redis源码分析 -- redis对象系统
redis 中使用的主要数据结构有简单动态字符串(sds)、双向链表(linkedlist)、字典(dict)、压缩列表(ziplist)、整数集合(set)等,但是 redis 并没有直接使用这些结构,而是通过这些数据结构创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象,而每种对象都使用了至少一种数据结构。
对象结构
/* A redis object, that is a type able to hold a string / list / set */
/* The actual Redis Object */
#define REDIS_LRU_BITS 24
#define REDIS_LRU_CLOCK_MAX ((1<lru */
#define REDIS_LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
redis 使用对象来表示数据库中的键和值,也就是说,每一个键值对,都至少有两个对象,一个对象表示键,一个表示值。这个结构体大小 sizeof (robj) 为12,因为前三个元素是位域,共32位,4个字节可以表示。
redis 对象的结构如上所示,有五个成员:
type: 表示对象的类型,对应的是 redis 中的 TYPE 命令,在 redis 中,键总是一个字符串对象,而值可以是字符串对象、列表对象、哈希对象、集合对象或者有序集合对象中一种。
encoding: redis 的编码,这个属性,决定 ptr 指向对象的底层实现数据结构是什么数据结构。
lru: 可以理解为 last recently used,用于记录 redis 对象最后一次被命令程序访问的时间信息,可以用于计算数据库键的空转时长,即当前时间减去 lru 就是空转时长, redis 可以将空转时长大的键值对优先删除。
refcount: 对象的引用计数,redis 舒勇引用计数器的方法对对象进行管理,如果该值为0,就释放当前对象。
ptr: 对象指向的值,该值的数据结构由 encoding 编码决定。
对象的类型 (TYPE)
对象的 TYPE 属性记录了对象的类型。在 redis 客户端中,当使用 TYPE 命令查看某个键的类型时,服务器会根据对象的类型返回相应的值。
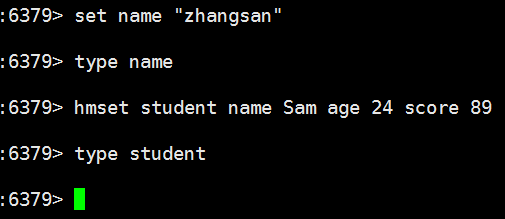
那代码中, TYPE 命令有几个值呢
/* Object types */
#define REDIS_STRING 0 /* 字符串对象,返回 "string" */
#define REDIS_LIST 1 /* 列表对象,返回 "list" */
#define REDIS_SET 2 /* 集合对象,返回 "set" */
#define REDIS_ZSET 3 /* 有序集合对象,返回 "zset" */
#define REDIS_HASH 4 /* 哈希对象,返回 "hash" */
上面列出了对象的所有类型
对象的编码(encoding)
encoding 属性决定了对象的 ptr 指向的底层数据结构的实现,也就是说这个对象使用了什么数据结构作为底层实现。 redis 中的宏常量为
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define REDIS_ENCODING_RAW 0 /* Raw representation */
#define REDIS_ENCODING_INT 1 /* Encoded as integer */
#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
每种类型的对象都至少使用了两种不同的编码。其中,字符串编码有 REDIS_ENCODING_RAW 和 REDIS_ENCODING_EMBSTR 两种,前者是普通的 sds 字符串对象,但是当字符串长度不超过39时, redis 为了节约内存,使用的是后面的字符串编码方式。
在 redis 中,可以通过使用 OBJECT ENCODING 命令来查看键的编码方式
/* results of "object encoding" command */
char *strEncoding(int encoding) {
switch(encoding) {
case REDIS_ENCODING_RAW: return "raw";
case REDIS_ENCODING_INT: return "int";
case REDIS_ENCODING_HT: return "hashtable";
case REDIS_ENCODING_LINKEDLIST: return "linkedlist";
case REDIS_ENCODING_ZIPLIST: return "ziplist";
case REDIS_ENCODING_INTSET: return "intset";
case REDIS_ENCODING_SKIPLIST: return "skiplist";
case REDIS_ENCODING_EMBSTR: return "embstr";
default: return "unknown";
}
}
strEncoding 函数返回了 OBJECT ENCODING 命令时的结果。
通过 encoding 属性来设定对象所使用的编码,而不是为特定类型的对象关联一种固定的编码,极大的提升了 redis 的灵活性和效率。 redis 可以根据不同的使用场景来为对象设置不同的编码,从而可以优化对象在某一场景下的效率。因为列表的编码之间是可以转换的(不是任意转换)。比如:
当哈希对象所保存的元素比较少时,redis 使用压缩列表作为哈希对象的底层实现:
- 压缩列表比字典哈希更节约内存(字典通过拉链表解决冲突,一部分是通过单链表实现的),且在内存中是以连续块的方式保存的,可以更快的加载到缓存中;
- 随着哈希对象元素的不断增加,使用压缩列表的方式保存元素的优势逐逐渐消失时,对象就将底层实现从压缩列表转向功能更强、更合适的字典哈希上。
其他类型的对象也会使用多种不同的编码来进行类似的优化。
redis中不同的对象
redis 中根据不同数据类型创建不同的对象,设置对象的类型,编码和ptr 指针,同时,将引用计数器 refcount 的值设置为1
字符串对象
字符串对象的类型 TYPE 为 REDIS_STRING,而编码可以为 int (REDIS_ENCODING_INT)、 raw (REDIS_ENCODING_RAW)和 embstr (REDIS_ENCODING_EMBSTR)。
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o)); // sizeof (robj) is 12 bytes
o->type = type;
o->encoding = REDIS_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution). */
o->lru = LRU_CLOCK();
return o;
}
createObject 函数就是创建一个字符串对象。如果对象保存的是一个字符串的值,同时这个字符串的长度大于39,那么对象将通过一个简单动态字符串(SDS)来保存这个值,并将编码设置为 raw。
/* Create a string object with encoding REDIS_ENCODING_RAW, that is a plain
* string object where o->ptr points to a proper sds string. */
robj *createRawStringObject(char *ptr, size_t len) {
return createObject(REDIS_STRING,sdsnewlen(ptr,len));
}
其结构如下所示:

当对象保存的值是整数时,将字符串的编码设置为REDIS_ENCODING_INT,同时将整数值保存在字符串对象结构的 ptr 里面
robj *createStringObjectFromLongLong(long long value) {
robj *o;
if (value >= 0 && value < REDIS_SHARED_INTEGERS) {
incrRefCount(shared.integers[value]); // 引用计数器,如果整数在 0 - 10000范围内,不需要再创建对象,只需要将对应的引用计数器加1,后面在详细讨论
o = shared.integers[value];
} else {
if (value >= LONG_MIN && value <= LONG_MAX)
o = createObject(REDIS_STRING, NULL);
o->encoding = REDIS_ENCODING_INT;
o->ptr = (void*)((long)value); //转成 void*
} else { // 超出范围,将数字转成字符串存储
o = createObject(REDIS_STRING,sdsfromlonglong(value)); //convert long long to string
}
}
return o;
}
如果对象保存的是字符串,且字符串的长度小于39时, redis 为了节约内存,使用另一种字符串的存储方式 embstr,创建字符串对象。
embstr 编码是专门用于保存短字符串的一种优化编码结构,这种编码与 raw 一样,都是用 redisObject 结构和 sdshdr 结构来表示字符串对象,但是 raw 编码在通过调用 createRawStringObject 函数时,需要调用两次内存分配,先通过 sdsnew 创建 sds ,然后在通过 createObject 创建字符串对象 redisObject,而 embstr 编码只需要一次内存分配。
/* Create a string object with encoding REDIS_ENCODING_EMBSTR, that is
* an object where the sds string is actually an unmodifiable string
* allocated in the same chunk as the object itself. */
robj *createEmbeddedStringObject(char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr)+len+1);
struct sdshdr *sh = (void*)(o+1); //申请的是连续空间,sh指向了sdshdr,跳过了robj
o->type = REDIS_STRING;
o->encoding = REDIS_ENCODING_EMBSTR;
o->ptr = sh+1; // sdshdr 中 buf 是可变长数组,sizeof (sdshdr) is 8 bytes,此时,ptr 刚好指向的就是 buf,申请的连续内存,后面对buf赋值
o->refcount = 1;
o->lru = LRU_CLOCK();
sh->len = len;
sh->free = 0;
if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
embstr 编码通过一次内存分配申请一块连续的内存空间,包括 redisObject 和 sdshdr
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr)+len+1);
然后获取 sdshdr 在这个连续空间出的位置
struct sdshdr *sh = (void*)(o+1);
将 TYPE 设置为 REDIS_STRING,encoding 设置为 REDIS_ENCODING_EMBSTR,因为是连续的内存块,通过 sdshdr 结构体的说明可知, sizeof (sdshdr) 的大小为8,成员 buf 是可变长数组,是不能通过sizeof 计算长度的,所以获取 sdshdr 的地址 sh 后,往后便宜 sizeof (sdshdr) 的大小就是 buf 字符串的值。
o->ptr = sh+1;
其结构如下所示
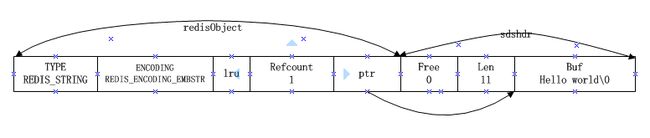
使用 embstr 编码保存字符串的优点:
- embstr 创建字符串对象时比 raw 编码创建对象少分进行一次内存分配
- 释放时,同样,embstr 只需释放一次,raw 需要释放两次
- embstr 编码将字符串对象保存在一块连续的内存空间中,它比 raw 编码的字符串能够更快的加载到缓存,能够更好的利用缓存带来的优势。
long double 类型的浮点数,在 redis 中也是作为字符串的值来保存的。
/* Create a string object from a long double. If humanfriendly is non-zero
* it does not use exponential format and trims trailing zeroes at the end,
* however this results in loss of precision. Otherwise exp format is used
* and the output of snprintf() is not modified.
*
* The 'humanfriendly' option is used for INCRBYFLOAT and HINCRBYFLOAT. */
robj *createStringObjectFromLongDouble(long double value, int humanfriendly) {
char buf[256];
int len;
if (isinf(value)) {
/* Libc in odd systems (Hi Solaris!) will format infinite in a
* different way, so better to handle it in an explicit way. */
if (value > 0) {
memcpy(buf,"inf",3);
len = 3;
} else {
memcpy(buf,"-inf",4);
len = 4;
}
} else if (humanfriendly) {
/* We use 17 digits precision since with 128 bit floats that precision
* after rounding is able to represent most small decimal numbers in a
* way that is "non surprising" for the user (that is, most small
* decimal numbers will be represented in a way that when converted
* back into a string are exactly the same as what the user typed.) */
len = snprintf(buf,sizeof(buf),"%.17Lf", value);
/* Now remove trailing zeroes after the '.' */
if (strchr(buf,'.') != NULL) {
char *p = buf+len-1;
while(*p == '0') {
p--;
len--;
}
if (*p == '.') len--;
}
} else {
len = snprintf(buf,sizeof(buf),"%.17Lg", value); //将浮点数转变成字符串,保留17位小数
}
return createStringObject(buf,len);
}
将浮点数通过 snprintf 的方法转成字符串,保留17为小数,如果需要可读性好,将小数点后的最后一个非0数字后的0全部去掉,但是这样会降低精度。
如果需要对保存到 redis 中的浮点数进行操作,比如加上或者减去某个值, redis 会先将字符串转成浮点数,计算后再转成字符串保存在 redis 中
int getLongDoubleFromObject(robj *o, long double *target) {
long double value;
char *eptr;
if (o == NULL) {
value = 0;
} else {
redisAssertWithInfo(NULL,o,o->type == REDIS_STRING);
if (sdsEncodedObject(o)) {
errno = 0;
value = strtold(o->ptr, &eptr); // convert string to long double
if (isspace(((char*)o->ptr)[0]) || eptr[0] != '\0' ||
errno == ERANGE || isnan(value))
return REDIS_ERR;
} else if (o->encoding == REDIS_ENCODING_INT) {
value = (long)o->ptr;
} else {
redisPanic("Unknown string encoding");
}
}
*target = value;
return REDIS_OK;
}
编码的转换
字符串对象中,int 编码和 embstr 编码在一定条件下可以转换成 raw 编码。
对于 int 编码对象,如果在 redis 中,对该对象进行操作,比如 append 一个字符串,是的该对象的值不在保存的是整数值,而是字符串时,该对象的编码将变成的 raw (REDIS_ENCODING_RAW)
对与 embstr 编码对象,因为 redis 没有为 embstr 编码的字符串编写任何相应的修改程序(只有 int 编码和 raw 编码的字符串对象才有),所以 embstr 编码的字符串对象实际上是只读的。当需要修改 embstr 编码的对象时, redis 首先将该对象的编码从 embstr 转换成 raw,然后再进行修改。所以,embstr 编码的字符串对象,在修改之后,总是编程 raw 编码的字符串对象。
其他对象
下面分别是创建双向链表对象、压缩列表对象、集合对象、整数集合对象、有序集合对象、哈希对象和有序集合压缩列表对象。后续在深入分析这些代码时,在分别对这些对象的结构、编码转换等做详细的分析。
robj *createListObject(void) {
list *l = listCreate();
robj *o = createObject(REDIS_LIST,l);
listSetFreeMethod(l,decrRefCountVoid);
o->encoding = REDIS_ENCODING_LINKEDLIST;
return o;
}
robj *createZiplistObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(REDIS_LIST,zl);
o->encoding = REDIS_ENCODING_ZIPLIST;
return o;
}
robj *createSetObject(void) {
dict *d = dictCreate(&setDictType,NULL);
robj *o = createObject(REDIS_SET,d);
o->encoding = REDIS_ENCODING_HT;
return o;
}
robj *createIntsetObject(void) {
intset *is = intsetNew();
robj *o = createObject(REDIS_SET,is);
o->encoding = REDIS_ENCODING_INTSET;
return o;
}
robj *createHashObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(REDIS_HASH, zl);
o->encoding = REDIS_ENCODING_ZIPLIST;
return o;
}
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
zs->dict = dictCreate(&zsetDictType,NULL);
zs->zsl = zslCreate();
o = createObject(REDIS_ZSET,zs);
o->encoding = REDIS_ENCODING_SKIPLIST;
return o;
}
robj *createZsetZiplistObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(REDIS_ZSET,zl);
o->encoding = REDIS_ENCODING_ZIPLIST;
return o;
}
类型检查
redis 中用于操作键的命令可分为两种,一种可以对任何类型的键进行操作,比如 DEL、EXPIRE、RENAME、TYPE、OBJECT 等,另一种只能对特定类型的键执行,比如 SET、GET、APPEND、STRLEN 只能对字符串键执行,而 RPUSH、HSET、HGET、HLEN 只能对列表键执行,如果用 SET 对列表键执行,redis 将返回一个错误。
为了确保指定的键能够执行某些特定的命令,redis 在执行命令前会先检查输入键的类型是否正确,然后再决定是否执行给定的命令。
int checkType(redisClient *c, robj *o, int type) {
if (o->type != type) {
addReply(c,shared.wrongtypeerr); //wrong_type_err
return 1;
}
return 0;
}
通过 redisObject 的 TYPE 属性来判断类型是否正确:
- 在执行一个特定的命令之前,服务器会先检查输入数据库键的值对象是否为执行命令所需的类型,如果是,才会执行指定的命令
- 否则,服务器将拒绝执行命令,并返回一个错误
多态命令的实现
redis 除了根据对象的 TYPE 属性判断键能否执行指定的命令之外,还需要根据编码属性 encoding 来选择正确的命令实现代码执行命令(因为通常一种对象因为优化的原因可以有不同的编码方式)。
比如列表对象,可以有 linkedlist(REDIS_ENCODING_LINEDLIST) 和 ziplist(REDIS_ENCODING_ZIPLIST) 两个编码方式,但是,在执行 LLEN 命令时,redis 除了需要判断 TYPE 是否是 REDIS_LIST 外,还需要根据编码判断是 linkedlist 还是 ziplist,然后才能使用双向链表的 API 还是 ziplist 的 API 执行相应的函数获取长度。
void llenCommand(redisClient *c) {
robj *o = lookupKeyReadOrReply(c,c->argv[1],shared.czero);
if (o == NULL || checkType(c,o,REDIS_LIST)) return;
addReplyLongLong(c,listTypeLength(o));
}
unsigned long listTypeLength(robj *subject) {
if (subject->encoding == REDIS_ENCODING_ZIPLIST) {
return ziplistLen(subject->ptr);
} else if (subject->encoding == REDIS_ENCODING_LINKEDLIST) {
return listLength((list*)subject->ptr);
} else {
redisPanic("Unknown list encoding");
}
}
上面两个函数展示了 LLEN 的求取过程。
借用面向对象的术语,我们可以认为 LLEN 命令是多态的,只要执行 LLEN,不管对象的编码方式是 linkedlist 还是 ziplist ,都可以得到列表对象的长度。
(就像 the pragmatic programmer 中所说,思想的“异花授粉”(cross-pollination),当你熟悉面向对象时,可以使用不同的方式编写纯c,加入面向对象的思想)。
而相对于特征类型的特定命令,DEL、EXPIRE、TYPE、OBJECT等这些命令可以同时处理多种不同类型的键,前者是基于编码的多态,后者是基于类型的多态。
内存技术器 refcount
C语言没有内存回收功能,所以 redis 在自己的对象系统中,构建了一个内存计数器 (reference counting) 技术实现内存回收功能。通过这一机制,程序可以通过跟踪对象的引用计数信息,当 refcount 为 0 时释放对象回收内存。
在 redisObject 对象中有一个 refcount 属性,该属性记录的就是对象的引用计数信息。对象的引用计数信息会随着对象的状态变化而不断变化。
- 创建新对象时,引用计数器设置为1
- 当对象被新程序使用时,引用计数值加1 (
incrRefCount) - 当对象不再被新程序使用时,引用计数减1 (
decrRefCount) - 当对象的引用计数为0时,释放对象
void decrRefCount(robj *o) {
if (o->refcount <= 0) redisPanic("decrRefCount against refcount <= 0");
if (o->refcount == 1) {
switch(o->type) {
case REDIS_STRING: freeStringObject(o); break;
case REDIS_LIST: freeListObject(o); break;
case REDIS_SET: freeSetObject(o); break;
case REDIS_ZSET: freeZsetObject(o); break;
case REDIS_HASH: freeHashObject(o); break;
default: redisPanic("Unknown object type"); break;
}
zfree(o);
} else {
o->refcount--;
}
}
对象共享
不知道大家还记不记得,上面的字符串对象中,当编码方式为int (REDIS_ENCODING_INT)时,对象的创建函数 createStringObjectFromLongLong,当整数值在 0 - 10000的范围内时,不会新创建一个字符串对象,而是将 shared 这个共享对象中的 intergers 这个 redisObject 对象数组中对应的元素添加一个指向该元素的引用,同时将该元素的引用计数加1。
shared 是一个全局变量,用于共享
* Our shared "common" objects */
struct sharedObjectsStruct shared;
在 createSharedObject 函数中创建和初始化,其中,对 intergers 数组初始化如下
for (j = 0; j < REDIS_SHARED_INTEGERS; j++) {
shared.integers[j] = createObject(REDIS_STRING,(void*)(long)j);
shared.integers[j]->encoding = REDIS_ENCODING_INT;
}
其中,REDIS_SHARED_INTEGERS 这个常量为 10000,可以通过修改这个值,来改变共享整数对象的范围。
redis 的引用计数机制,实现的共享对象的方法,能够极大的节约内存,所引用的对象,出了引用计数进行了加1之外,其他属性都没有发生改变。数据库中保存的相同值对象越多,就越能节约内存。
在 redis 中,不仅只有字符串对象能够使用这些共享对象,在数据结构中嵌套了字符串对象的其他对象,都可以使用这些共享对象(redis 中目前只能嵌套字符串对象)。
在 redis 中,考虑到时间复杂度和CPU时间的限制,只共享保存整数值的字符串对象,这是因为,在决定共享对象能够被其他对象直接使用时,redis 需要保证共享对象与目标对象时完全相同的,只有保存整数值的字符串对象才是最简单的,复杂度最低,而保存的值越复杂,验证共享对象和目标对象是否相同所需的复杂度就越高,消耗CPU的时间就越多。
对象的空转时长
redisObject 中 lru 属性,记录的就是对象的访问时间信息,根据该信息就能够计算出对象的空转时长。
OBJECT IDLETIME 命令可以打印兑现的空转时长,这是通过将当前时间减去键的值对象的 lru 的时间计算得出的。
/* Given an object returns the min number of milliseconds the object was never
* requested, using an approximated LRU algorithm. */
unsigned long long estimateObjectIdleTime(robj *o) {
unsigned long long lruclock = LRU_CLOCK();
if (lruclock >= o->lru) {
return (lruclock - o->lru) * REDIS_LRU_CLOCK_RESOLUTION;
} else {
return (lruclock + (REDIS_LRU_CLOCK_MAX - o->lru)) *
REDIS_LRU_CLOCK_RESOLUTION;
}
}
OBJECT IDLTTIME 这个命令不会改变对象的 lru 属性,像 GET、SET等命令都会改变对象的 lru 属性
键的空转时长还有另外一个作用,就是如果服务器打开了 maxmemory 选项,并且服务器的回收内存算法为 volatile-lru 或者 allkeys-lru,那么当服务器的内存数超过 maxmemory 时,空转时长较高的那部分键会被服务器优先释放,回收内存。
其他
OBJECT的命令实现
OBJECT 的三种命令
/* Object command allows to inspect the internals of an Redis Object.
* Usage: OBJECT */
void objectCommand(redisClient *c) {
robj *o;
if (!strcasecmp(c->argv[1]->ptr,"refcount") && c->argc == 3) {
if ((o = objectCommandLookupOrReply(c,c->argv[2],shared.nullbulk))
== NULL) return;
addReplyLongLong(c,o->refcount);
} else if (!strcasecmp(c->argv[1]->ptr,"encoding") && c->argc == 3) {
if ((o = objectCommandLookupOrReply(c,c->argv[2],shared.nullbulk))
== NULL) return;
addReplyBulkCString(c,strEncoding(o->encoding));
} else if (!strcasecmp(c->argv[1]->ptr,"idletime") && c->argc == 3) {
if ((o = objectCommandLookupOrReply(c,c->argv[2],shared.nullbulk))
== NULL) return;
addReplyLongLong(c,estimateObjectIdleTime(o)/1000);
} else {
addReplyError(c,"Syntax error. Try OBJECT (refcount|encoding|idletime)");
}
}
redis中将字符串转与long long的巧妙转换
/* Convert a long long into a string. Returns the number of
* characters needed to represent the number.
* If the buffer is not big enough to store the string, 0 is returned.
*
* Based on the following article (that apparently does not provide a
* novel approach but only publicizes an already used technique):
*
* https://www.facebook.com/notes/facebook-engineering/three-optimization-tips-for-c/10151361643253920
*
* Modified in order to handle signed integers since the original code was
* designed for unsigned integers. */
int ll2string(char* dst, size_t dstlen, long long svalue) {
static const char digits[201] =
"0001020304050607080910111213141516171819"
"2021222324252627282930313233343536373839"
"4041424344454647484950515253545556575859"
"6061626364656667686970717273747576777879"
"8081828384858687888990919293949596979899";
/* digits 数组保存的是0-99这100个数字的字符串数组,每一个数字由两个字符组成 */
int negative;
unsigned long long value;
/* The main loop works with 64bit unsigned integers for simplicity, so
* we convert the number here and remember if it is negative. */
if (svalue < 0) {
if (svalue != LLONG_MIN) {
value = -svalue;
} else {
value = ((unsigned long long) LLONG_MAX)+1;
}
negative = 1;
} else {
value = svalue;
negative = 0;
}
/* Check length. */
uint32_t const length = digits10(value)+negative;
if (length >= dstlen) return 0;
/* Null term. */
uint32_t next = length;
dst[next] = '\0';
next--;
/* 每次取100的模数,相当于取最后两位数字,在 digits 数组中查找,因为数组中记录的就是0-99的数字,对应的下标是数字*2 */
while (value >= 100) {
int const i = (value % 100) * 2;
value /= 100;
dst[next] = digits[i + 1];
dst[next - 1] = digits[i];
next -= 2;
}
/* Handle last 1-2 digits. */
if (value < 10) {
dst[next] = '0' + (uint32_t) value;
} else {
int i = (uint32_t) value * 2;
dst[next] = digits[i + 1];
dst[next - 1] = digits[i];
}
/* Add sign. */
if (negative) dst[0] = '-';
return length;
}
在上述算法中,通过使用一个字符串数组,数组中保存的是0-99数字的字符串,每一个数字由两个字符组成,一共200个字符,包括结尾的 NULL TERM字符,一共是201的长度。求某个数字的字符串形式,每次对数字对100取模,得到的是最后两位数字,0-99的范围内,根据数字在数组中查找,直接获取这个0-99范围内的模数的字符串形式,保存到对应的结果中,循环,就能得到 long long 数字的字符串形式了。
/* Convert a string into a long long. Returns 1 if the string could be parsed
* into a (non-overflowing) long long, 0 otherwise. The value will be set to
* the parsed value when appropriate. */
int string2ll(const char *s, size_t slen, long long *value) {
const char *p = s;
size_t plen = 0;
int negative = 0;
unsigned long long v;
if (plen == slen)
return 0;
/* Special case: first and only digit is 0. */
if (slen == 1 && p[0] == '0') {
if (value != NULL) *value = 0;
return 1;
}
if (p[0] == '-') {
negative = 1;
p++; plen++;
/* Abort on only a negative sign. */
if (plen == slen)
return 0;
}
/* First digit should be 1-9, otherwise the string should just be 0. */
if (p[0] >= '1' && p[0] <= '9') {
v = p[0]-'0';
p++; plen++;
} else if (p[0] == '0' && slen == 1) {
*value = 0;
return 1;
} else {
return 0;
}
while (plen < slen && p[0] >= '0' && p[0] <= '9') {
if (v > (ULLONG_MAX / 10)) /* Overflow. */
return 0;
v *= 10;
if (v > (ULLONG_MAX - (p[0]-'0'))) /* Overflow. */
return 0;
v += p[0]-'0';
p++; plen++;
}
/* Return if not all bytes were used. */
/* non digit exist */
if (plen < slen)
return 0;
if (negative) {
if (v > ((unsigned long long)(-(LLONG_MIN+1))+1)) /* Overflow. */
return 0;
if (value != NULL) *value = -v;
} else {
if (v > LLONG_MAX) /* Overflow. */
return 0;
if (value != NULL) *value = v;
}
return 1;
}
参考文献:
Redis 设计与实现,黄健宏著。