自动摘要生成技术
- 一、概念
- 二、Extractive抽取式算法 - TextRank
- 1、TextRank算法提取关键词
- 2、TextRank算法提取关键词短语
- 3、TextRank算法生成摘要
- 1)文本相似度 - BM25算法
- 4、TextRank算法优势
- 5、TextRank算法存在的问题及解决策略
- 三、Abstractive抽取式算法
- 1、seq2seq + attention模型
- 1)seq2seq
- 2)attention机制
- a. 概念
- b. Attention Mechanism实例
- c. Attention机制的本质思想
- 2、基于Pointer network的生成式摘要模型
- 1、seq2seq + attention模型
- 三、文章摘要生成评价方法
- 1、概念
- 2、Edmundson
- 3、ROUGE(1, 2, ..., N)
- 4、ROUGE-L
一、概念
自动摘要技术解决的问题描述很简单,就是用一些精炼的话来概括整片文章的大意,用户通过读文摘就可以了解到原文要表达的意思。问题解决的思路有两种,一种是Extractive抽取式的,就是从原文中找到一些关键的句子,组合成一篇摘要;另外一种是Abstractive摘要式的,这就需要计算机可以读懂原文的内容,并且用自己的意思变大出来。现阶段,相对成熟的是抽取式方案,有很多很多算法,也有一些baseline测试,但得到的摘要效果差强人意。对后者的研究并不是很多,人类语言包括字、词、短语、句子、段落、文档这几个level,研究难度依次递增,理解句子、段落尚且困难,何况是文档,这是摘要生成最大的难点。
二、Extractive抽取式算法 - TextRank
- 关键词提取算法 - TextRank
- TextRank自动文摘
TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要,因为TextRank是基于PageRank的。PageRank设计之初是用于Google的网页排名的,以该公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。PageRank通过互联网中的超链接关系来确定一个网页的排名,其公式是通过一种投票的思想来设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道有哪些网页链接到网页A,也就是要首先得到网页A的入链,然后通过入链给网页A的投票来计算网页A的PR值。这样设计可以保证达到这样一个效果:当某些高质量的网页指向网页A的时候,那么网页A的PR值会因为这些高质量的投票而变大,而网页A被较少网页指向或被一些PR值较低的网页指向的时候,A的PR值也不会很大,这样可以合理地反映一个网页的质量水平。那么根据以上思想,佩奇设计了下面的公式:
该公式中,Vi表示某个网页,Vj表示链接到Vi的网页(即Vi的入链),S(Vi)表示网页的PR值,In(Vi)表示网页Vi的所有入链的集合,Out(Vj)表示网页Vj中的链接指向的网页的集合(即网页Vj链接的网页集合),d表示阻尼系数,是用来克服这个公式中 "d *" 后面部分的固有缺陷,即如果仅仅只有求和的部分,那么该公式将无法处理没有入链的网页的PR值,因为此时根据公式,这些网页的PR值为0,但实际情况不是如此,所以加入了一个阻尼系数来确保每个网页都有一个大于0的PR值,根据实验结果,在0.85的阻尼系数下,大约100多次的迭代PR值就能收敛到一个稳定的值,而当阻尼系数接近1时,需要迭代的次数会骤然增加很多,且排序不稳定。公式中S(Vj)前面的分数指的是Vj所有出链指向的网页应该平分Vj的PR值,这样才算是把自己的票分给了自己链接到的网页。
比如:a、b、c表示网页
S(Va) = (1 – 0.85) + 0.85 * ((1/2)*S(Vb) + (1/1) * S(Vc))
= 0.15 + 0.85 * (0.5 + 1) = 1.425
S(Vb) = 0.15
S(Vc) = 0.575
More iterations ……
1、TextRank算法提取关键词
提取出若干关键词,若原文本中存在若干个关键词相邻的情况,那么这些关键词可以构成一个关键短语。
TextRank是由PageRank改进而来,其公式有颇多相似之处,这里给出TextRank的公式:
可以看出,该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度,单词i和单词j共现的次数越多,权重Wij就越大。TextRank用于关键词提取的算法如下:
1)把给定的文本T按照完整句子进行切割,即T=[S1, S2, ..., Sm];
2)对于每个句子Si(属于T),进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即Si = [t_{i,1}, t_{i,2}, ..., t_{i,n} ],其中t_{i,j}表示保留后的候选关键词;
3)构建候选关键词图G =(V, E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边,当且仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口的大小,即最多共现K个单词;
4)根据上面的公式,迭代传播各节点的权重,直至收敛;
5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词;
6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成关键词短语。
2、TextRank算法提取关键词短语
提取关键词短语的方法基于关键词提取,可以简单认为:如果提取出的若干关键词在文本中相邻,那么构成一个被提取的关键短语。
3、TextRank算法生成摘要
将文本中的每个句子分别看做一个节点,如果两个句子有相似性,那么认为这两个句子对应的节点之间存在一条无向有权边,权值Wji是相似度,然后通过pagerank算法计算得到的重要性最高的若干句子可以当作摘要。考察句子相似度的方法是下面这个公式:
公式中,Si、Sj分别表示两个句子i和j,|Si|为句子i的单词数量,Wk表示句子中的词,那么分子部分的意思是同时出现在两个句子中的同一个词的个数,分母是对句子中词的个数求对数之和,分母这样设计可以遏制较长的句子在相似度计算上的优势。
根据以上相似度公式循环计算任意两个节点之间的相似度,根据阈值去掉两个节点之间相似度较低的边连接,构建出节点连接图,然后计算TextRank值(PR值),然后使用幂迭代法不断更新节点PR值,直到收敛,最终的PR值为句子的重要性得分。最后对所有TextRank值排序,选出TextRank值最高的几个节点对应的句子作为摘要。
其中,计算相似度作为节点连边权值Wji后,节点的PR值计算公式如下:
1)文本相似度 - BM25算法
- BM25算法
BM25算法,通常用来作搜索相关性平分,主要就是计算一个query里面所有词(语素)和文档的相关度,然后再把分数做累加操作,而每个词的相关度分数主要还是受到 tf-idf 的影响。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果d,计算每个语素qi与d的相关性得分,最后,将qi相对于d的相关性得分进行加权求和,从而得到Query与d的相关性得分。
BM25算法的一般性公式如下:
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
![]()
注:当n(qi)超过一半的时候,会导致此IDF值为负数,因此分子上的-n(qi)项可以不需要
N是文档总数,n(qi) 是包含该词(语素)的文档数,0.5是调教系数,避免n(qi)为0的情况,从这个公式可以看出N越大,n(qi)越小的,idf值越大,这也符合了"词的重要程度和其出现在总文档集合里的频率成反比"的思想,取个log是为了让idf的值受N和n(qi)的影响更加平滑。
BM25中语素qi与文档d的相关性得分 R(qi,d) 的一般形式:
其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率,dl是文档长度,avgdl 是文档平均长度,可以看出如果其他因素一样,dl 越大,相关度越低,这个也符合结论。至于会除以一个avgdl,是拿本篇文档长度和整体文档长度水平做比较,以免单独取dl值时过大。
由于绝大部分情况下,qi 在 Query 中只会出现一次,即 q_fi=1, 因此公式可以简化为:

影响BM25公式的因数有:
- idf:idf越高分数越高
- tf:tf越高分数越高
- dl/avgdl:如果该文档长度在文档水平中越高则分数越低。
- k1,b:分数的调节因子,其中k1,b都是调节因子,一般 k1=2, b=0.75
4、TextRank算法优势
无监督TextRank算法优势:
1)TextRank不依赖于文本单元的局部上下文,而是考虑全局信息,从全文中不断迭代采样的文本信息进行文本单元重要性学习;
2)TextRank识别文本中各种实体间的连接关系,利用了推荐的思想。文本单元会推荐与之相关的其他文本单元,推荐的强度是基于文本单元的重要性不断迭代计算得到。被其他句子高分推荐的句子往往在文本中更富含信息量,因此得分也高;
3)TextRank实现了“文本冲浪”的思路,意思与文本凝聚力类似。对于文本中的某一概念c,我们往往更倾向于接下来看与概念c相关的其他概念;
4)通过迭代机制,TextRank能够基于连接的文本单元的重要性来计算文本单元得分。
5、TextRank算法存在的问题及解决策略
问题:
1)摘要句子重复; 去除相似句子
2)摘要开头句子不适合作为句子;
3)部分摘要句子太长。 限定摘要句子长度
三、Abstractive抽取式算法
自动总结(Automatic Summarization)类型的模型一直是研究热点。直接抽出重要的句子的抽取式方法较为简单,有如textrank之类的算法,而生成式(重新生成新句子)较为复杂,效果也不尽如人意。目前比较流行的Seq2Seq模型,由 Sutskever等人提出,基于一个Encoder-Decoder的结构将source句子先Encode成一个固定维度d的向量,然后通过Decoder部分一个字符一个字符生成Target句子。添加入了Attention注意力分配机制后,使得Decoder在生成新的Target Sequence时,能得到之前Encoder编码阶段每个字符的隐藏层的信息向量Hidden State,使得生成新序列的准确度提高。
encoder-decoder框架的工作机制是:先使用encoder,将输入编码到语义空间,得到一个固定维数的向量,这个向量就表示输入的语义;然后再使用decoder,将这个语义向量解码,获得所需要的输出,如果输出是文本的话,那么decoder通常就是语言模型。这种机制的优缺点都很明显,优点:非常灵活,并不限制encoder、decoder使用何种神经网络,也不限制输入和输出的模态(例如image caption任务,输入是图像,输出是文本);而且这是一个端到端(end-to-end)的过程,将语义理解和语言生成合在了一起,而不是分开处理。缺点的话就是由于无论输入如何变化,encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本时,生成每个词所用到的语义向量都是一样的,这显然有些过于简单。
这里主要介绍两种算法:1)seq2seq + attention模型;2)基于Pointer Network的生成式摘要算法
1、seq2seq + attention模型
- 自然语言处理中的自注意力机制
- seq2seq + attention机制的应用
-
深度学习中Attention Mechanism详细介绍:原理、分类及应用
-
目前主流的attention方法有哪些
-
【计算机视觉】深入理解Attention机制
-
机器要怎么做文本摘要?
1)seq2seq
RNN最重要的一个变种:N vs M,这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型,即序列到序列模型。原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。序列形的数据就不太好用原始的神经网络处理了,为了建模序列问题,RNN引入了隐状态h(hidden state)的概念,h可以对序列形的数据提取特征,接着再转换为输出。
为此,Encoder-Decoder结构先将输入数据编码成一个上下文向量c:
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
还有一种做法是将c当做每一步的输入:
由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
- 机器翻译。Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的
- 文本摘要。输入是一段文本序列,输出是这段文本序列的摘要序列。
- 阅读理解。将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
- 语音识别。输入是语音信号序列,输出是文字序列。
- …………
2)attention机制
a. 概念
Attention是一种用于提升基于RNN(LSTM或GRU)的Encoder + Decoder模型的效果的的机制(Mechanism),一般称为Attention Mechanism。Attention Mechanism目前非常流行,广泛应用于机器翻译、语音识别、图像标注(Image Caption)等很多领域,之所以它这么受欢迎,是因为Attention给模型赋予了区分辨别的能力,例如,在机器翻译、语音识别应用中,为句子中的每个词赋予不同的权重,使神经网络模型的学习变得更加灵活(soft)。比如在图像标注应用中,可以解释图片不同的区域对于输出Text序列的影响程度
 通过上述Attention Mechanism在图像标注应用的case可以发现,Attention Mechanism与人类对外界事物的观察机制很类似,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分,比如我们看到一个人时,往往先Attention到这个人的脸,然后再把不同区域的信息组合起来,形成一个对被观察事物的整体印象。因此,Attention Mechanism可以帮助模型对输入的X每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因。
通过上述Attention Mechanism在图像标注应用的case可以发现,Attention Mechanism与人类对外界事物的观察机制很类似,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分,比如我们看到一个人时,往往先Attention到这个人的脸,然后再把不同区域的信息组合起来,形成一个对被观察事物的整体印象。因此,Attention Mechanism可以帮助模型对输入的X每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因。
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此,c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。 所谓注意力机制,就是说在生成每个词的时候,对不同的输入词给予不同的关注权重。谷歌博客里介绍神经机器翻译系统时所给出的动图形象地展示了attention。
b. Attention Mechanism实例
Attention机制通过在每个时间输入不同的c来解决这个问题,下图是带有Attention机制的Decoder:
每一个c会自动去选取与当前所要输出的y最合适的上下文信息。具体来说,我们用 aij 衡量Encoder中第j阶段的hj和解码时第i阶段的相关性(表示Encoder中的第j个词与Decoder端的第i个词之间的权值,表示源端第j个词对目标端第i个词的影响程度),最终Decoder中第i阶段的输入的上下文信息 ci 就来自于所有 hj 对 aij 的加权和。以机器翻译为例(将中文翻译成英文):
输入的序列是“我爱中国”,因此,Encoder中的h1、h2、h3、h4就可以分别看做是“我”、“爱”、“中”、“国”所代表的信息。在翻译成英语时,第一个上下文c1应该和“我”这个字最相关,因此对应的 a_{11} 就比较大,而相应的 a_{12} 、 a_{13} 、 a_{14} 就比较小。c2应该和“爱”最相关,因此对应的 a_{22} 就比较大。最后的c3和h3、h4最相关,因此 a_{33} 、 a_{34} 的值就比较大。
至此,关于Attention模型,我们就只剩最后一个问题了,那就是:这些权重 a_{ij} 是怎么来的?事实上, a_{ij} 同样是从模型中学出的,它实际和Decoder的第i-1阶段的隐状态(即当前即将输出的上文信息)、Encoder第j个阶段的隐状态有关。
同样还是拿上面的机器翻译举例, a_{1j} 的计算(此时箭头就表示对h'和 h_j 同时做 变换):
a_{2j} 的计算:
a_{3j} 的计算:
c. Attention机制的本质思想
Attention机制的本质来自于人类视觉注意力机制。人们视觉在感知东西的时候一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。而且当人们发现一个场景经常在某部分出现自己想观察的东西时,人们会进行学习在将来再出现类似场景时把注意力放到该部分上。

Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射,即将Encoder中的构成元素想象成是由一系列的
![]()
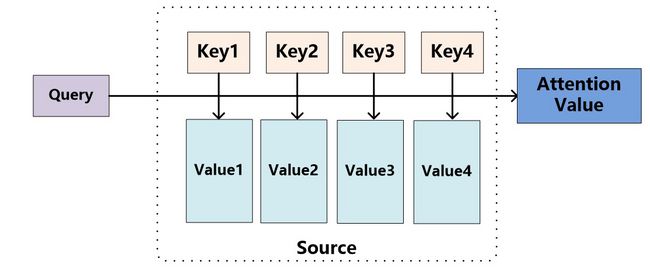
在计算attention时主要分为三步:
- 第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积、拼接、感知机等;
- 第二步一般是使用一个softmax函数对这些权重进行归一化;
- 最后将权重和相应的键值value进行加权求和得到最后的attention。
目前在NLP研究中,key和value常常都是同一个,即key=value。
 Attention值计算过程具体一点就是:
Attention值计算过程具体一点就是:
第一个阶段:可以引入不同的函数和计算机制,根据Query和某个Key_i,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性(余弦相似度)或者通过再引入额外的神经网络来求值(比如采用TF-IDF模型计算句子的相似度),即如下方式:

第二阶段:由于第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,因此第二阶段引入类似 SoftMax 的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:

第三阶段:第二阶段的计算结果 a_i,即为value_i对应的权重系数,然后进行加权求和即可得到Attention数值:
![]()
通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。当然,从概念上理解,把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
另外还有一种理解,也可以将Attention机制看作一种软寻址(Soft Addressing):Source可以看作存储器内存储的内容,元素由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention数值。通过Query和存储器内元素Key的地址进行相似性比较来寻址,之所以说是软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。所以不少研究人员将Attention机制看作软寻址的一种特例,这也是非常有道理的。
2、基于Pointer network的生成式摘要模型
Abigail See et al. 2017 在seq2seq+attention模型的基础上引入Pointer-Generator机制构造出了新的文本摘要模型。这个模型既能够从源文本中选择复制单词,同时还保留从固定词汇集中生成单词的能力。大致步骤如下:
1)计算Seq2Seq+Attention decode出的词汇分布概率及Attention分布概率;
2)引入一个Generation Probability(Pgen)來和词汇分布概率及Attention分布概率做加权总和來调整最后输出的词汇分布概率,这样做能赋予模型決定是否要直接复制原始文本词汇的能力。同时,这个方法也可增强模型在处理在训练过程中没见过的词汇的能力,进而减少训练模型所需用到的词汇表。作者以实验证明这个方法可以有效改善;
3)另外引入一个汇聚(Coverage)的概念和一个新的loss來改善重复生成问题。其思想就是,利用注意力分布区追踪目前应被覆盖的单词,并且当网络再次注意同一部分的时候,予以惩罚。在decoder的每一个时间步长 t 上,汇聚向量 ct 是截至目前所有的注意力分布 at'的和:
那么某一特定的源单词的收敛就是到此刻它所受到的attention的和。最后,引入额外的损失项来惩罚汇聚向量 ct 和新的注意力分布 at' 之间的任何交叠,如下所示:
那么最终的损失函数的公式为:
其中w*t是当前时刻t的目标参考词,这样可以避免网络继续重视(从而摘录)那些已经被覆盖到的词汇。
基于Pointer network的生成模型:
seq2seq + attention模型:
抽象式摘要生成算法论文学习:
[1] A Neural Attention Model for Abstractive Sentence Summarization
[2] Abstractive Sentence Summarization with Attentive Recurrent Neural Networks
三、文章摘要生成评价方法
- 自动文档摘要评价方法
1、概念
自动文档摘要评价方法大致分为两类:
- 内部评价方法(Intrinsic Methods):提供参考摘要,以参考摘要为基准评价系统摘要的质量。系统摘要与参考摘要越吻合, 质量越高。
- 外部评价方法(Extrinsic Methods):不提供参考摘要,利用文档摘要代替原文档执行某个文档相关的应用。例如:文档检索、文档聚类、文档分类等, 能够提高应用性能的摘要被认为是质量好的摘要。
其中内部评价方法,是比较直接比较纯粹的,被学术界最常使用的文摘评价方法,将系统生成的自动摘要与专家摘要采用一定的方法进行比较也是目前最为常见的文摘评价模式,常见的方法有Edmundson和ROUGE。
2、Edmundson
Edmundson评价方法比较简单,可以客观评估,就是通过比较机械文摘(自动文摘系统得到的文摘)与目标文摘的句子重合率(coselection rate)的高低来对系统摘要进行评价。也可以主观评估,就是由专家比较机械文摘与目标文摘所含的信息,然后给机械文摘一个等级评分。 类如等级可以分为:完全不相似,基本相似,很相似,完全相似等。
Edmundson比较的基本单位是句子,通过句子级标号分隔开的文本单元,句子级标号包括“。”“:”“;”“!”“?”,并且只允许专家从原文中抽取句子,而不允许专家根据自己对原文的理解重新生成句子,专家文摘和机械文摘的句子都按照在原文中出现的先后顺序给出。
计算公式:重合率p = 匹配句子数 / 专家文摘句子数 x 100%
每一个机械文摘的重合率为按三个专家给出的,则文摘得到的重合率的平均值:平均重合率 = (p1 + p2 + ... + pn) /n x 100%
即对所有专家的重合率取一个均值,Pi为相对于第i个专家的重合率,n为专家的数目。
3、ROUGE(1, 2, ..., N)
ROUGE是由ISI的Lin和Hovy提出的一种自动摘要评价方法,现被广泛应用于DUC(Document Understanding Conference)的摘要评测任务中。ROUGE基于摘要中n元词(n-gram)的共现信息来评价摘要,是一种面向n元词召回率的评价方法。ROUGE准则由一系列的评价方法组成,包括ROUGE-1,ROUGE-2,ROUGE-3,ROUGE-4,以及ROUGE-Skipped-N-gram等,1、2、3、4分别代表基于1元词到4元词以有跳跃的N-gram模型。在自动文摘相关研究中,一般根据自己的具体研究内容选择合适的N元语法ROUGE方法。
计算公式:

其中,n-gram表示n元词,{Ref Summaries}表示参考摘要,即事先获得的标准摘要,Countmatch(n-gram)表示系统摘要和参考摘要中同时出现n-gram的个数,Count(n-gram)则表示参考摘要中出现的n- gram个数。不难看出,ROUGE公式是由召回率的计算公式演变而来的,分子可以看作“检出的相关文档数目”,即系统生成摘要与标准摘要相匹配的N-gram个数,分母可以看作“相关文档数目”,即标准摘要中所有的N-gram个数。
比如:
自动摘要Y(一般自动生成):the cat was found under the bed
参考摘要X(人工生成):the cat was under the bed
则总结的1-gram、2-gram如下,N-gram以此类推:
Rough-1(X ,Y) = 6 / 6 = 1.0 Rough-1(X1,Y) = 6 / 6 = 1.0,分子是待评测摘要和参考摘要都出现的1-gram的个数,分母是参考摘要的1-gram个数。(其实分母也可以是待评测摘要的,但是在精确率和召回率之间,我们更关心的是召回率Recall,同时这也和上面ROUGN-N的公式相同)
同样,Rough-2(X,Y) = 4 / 5 = 0.8
4、ROUGE-L
L即是LCS(longest common subsequence,最长公共子序列)的首字母,因为Rough-L使用了最长公共子序列。Rough-L计算方式如下图:
其中 LCS (X ,Y) 是X和Y的最长公共子序列的长度,m、n分别表示参考摘要和自动摘要的长度(一般就是所含词的个数),R_lcs、P_lcs分别表示召回率和准确率。最后的 F_lcs 就是的 Rough-L 值。在DUC中,β被设置为一个很大的数,所以 Rough-L 几乎只考虑了 R_lcs,与上文所说的一般只考虑召回率对应。