滴滴云DC2云服务器预装工具介绍(一)
近期滴滴云DC2服务器做了一次标准镜像的升级,在本次升级中所有版本的系统(CentOS7.3、CentOS6.9、Ubuntu16.04、Ubuntu14.04)都为用户默认安装了一些常用的工具。这些工具主要集中在性能监控、网络分析、系统调试等几个方面。预装这些工具后,开发者友好程度更加明显,省去了用户搜索安装所浪费的时间。接下来我们就结合DC2服务器实例,分篇章来介绍下这些工具的用法。
性能工具
DC2服务器提供了常用的性能监测工具,本篇将介绍这些性能工具的用法
| 性能工具 | 功能介绍 |
|---|---|
| iostat | 监控设备的CPU状态和I/O状态数据等 |
| mpstat | 监控和显示关于CPU的细节信息 |
| vmstat | 监控服务器的CPU使用率,内存使用,虚拟内存交换情况,I/O读写情况 |
| pidstat | 监控全部或指定进程的CPU、内存、线程、设备I/O等系统资源的占用情况 |
| iotop | 监控磁盘I/O情况 |
在具体介绍这些工具的用法之前,我们做一些准备工作:创建DC2服务器,并在DC2服务器上结合实例进行工具用法的介绍。
1. 首先根据DC2服务器创建帮助文档上的步骤, 我们创建一台带EIP的CentOS7.3云服务器,名称为didi-test,该服务器规格为2核、4G内存、40G系统盘。
2. 接着根据EBS云盘创建帮助文档购买一个20G SSD云盘,并且挂载到第1步中的云服务器上。
3. ssh登录到这台服务器上,查看具体的配置信息如下
[dc2-user@10-254-158-32 ~]$ lscpu|grep CPU
CPU op-mode(s): 32-bit, 64-bit
CPU(s): 2
On-line CPU(s) list: 0,1
CPU family: 6
Model name: Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz
CPU MHz: 2394.454
NUMA node0 CPU(s): 0,1
[dc2-user@10-254-158-32 ~]$ free -m
total used free shared buff/cache available
Mem: 3790 91 118 40 3580 3431
Swap: 0 0 0
[dc2-user@10-254-158-32 ~]$ lsblk -l
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 253:0 0 40G 0 disk
vda1 253:1 0 40G 0 part /
vdb 253:16 0 20G 0 disk
vdb1 253:17 0 20G 0 part /dataiostat
iostat 命令针对系统的整体情况进行分析,完成系统磁盘I/O情况和CPU使用情况的监视。下面列出几个常用的用法,如需获得更多用法,请参考iostat帮助文档。
磁盘IO使用情况
iostat -d $interval $count - -d 显示磁盘使用状态;
- $interval 表示监控采样间隔(s)
- $count 表示共监控显示次数
在didi-test服务器上,查看具体的使用示例:
[root@10-254-158-32 ~]# dd if=/dev/zero of=/data/iotest bs=1M count=10000 &
[1] 15291
[root@10-254-158-32 ~]# iostat -d 1 3
Linux 3.10.0-693.21.1.el7.x86_64 (10-254-158-32) 07/08/2018 _x86_64_ (2 CPU)
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 3.54 60.56 43.98 257625 187097
vdb 5.41 5.13 1988.32 21819 8458385
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.00 0.00 0.00 0 0
vdb 181.00 0.00 92248.00 0 92248
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.00 0.00 0.00 0 0
vdb 181.00 0.00 92160.00 0 92160在上述例子中,首先使用dd命令在磁盘vdb所挂载的/data目录上产生了I/O,然后使用iostat查看具体的
磁盘使用情况,每隔1s监控一次,一共监控显示3次。
返回结果中的第一列代表了vda系统盘及vdb数据盘设备。这里每一行就表示各设备的监控信息
对于vdb设备第三行:
- 此时tps列表示每秒181次I/O请求
- kB_read/s列表示每秒从vdb设备读取数据量为0kB,因为此时只有写数据,所以读数据肯定是0。
- kB_wrtn/s列代表每秒写数据量92160kB。
CPU使用情况
iostat -c $interval $count- -c 显示cpu使用情况;
在didi-test服务器上,查看具体的使用示例:
[root@10-254-158-32 ~]# stress -c 1 &
[1] 15471
[root@10-254-158-32 ~]# iostat -c 1 3
Linux 3.10.0-693.21.1.el7.x86_64 (10-254-158-32) 07/08/2018 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.77 0.02 0.61 1.62 0.00 96.98
avg-cpu: %user %nice %system %iowait %steal %idle
49.75 0.00 0.00 0.00 0.00 50.25
avg-cpu: %user %nice %system %iowait %steal %idle
50.00 0.00 0.00 0.00 0.00 50.00在上述例子中,首先使用stress工具使得1个CPU使用率达到100%。因为一共2个CPU,所以总的CPU使用率是在50%。
在返回结果中,可以看下第三行结果:
- %user表示CPU在用户态的使用率,因为stress进程是在用户态执行的,所以此时该值为50%。
- %nice表示改变过优先级的进程占用CPU的时间百分比
- %system表示CPU在内核态的使用率
- %iowait表示CPU用于等待I/O操作占用总时间百分比
- %idle表示CPU空闲率,这里有50%的空闲。
mpstat
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具。其报告CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPU系统里,mpstat不仅能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。下面列出几个常用的用法,如需获得更多用法,请参考mpstat帮助文档。
基本使用
mpstat -P ALL $interval $count- -P 监控哪个CPU,这里是ALL代表所有CPU,可以取值[0, CPU个数-1]中的数字。
- $interval 表示监控采样间隔(s)
- $count 表示一共监控次数
在didi-test服务器上,查看具体的使用示例:
[root@10-254-158-32 ~]# stress -c 1 &
[1] 16007
[root@10-254-158-32 ~]# stress: info: [16007] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
[root@10-254-158-32 ~]# mpstat -P 0 1 2
Linux 3.10.0-693.21.1.el7.x86_64 (10-254-158-32) 07/08/2018 _x86_64_ (2 CPU)
04:29:55 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
04:29:56 PM 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
04:29:57 PM 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00在上述例子中,首先使用stress工具使得1个CPU使用达到100%,接着使用mpstat监控第0号CPU的使用情况,通过返回结果可以看出0号CPU使用率确实达到了100%。
pidstat
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU、内存、I/O等。pidstat首次运行时显示自系统启动开始到首次执行pidstat的各项统计信息,之后运行pidstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。下面列出几个常用的用法,如需获得更多用法,请参考pidstat帮助文档。
无参数执行
pidstat执行pidstat,将输出系统启动后所有活动进程的cpu统计信息
[root@10-254-158-32 ~]# pidstat
Linux 3.10.0-693.21.1.el7.x86_64 (10-254-158-32) 07/08/2018 _x86_64_ (2 CPU)
04:44:17 PM UID PID %usr %system %guest %CPU CPU Command
04:44:17 PM 0 1 0.10 1.50 0.00 1.60 1 systemd
04:44:17 PM 0 7 0.00 0.02 0.00 0.02 0 migration/0
04:44:17 PM 0 9 0.00 0.06 0.00 0.06 1 rcu_sched
04:44:17 PM 0 12 0.00 0.01 0.00 0.01 1 migration/1
04:44:17 PM 0 13 0.06 0.00 0.00 0.06 1 ksoftirqd/1
04:44:17 PM 0 25 0.00 0.12 0.00 0.12 1 kworker/1:1
04:44:17 PM 0 42 0.00 0.01 0.00 0.01 0 kworker/u4:1
04:44:17 PM 0 44 0.00 0.03 0.00 0.03 0 kworker/0:1
04:44:17 PM 0 260 0.00 0.01 0.00 0.01 0 scsi_eh_1
04:44:17 PM 0 276 0.00 0.10 0.00 0.10 0 kworker/0:2
04:44:17 PM 0 293 0.00 0.04 0.00 0.04 1 xfsaild/vda1
04:44:17 PM 0 370 0.05 0.13 0.00 0.17 1 systemd-journal
04:44:17 PM 0 410 0.05 0.01 0.00 0.06 0 systemd-udevd
04:44:17 PM 998 540 0.01 0.01 0.00 0.02 0 polkitd
04:44:17 PM 0 542 0.00 0.01 0.00 0.01 0 irqbalance
04:44:17 PM 0 544 0.05 0.03 0.00 0.08 1 rsyslogd
04:44:17 PM 81 549 0.01 0.00 0.00 0.01 0 dbus-daemon
04:44:17 PM 0 823 0.09 0.05 0.00 0.14 1 tuned
04:44:17 PM 0 936 0.01 0.00 0.00 0.01 0 master
04:44:17 PM 0 10299 0.04 0.01 0.00 0.05 0 sshd
04:44:17 PM 1001 10301 0.00 0.01 0.00 0.01 1 sshd
04:44:17 PM 1001 10302 0.01 0.01 0.00 0.03 1 bash
04:44:17 PM 1001 10325 30.51 0.00 0.00 30.51 0 stress
04:44:17 PM 0 10331 0.00 0.03 0.00 0.03 0 kworker/0:3
04:44:17 PM 0 10333 0.00 0.01 0.00 0.01 1 sudo
04:44:17 PM 0 10349 0.00 0.01 0.00 0.01 1 pidstat指定采样周期和次数
pidstat $interval $count$count可省略,表示不停的循环采样。
在didi-test服务器中,查看具体使用实例:
[root@10-254-158-32 ~]# pidstat 1 2
Linux 3.10.0-693.21.1.el7.x86_64 (10-254-158-32) 07/08/2018 _x86_64_ (2 CPU)
04:47:01 PM UID PID %usr %system %guest %CPU CPU Command
04:47:02 PM 1001 10325 100.00 0.00 0.00 100.00 1 stress
04:47:02 PM 0 10350 0.00 0.99 0.00 0.99 0 pidstat
04:47:02 PM UID PID %usr %system %guest %CPU CPU Command
04:47:03 PM 1001 10325 100.00 0.00 0.00 100.00 1 stress
04:47:03 PM 0 10350 0.00 1.00 0.00 1.00 0 pidstat
Average: UID PID %usr %system %guest %CPU CPU Command
Average: 1001 10325 100.00 0.00 0.00 100.00 - stress
Average: 0 10350 0.00 1.00 0.00 1.00 - pidstat在上面实例中,pidstat以1秒为采样周期,输出2次cpu使用统计信息,最后得到2次的平均值。
其中2次采样,stress进程CPU使用率都是100%,最后得出的平均值也是100%。
查看内存使用情况
pidstat -r -p $pid $interval $count- r表示显示各活动进程的内存使用统计
- p指定特定的进程
- $interval表示采样周期
- $count表示采样次数
在didi-test服务器中,查看具体的使用实例:
[root@10-254-158-32 ~]# cat consume_mem.py
#!/usr/bin/python
import time
test = "test"
while True:
test += test
time.sleep(1)
[root@10-254-158-32 ~]# python consume_mem.py &
[1] 10575
[root@10-254-158-32 ~]# pidstat -r -p 10575 2 10
Linux 3.10.0-693.21.1.el7.x86_64 (10-254-158-32) 07/08/2018 _x86_64_ (2 CPU)
05:47:04 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command
05:47:06 PM 0 10575 48.00 0.00 125832 4984 0.13 python
05:47:08 PM 0 10575 193.00 0.00 126352 5644 0.15 python
05:47:10 PM 0 10575 513.50 0.00 129424 8716 0.22 python
05:47:12 PM 0 10575 518.00 0.00 141712 21004 0.54 python
05:47:14 PM 0 10575 536.00 0.00 190864 70156 1.81 python
05:47:16 PM 0 10575 10508.00 0.00 256400 135692 3.50 python
05:47:18 PM 0 10575 84508.00 0.00 649616 528908 13.63 python
05:47:20 PM 0 10575 123152.00 0.00 1173904 1053196 27.13 python
05:47:22 PM 0 10575 127816.00 0.00 3271060 2120632 54.63 python
05:47:24 PM 0 10575 128707.50 0.00 2222480 2101772 54.15 python
Average: 0 10575 47650.00 0.00 828764 605070 15.59 python在上面例子中,启动了一个消耗内存的python程序,然后通过pidstat对其进行监控,可以看到它的内存使用不断增长。
在返回的结果中:
- minflt/s: 每秒次缺页错误次数(minor page faults),表示虚拟内存地址映射成物理内存地址产生的缺页次数。
- majflt/s: 每秒主缺页错误次数(major page faults),它表示当虚拟内存地址映射成物理内存地址时,相应的页在交换分区中,产生的缺页即是主缺页。
- VSZ: 使用的虚拟内存(以kB为单位)
- RSS: 使用的物理内存(以kB为单位)
- %MEM: 该进程内存使用率
- Command: 对应进程的命令
I/O使用情况统计
pidstat -d -p $pid $interval $count- -d选项,可以查看进程I/O的统计信息。
在didi-test服务器中,查看具体的实例:
[root@10-254-158-32 ~]# dd if=/data/iotest of=/dev/null bs=1M &
[1] 16239
[root@10-254-158-32 ~]# pidstat -d -p 16239 1 5
Linux 3.10.0-693.21.1.el7.x86_64 (10-254-158-32) 07/09/2018 _x86_64_ (2 CPU)
10:21:36 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
10:21:37 AM 0 16239 94208.00 0.00 0.00 dd
10:21:38 AM 0 16239 90112.00 0.00 0.00 dd
10:21:39 AM 0 16239 94208.00 0.00 0.00 dd
10:21:40 AM 0 16239 90112.00 0.00 0.00 dd
10:21:41 AM 0 16239 94208.00 0.00 0.00 dd
Average: 0 16239 92569.60 0.00 0.00 dd在上述例子中,首先使用dd命令在磁盘vdb所挂载的/data目录读取iotest文件,产生了读流量,然后使用pidstat查看具体的I/O情况,每隔1s监控一次,一共监控显示5次。
iotop
iotop命令是一个用来监视磁盘I/O使用状况的top类工具。iotop具有与top相似的UI,其中包括PID、用户、I/O、进程等相关信息。
iotop [options][options] 常用选项如下:
- o:只显示有io操作的进程
- b:批量显示,无交互,主要用作记录到文件。
- n NUM:显示NUM次,主要用于非交互式模式。
- d SEC:间隔SEC秒显示一次。
- p PID:监控的进程pid。
- u USER:监控的进程用户。
在didi-test服务器上,查看具体的使用实例:
[dc2-user@10-254-158-32 root]$ dd if=/data/iotest of=/dev/null bs=1M &
[1] 16496
[dc2-user@10-254-158-32 root]$
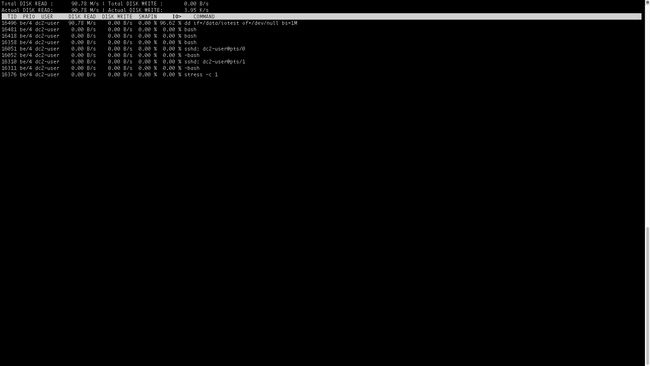
[dc2-user@10-254-158-32 root]$ sudo -i
[root@10-254-158-32 ~]# iotop -u dc2-user首先在dc2-user下启动dd,在磁盘vdb上产生读流量,然后使用-u指定dc2-user用户, iotop查看该用户的I/O情况如下图: