropout 必须大于等于0 且小于等于1'
assert attention_type.lower() in ('bahdanau', 'loung'), 'attention_type 必须是bahdanau 或者是 loung'
assert beam_width < target_vocab_size, 'beam_width {} 应该小于target_vocab_size{}'.format(beam_width,target_vocab_size)
self.keep_prob_placeholder = tf.placeholder(
tf.float32,
shape=[],
name='keep_prob'
)
self.global_step = tf.Variable(
0, trainable = False, name = 'global_step'
)
self.use_beamsearch_decode = False
self.beam_width = beam_width
self.use_beamsearch_decode = True if self.beam_width > 0 else False
self.max_decode_step = max_decode_step
assert self.optimizer.lower() in ('adadelta', 'adam', 'rmsprop', 'momentum', 'sgd'), \
'optimizer 必须是下列之一: adadelta, adam, rmsprop, momentum, sgd '
self.build_model()
- 接下来要定义inputs和targets 的tf占位符。
def init_placeholders(self):
"""初始化训练,初始化所需要的变量 """
self.add_loss = tf.placeholder(
dtype=tf.float32,
name='add_loss'
)
#编码器的输入
# 编码器输入,shape=(batch_size, time_step)
# 有 batch_size 句话,每句话是最大长度为 time_step 的 index 表示
self.encoder_inputs = tf.placeholder(
dtype=tf.int32,
shape=(self.batch_size,None),
name='encoder_inputs'
)
#编码器的长度输入
# 编码器长度输入,shape=(batch_size, 1)
# 指的是 batch_size 句话每句话的长度
self.encoder_inputs_length = tf.placeholder(
dtype = tf.int32,
shape=(self.batch_size, ),
name = 'encoder_inputs_length'
)
if self.mode =='train':
#解码器的输入
# 解码器输入,shape=(batch_size, time_step)
# 注意,会默认里面已经在每句结尾包含
self.decoder_inputs = tf.placeholder(
dtype = tf.int32,
shape=(self.batch_size, None),
name = 'decoder_inputs'
)
#解码器输入的rewards 用于强化学习训练,shape=(batch_size, time_step)
self.rewards = tf.placeholder(
dtype = tf.float32,
shape=(self.batch_size, 1),
name='rewards'
)
#解码器的长度输入
self.decoder_inputs_length = tf.placeholder(
dtype = tf.int32,
shape=(self.batch_size,),
name ='decoder_inputs_length'
)
self.decoder_start_token = tf.ones(
shape=(self.batch_size, 1),
dtype=tf.int32
) * WordSequence.START
#实际训练时解码器的输入, start_token + decoder_inputs
self.decoder_inputs_train = tf.concat([
self.decoder_start_token,
self.decoder_inputs
],axis=1)
接下构建encoder。首先要用tf的LSTMCell构建rnn单元,n_hidden来设置LSTM神经元个数,ResidualWrapper残差网络用来解决在深度网络中发生梯度弥散/爆炸,导致无法收敛问题。在tensorflow使用方法和其他的Wrapper都是一样的。把构建好的单个LSTM实例传入到MultiRNNCell类就可以实现多层Deep RNN了。
def build_signle_cell(self, n_hidden, use_residual):
"""
构建一个单独的 RNNCell
n_hidden : 隐藏层的神经元数量
use_residiual : 是否使用residual wrapper
"""
if self.cell_type == 'gru':
cell_type = GRUCell
else:
cell_type = LSTMCell
cell = cell_type(n_hidden)
if self.use_dropout:
cell = DropoutWrapper(
cell,
dtype = tf.float32,
output_keep_prob = self.keep_prob_placeholder,
seed = self.seed
)
if use_residual:
cell = ResidualWrapper(cell)
return cell
def build_encoder_cell(self):
"""构建单独的编码器 """
# 通过MultiRNNCells类来实现Deep RNN
return MultiRNNCell([
self.build_signle_cell(self.hidden_units, use_residual=self.use_residual) for _ in range(self.depth)
])
至此开始搭建真正的encoder_cell已经弄好了。首先用tf.nn.embedding_lookup来对输入做一个embedding当做encoder的输入。其中它的shape为batch_size, time_step, embedding_size],time_step是batch_size中每一句话的长度,embedding_size是词向量维度。
bidirectional_dynamic_rnn是双向动态RNN。
双向RNNs模型是RNN的扩展模型,RNN模型在处理序列模型的学习上主要是依靠上文的信息,双向RNNs模型认为模型的输出不仅仅依靠序列前面的元素,后面的元素对输出也有影响。比如说,想要预测序列中的一个缺失值,我们不仅仅要考虑该缺失值前面的元素,而且要考虑他后面的元素。
简单点来将两个RNN堆叠在一起,分别从两个方向计算序列的output和state,而最终的输出则根据两个RNNs的隐藏状态计算。值得注意的是:向后和向前隐含层之间没有信息流,是独立计算的,只是最后输出的时候把二者的状态向量结合起来,这保证了展开图是非循环的。函数的返回值:
一个(outputs, outputs_state)的一个元祖。
- outputs=(outputs_fw, outputs_bw),是一个包含前向cell输出tensor和后向tensor输出tensor组成的元祖。
- outputs_state = (outputs_state_fw, output_state_bw),包含了前向和后向最后的隐藏状态的组成的元祖。outputs_state_fw和output_state_bw的类型都是LSTMStateTuple。LSTMStateTuple由(c, h)组成,分别代表memory cell和hidden state
(
(encoder_fw_outputs, encoder_bw_outputs),
(encoder_fw_state, encoder_bw_state)
) = tf.nn.bidirectional_dynamic_rnn( #动态多层双向lstm_rnn
cell_fw=encoder_cell,
cell_bw = encoder_cell_bw,
inputs = inputs,
sequence_length = self.encoder_inputs_length,
dtype=tf.float32,
time_major=self.time_major,
parallel_iterations=self.parallel_iterations,
swap_memory = True
)
encoder_outputs = tf.concat([encoder_fw_outputs, encoder_bw_outputs], 2)
encoder_state = []
for i in range(self.depth):
encoder_state.append(encoder_fw_state[i])
encoder_state.append(encoder_bw_state[i])
encoder_state = tuple(encoder_state)
return encoder_outputs, encoder_state
这样encoder已经构建好了。首先说一下attention(注意力机制),只有在decoder才用到:
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此, c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。Attention机制通过在每个时间输入不同的c来解决这个问题。下图是带有Attention机制的Decoder:
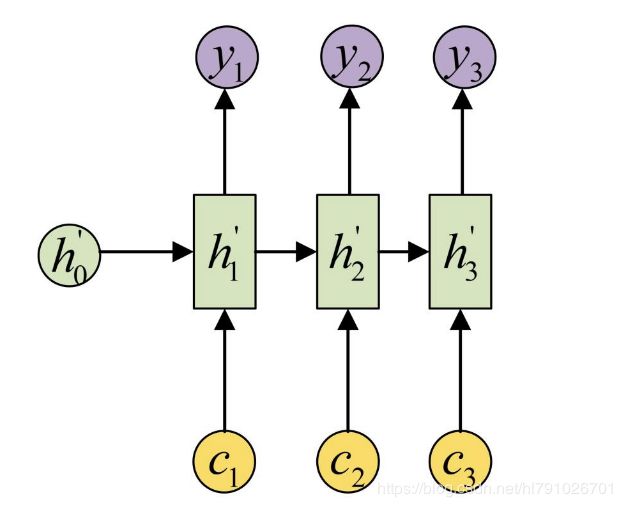
每一个c会自动去选取与当前所要输出的y最合适的上下文信息。具体来说,我们用 a_ ij衡量Encoder中第j阶段的hj和解码时第i阶段的相关性,最终Decoder中第i阶段的输入的上下文信息 c_ i 就来自于所有 h_ j 对 a_ ij 的加权和。
实现方式简单地说,就是先定义一层普通的 RNNCell(例如 LSTM),然后定义某种 Attention 机制的实例(如 LuongAttention 或者 BahdanauAttention),最后把这俩东西都传给 AttentionWrapper,返回封装后的 RNNCell。
这里decoder_cell 博主跟encoder_cell一样采用LSTM并且隐藏神经元个数和depth层数采用相同的参数。attention_mechanism(attention机制)我们采用BahdanauAttention
def cell_input_fn(inputs, attention):
""" 根据attn_input_feeding属性来判断是否在attention计算前进行一次投影的计算"""
if not self.use_residual:
return array_ops.concat([inputs, attention], -1)
attn_projection = layers.Dense(self.hidden_units,
dtype = tf.float32,
use_bias=False,
name='attention_cell_input_fn')
return attn_projection(array_ops.concat([inputs, attention], -1))
attention_cell = AttentionWrapper(
cell = cell,
attention_mechanism = self.attention_mechanism,
attention_layer_size= self.hidden_units,
alignment_history = alignment_history,
cell_input_fn = cell_input_fn,
name = 'AttentionWrapper'
)
在进行decoder时训练阶段和预测阶段是不一样的
-
training 1. seq2seq.TrainingHelper 2.seq2seq.BasicDecoder 3. seq2seq.dynamic_decode 4.seq2seq.sequence_loss返回loss对象。
-
prediction 1.BeamSearchDecoder 2.seq2seq.dynamic_decode
Beam Search算法是一种平衡性能与消耗的搜索算法,目的是在序列中解码出相对较优的路径,它算法作为一种折中手段,在相对受限的搜索空间中找出其最优解,得出的解接近于整个搜索空间中的最优解。
要想用beam_search的话,需要先将encoder的output、state、length使用tile_batch函数处理一下,将batch_size扩展beam_size倍变成batch_size*beam_size,具体原因就不说了。beam search的方法只用在测试的情况,因为在训练过程中,每一个decoder的输出是有正确答案的,也就不需要beam search去加大输出的准确率。当然也可以使用贪心策略进行搜索 :prediction 1seq2seq.GreedyEmbeddingHelper 2.seq2seq.BasicDecoder 3.seq2seq.dynamic_decode不过从效率上和效果上没有beam_search策略好。
- encoder-decoder构建完之后就是设置optimizer(优化器)。优化器 有很多种 ‘sgd’、'momentum’等这里我们就不一一展开了。博主使用的是tf.train.AdamOptimizer优化器设置好。在训练DL模型时,随着模型epoch迭代,往往会推荐逐渐减小learning rate,可以对训练的收敛有正向效果。博主采用tf.train.polynomial_decay多项式衰减的方式来更新学习率。这里博主家加上一个tf.clip_by_global_norm (梯度裁剪)修正梯度值,用于控制梯度爆炸的问题。梯度爆炸和梯度弥散的原因一样,都是因为链式法则求导的关系,导致梯度的指数级衰减。为了避免梯度爆炸,需要对梯度进行修剪。最后更新梯度参数列表。
def init_optimizer(self):
"""
sgd, adadelta, adam, rmsprop, momentum
"""
learning_rate = tf.train.polynomial_decay(
#多项式衰减
self.learning_rate,
self.global_step,
self.decay_steps,
self.min_learning_rate,
power=0.5
)
self.current_learning_rate = learning_rate
#返回需要训练的参数列表 trainalbe=True
trainable_params = tf.trainable_variables()
#设置优化器
if self.optimizer.lower() == 'adadelta':
self.opt = tf.train.AdadeltaOptimizer(
learning_rate = learning_rate
)
elif self.optimizer.lower() == 'adam':
self.opt = tf.train.AdamOptimizer(
learning_rate = learning_rate
)
elif self.optimizer.lower() == 'rmsprop':
self.opt = tf.train.RMSPropOptimizer(
learning_rate= learning_rate
)
elif self.optimizer.lower() == 'momentum':
self.opt = tf.train.MomentumOptimizer(
learning_rate = learning_rate, momentum=0.9
)
elif self.optimizer.lower() == 'sgd':
self.opt = tf.train.GradientDescentOptimizer(
learning_rate=learning_rate
)
gradients = tf.gradients(ys=self.loss, xs=trainable_params) #函数列表ys里的每一个函数对xs中的每一个变量求偏导,返回一个梯度张量的列表
#梯度裁剪 放置梯度爆炸
clip_gradients, _ = tf.clip_by_global_norm(
gradients, self.max_gradient_norm
)
#更新model
self.updates = self.opt.apply_gradients(
#进行BP算法
#由于apply_gradients函数接收的是一个(梯度张量, 变量)tuple列表
#所以要将梯度列表和变量列表进行捉对组合,用zip函数
zip(clip_gradients, trainable_params),
global_step = self.global_step
)
#添加self.loss_rewards 的update
gradients = tf.gradients(self.loss_rewards, trainable_params)
clip_gradients, _ = tf.clip_by_global_norm(
gradients, self.max_gradient_norm
)
self.updates_rewards = self.opt.apply_gradients(
zip(clip_gradients, trainable_params),
global_step=self.global_step
)
#添加self.loss_add 的update
gradients = tf.gradients(self.loss_add, trainable_params) # loss_add = loss+add_loss
clip_gradients, _ = tf.clip_by_global_norm(
gradients, self.max_gradient_norm
)
self.updates_add = self.opt.apply_gradients(
zip(clip_gradients, trainable_params),
global_step = self.global_step
)
至此聊天机器人重要部分已近介绍完了。
博主使用tf版本是1.10 ,训练了30个epoch,loss值大概降到1.36左右。下图是效果图

可以看出还有有一点点效果的,但是要达到工业级这种还有很长路的要走,目前主流的问答问答系统大多数目前还是采用基于检索的方式。
完整代码请访问这里。
也欢迎各位志同道合的朋友留言讨论。