如何在tensorflow中进行FineTuning
本篇博客参考的博客有如下,同时也非常感谢该博主
参考博客
测试所用的代码在我的github上,https://github.com/Alienge/learnFineTuning
由于代码主要涉及一些tensorflow的基本知识,因此注释比较少,有时间我把注释补全
1.主要内容
本篇博客基于tensorflow讲如何用两种方式进行finetuning,并以tensorflow自带的手写数字识别数据进行测试。
两种方式的finetuning按保存类型文件名来区分,分别是ckpt文件和pd文件。ckpt文件在tensorflow中使用使用tf.train.Saver类进行保存。ckpt文件保存了训练网络的全部信息,包括所有的网络图节点和所有的权值数据。在pd文件中使用convert_variable_to_constants(sess,sess.graph_def,['op_name'])保存的训练结果和网络图结构的节点。pd文件保存的内容op_name这个操作之前与之相关连的所有图结构和权值,并且weights是以常量的形式保存因此不需要指定tf.stop_gradient。使用 convert_variables_to_constants进行保存的pd文件, 相比较于ckpt文件会少很多冗余的信息,而且pd文件更小,可移植性也比方便。
2.测试的网络结构
以一个简单的3层的NN网络训练,然后固定前面的2层的weights,再加一层普通网络和softmax网络进行finetuning,下面简要的画下网络的图
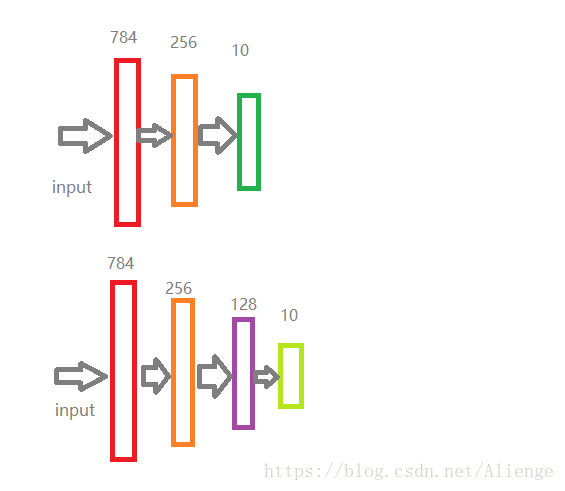
本图使用windows下的画图工具,忽略博主的绘图水平,最好使用viso绘图
图中颜色相同的矩形框表示需要固定住的权重的网络层,上图中的下面一个网络结构是finetuning需要加上的层数。
3.实验代码块
看代码之前介绍代码中的几个部分,方便看代码。代码中函数
def _bias_variable 表示偏置量的设置 def _weight_variable 表示权重的设置 def inference 表示网络的构建 def loss 计算网络的lossfunction def train 训练网络
(恢复网络之前注意一点,对网络图中的操作命名很重要,因为恢复网络的操作节点是按照命名来恢复的)
3.1 ckpt文件保存的网络结构
介绍tf.train.Saver保存的网络
from __future__ import absolute_import from __future__ import division from __future__ import print_function from tensorflow.examples.tutorials.mnist import input_data from datetime import datetime import os mnist = input_data.read_data_sets('MNIST_data',one_hot=True) import tensorflow as tf FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_integer('batch_size',100,'''batch_size''') tf.app.flags.DEFINE_integer('traing_epoches',15,'''epoch''') tf.app.flags.DEFINE_string('check_point_dir','./','check_ponint_dir') def _bias_variable(name,shape,initializer): var = tf.get_variable(name, shape, initializer=initializer, dtype=tf.float32) return var def _weight_variable(name,shape,std): return _bias_variable(name, shape, initializer=tf.truncated_normal_initializer(stddev=std,dtype=tf.float32), ) def inference(x): with tf.variable_scope('layer1') as scope: weights = _weight_variable('weights',[784,256],0.04) bias = _bias_variable('bias',[256],tf.constant_initializer(0.1)) layer1 = tf.nn.relu(tf.matmul(x,weights)+bias,name=scope.name) with tf.variable_scope('layer2') as scope: weights = _weight_variable('weights',[256,128],std=0.02) bias = _bias_variable('bias',[128],tf.constant_initializer(0.2)) layer2 = tf.nn.relu(tf.matmul(layer1,weights)+bias,name=scope.name) with tf.variable_scope('softmax_linear') as scope: weights = _weight_variable('weights',[128,10],std=1/192.0) bias = _bias_variable('bias',[10],tf.constant_initializer(0.0)) softmax_linear = tf.add(tf.matmul(layer2,weights),bias,name=scope.name) return softmax_linear def loss(logits,labels): print(labels.get_shape().as_list()) print(logits.get_shape().as_list()) labels = tf.cast(labels,tf.int64) cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(labels,1),logits=logits,name = 'cross_entropy') cross_entropy_mean = tf.reduce_mean(cross_entropy,name = 'cross_entropy') return cross_entropy_mean def train(): with tf.name_scope("input"): x = tf.placeholder(tf.float32, shape=[None, 784], name='x') y = tf.placeholder(tf.float32, shape=[None, 10], name='y') softmax_linear = inference(x) cost = loss(softmax_linear,y) opt = tf.train.AdamOptimizer(0.001).minimize(cost) correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(softmax_linear, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float')) saver = tf.train.Saver() with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for epoch in range(FLAGS.traing_epoches): avg_cost = 0.0 total_batch = int(mnist.train.num_examples/FLAGS.batch_size) for _ in range(total_batch): batch_xs,batch_ys = mnist.train.next_batch(FLAGS.batch_size) sess.run(opt,feed_dict={x:batch_xs,y:batch_ys}) cost_ = sess.run(cost,feed_dict={x:batch_xs,y:batch_ys}) print(("%s epoch: %d,cost: %.6f")%(datetime.now(),epoch+1,cost_)) if (epoch+1) % 5 == 0: check_point_file = os.path.join(FLAGS.check_point_dir,'my_test_model') saver.save(sess,check_point_file,global_step=epoch+1) mean_accuary = sess.run(accuracy,{x:mnist.test.images,y:mnist.test.labels}) print("accuracy %3.f"%mean_accuary) print() def main(_): train() if __name__ == '__main__': tf.app.run()
与保存网络相关的代码我用红色标出,下面也单独列出来了
saver = tf.train.Saver()
if (epoch+1) % 5 == 0: check_point_file = os.path.join(FLAGS.check_point_dir,'my_test_model') saver.save(sess,check_point_file,global_step=epoch+1)
这两部分的代码是用来保存网络结构和参数的,会生成ckpt的四个文件,我们重点关注meta文件,因为里面存储了所构建的网络图结构。在恢复网络的时候,重点是这个meta文件和ckpt文件,重点看如何恢复网络
from __future__ import absolute_import from __future__ import division from __future__ import print_function from tensorflow.examples.tutorials.mnist import input_data from datetime import datetime import os mnist = input_data.read_data_sets('MNIST_data',one_hot=True) import tensorflow as tf def _bias_variable(name,shape,initializer): var = tf.get_variable(name, shape, initializer=initializer, dtype=tf.float32) return var def _weight_variable(name,shape,std): return _bias_variable(name, shape, initializer=tf.truncated_normal_initializer(stddev=std,dtype=tf.float32), ) def inference(input): with tf.variable_scope('layer3') as scope: weights = _weight_variable('weights',[128,64],std=0.001) bias = _bias_variable('bias',[64],tf.constant_initializer(0.0)) layer3 = tf.nn.relu(tf.matmul(input, weights) + bias, name=scope.name) with tf.variable_scope('softmax_linear') as scope: weights = _weight_variable('weights', [64, 10], std=1 / 192.0) bias = _bias_variable('bias', [10], tf.constant_initializer(0.0)) softmax_linear = tf.add(tf.matmul(layer3, weights), bias, name=scope.name) return softmax_linear def loss(logits,labels): labels = tf.cast(labels,tf.int64) cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(labels,1),logits=logits,name = 'cross_entropy') cross_entropy_mean = tf.reduce_mean(cross_entropy,name = 'cross_entropy') return cross_entropy_mean batch_size = 100 training_epoch = 20 with tf.Graph().as_default() as g: saver = tf.train.import_meta_graph('./my_test_model-15.meta') x_place = g.get_tensor_by_name('input/x:0') y_place = g.get_tensor_by_name('input/y:0') weight_test = g.get_tensor_by_name('layer1/weights:0') layer2 = g.get_tensor_by_name('layer2/layer2:0') layer2 = tf.stop_gradient(layer2,name='stop_gradient') soft_result = inference(layer2) cost = loss(soft_result,y_place) opt = tf.train.AdamOptimizer(0.001).minimize(cost) correct_prediction = tf.equal(tf.argmax(y_place, 1), tf.argmax(soft_result, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float')) with tf.Session(graph=g) as sess: value=[] saver.restore(sess, tf.train.latest_checkpoint('./')) sess.run(tf.global_variables_initializer()) for epoch in range(training_epoch): avg_cost = 0.0 total_batch = int(mnist.train.num_examples / batch_size) for _ in range(total_batch): batch_xs, batch_ys = mnist.train.next_batch(batch_size) sess.run(opt, feed_dict={x_place: batch_xs, y_place: batch_ys}) cost_ = sess.run(cost, feed_dict={x_place: batch_xs, y_place: batch_ys}) weight_test_value = sess.run(weight_test,feed_dict={x_place: batch_xs, y_place: batch_ys}) print(("%s epoch: %d,cost: %.6f") % (datetime.now(), epoch + 1, cost_)) if (epoch+1) % 5 == 0: value.append(weight_test_value) for i in range(len(value)-1): if value[i].all()==value[i+1].all(): print("weight is equal") mean_accuary = sess.run(accuracy, {x_place: mnist.test.images, y_place: mnist.test.labels}) print("accuracy %3.f" % mean_accuary)
恢复网络的图节点请看第一个红色的标注,而恢复权重则看第二段的红色标注
黄色代码部分是我用来测试第二层网络中的weights经过多次迭代后是否固定(不变)
下面单独提出来
saver = tf.train.import_meta_graph('./my_test_model-15.meta') x_place = g.get_tensor_by_name('input/x:0') y_place = g.get_tensor_by_name('input/y:0') weight_test = g.get_tensor_by_name('layer1/weights:0') layer2 = g.get_tensor_by_name('layer2/layer2:0') layer2 = tf.stop_gradient(layer2,name='stop_gradient')
使用tf.train.import_meta_graph来恢复网络,并用g.get_tensor_by_name按照构建原来网络的name来获取每个图节点的操作等,由于ckpt文件中并不是以常量的形式进行保存,在第二段标红位置处把weights加载到我们模型时,我们还需要设置bp的时候,设置tf.stop_gradient不要再往后面再传递梯度了。 而后面的网络搭建按照正常的网络搭建即可
(注意一小点,在恢复某一个节点的时候,其实他前面与之关联的节点都恢复了)
3.2.pb文件保存的网络结构
介绍如何用convert_variables_to_constants保存的pd文件恢复网络
from __future__ import absolute_import from __future__ import division from __future__ import print_function from tensorflow.examples.tutorials.mnist import input_data from datetime import datetime from tensorflow.python.framework.graph_util import convert_variables_to_constants import os mnist = input_data.read_data_sets('MNIST_data',one_hot=True) import tensorflow as tf FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_integer('batch_size',100,'''batch_size''') tf.app.flags.DEFINE_integer('traing_epoches',15,'''epoch''') tf.app.flags.DEFINE_string('check_point_dir','./','check_ponint_dir') def _bias_variable(name,shape,initializer): var = tf.get_variable(name, shape, initializer=initializer, dtype=tf.float32) return var def _weight_variable(name,shape,std): return _bias_variable(name, shape, initializer=tf.truncated_normal_initializer(stddev=std,dtype=tf.float32), ) def inference(x): with tf.variable_scope('layer1') as scope: weights = _weight_variable('weights',[784,256],0.04) bias = _bias_variable('bias',[256],tf.constant_initializer(0.1)) layer1 = tf.nn.relu(tf.matmul(x,weights)+bias,name=scope.name) with tf.variable_scope('layer2') as scope: weights = _weight_variable('weights',[256,128],std=0.02) bias = _bias_variable('bias',[128],tf.constant_initializer(0.2)) layer2 = tf.nn.relu(tf.matmul(layer1,weights)+bias,name=scope.name) with tf.variable_scope('softmax_linear') as scope: weights = _weight_variable('weights',[128,10],std=1/192.0) bias = _bias_variable('bias',[10],tf.constant_initializer(0.0)) softmax_linear = tf.add(tf.matmul(layer2,weights),bias,name=scope.name) return softmax_linear def loss(logits,labels): print(labels.get_shape().as_list()) print(logits.get_shape().as_list()) labels = tf.cast(labels,tf.int64) cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(labels,1),logits=logits,name = 'cross_entropy') cross_entropy_mean = tf.reduce_mean(cross_entropy,name = 'cross_entropy') return cross_entropy_mean def train(): with tf.name_scope("input"): x = tf.placeholder(tf.float32, shape=[None, 784], name='x') y = tf.placeholder(tf.float32, shape=[None, 10], name='y') softmax_linear = inference(x) cost = loss(softmax_linear,y) opt = tf.train.AdamOptimizer(0.001).minimize(cost) correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(softmax_linear, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float')) #saver = tf.train.Saver() with tf.Session() as sess: print(y) sess.run(tf.global_variables_initializer()) for epoch in range(FLAGS.traing_epoches): avg_cost = 0.0 total_batch = int(mnist.train.num_examples/FLAGS.batch_size) for _ in range(total_batch): batch_xs,batch_ys = mnist.train.next_batch(FLAGS.batch_size) sess.run(opt,feed_dict={x:batch_xs,y:batch_ys}) cost_ = sess.run(cost,feed_dict={x:batch_xs,y:batch_ys}) print(("%s epoch: %d,cost: %.6f")%(datetime.now(),epoch+1,cost_)) ''' if (epoch+1) % 5 == 0: check_point_file = os.path.join(FLAGS.check_point_dir,'my_test_model') saver.save(sess,check_point_file,global_step=epoch+1) ''' graph = convert_variables_to_constants(sess,sess.graph_def,['layer2/layer2']) tf.train.write_graph(graph,'.','graph.pb',as_text=False) mean_accuary = sess.run(accuracy,{x:mnist.test.images,y:mnist.test.labels}) print("accuracy %3.f"%mean_accuary) print() def main(_): train() if __name__ == '__main__': tf.app.run()
保存网络和weights很简单,使用
graph = convert_variables_to_constants(sess,sess.graph_def,['layer2/layer2']) tf.train.write_graph(graph,'.','graph.pb',as_text=False)
就可以保存了, 注意和ckpt文件的区别,由于name = "layer2/layer2"节点,因此pd文件中保存了该节点和与该节点之前所有相关的节点的相关操作,并且weights是以常量的形式进行保存的
恢复网络,进行finetuning的时候
from __future__ import absolute_import from __future__ import division from __future__ import print_function from tensorflow.examples.tutorials.mnist import input_data from datetime import datetime import os mnist = input_data.read_data_sets('MNIST_data',one_hot=True) import tensorflow as tf def _bias_variable(name,shape,initializer): var = tf.get_variable(name, shape, initializer=initializer, dtype=tf.float32) return var def _weight_variable(name,shape,std): return _bias_variable(name, shape, initializer=tf.truncated_normal_initializer(stddev=std,dtype=tf.float32), ) def inference(input): with tf.variable_scope('layer3') as scope: weights = _weight_variable('weights',[128,64],std=0.001) bias = _bias_variable('bias',[64],tf.constant_initializer(0.0)) layer3 = tf.nn.relu(tf.matmul(input, weights) + bias, name=scope.name) with tf.variable_scope('softmax_linear') as scope: weights = _weight_variable('weights', [64, 10], std=1 / 192.0) bias = _bias_variable('bias', [10], tf.constant_initializer(0.0)) softmax_linear = tf.add(tf.matmul(layer3, weights), bias, name=scope.name) return softmax_linear def loss(logits,labels): labels = tf.cast(labels,tf.int64) cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(labels,1),logits=logits,name = 'cross_entropy') cross_entropy_mean = tf.reduce_mean(cross_entropy,name = 'cross_entropy') return cross_entropy_mean batch_size = 100 training_epoch = 20 with tf.Graph().as_default() as g: x_place = tf.placeholder(tf.float32, shape=[None, 784], name='x') y_place = tf.placeholder(tf.float32, shape=[None, 10], name='y') with open('./graph.pb','rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) tf.import_graph_def(graph_def, name='') graph_op = tf.import_graph_def(graph_def,name='',input_map={'input/x:0':x_place}, return_elements=['layer2/layer2:0','layer1/weights:0']) # x_place = g.get_tensor_by_name('input/x:0') #y_place = g.get_tensor_by_name('input/y:0') #layer2 = g.get_tensor_by_name('layer2/layer2:0') #weight_test = g.get_tensor_by_name('layer1/weights:0') #layer2 = g.get_tensor_by_name('layer2/layer2:0') #layer2 = tf.stop_gradient(layer2,name='stop_gradient') layer2 = graph_op[0] weight_test = graph_op[1] soft_result = inference(layer2) cost = loss(soft_result,y_place) opt = tf.train.AdamOptimizer(0.001).minimize(cost) correct_prediction = tf.equal(tf.argmax(y_place, 1), tf.argmax(soft_result, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float')) with tf.Session(graph=g) as sess: value=[] #saver.restore(sess, tf.train.latest_checkpoint('./')) sess.run(tf.global_variables_initializer()) #weight_test = sess.g.get_tensor_by_name('layer1/weights:0') for epoch in range(training_epoch): avg_cost = 0.0 total_batch = int(mnist.train.num_examples / batch_size) for _ in range(total_batch): batch_xs, batch_ys = mnist.train.next_batch(batch_size) sess.run(opt, feed_dict={x_place: batch_xs, y_place: batch_ys}) cost_ = sess.run(cost, feed_dict={x_place: batch_xs, y_place: batch_ys}) weight_test_value = sess.run(weight_test,feed_dict={x_place: batch_xs, y_place: batch_ys}) print(("%s epoch: %d,cost: %.6f") % (datetime.now(), epoch + 1, cost_)) if (epoch+1) % 5 == 0: value.append(weight_test_value) for i in range(len(value)-1): if value[i].all()==value[i+1].all(): print("weight is equal") mean_accuary = sess.run(accuracy, {x_place: mnist.test.images, y_place: mnist.test.labels}) print("accuracy %3.f" % mean_accuary)
在恢复网络的时候用到
黄色代码部分是我用来测试第二层网络中的weights经过多次迭代后是否固定(不变)
with open('./graph.pb','rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) tf.import_graph_def(graph_def, name='') graph_op = tf.import_graph_def(graph_def,name='',input_map={'input/x:0':x_place}, return_elements=['layer2/layer2:0','layer1/weights:0'])
注意由于pb文件保存的都是常量,不需要进行tf.stop_gradient, 而且保存下来的只有输入,也即是只有‘input/x:0’,正好我们将重新定义的输入输进去即可得到对应节点,并没有保存‘input/y:0', 后面的网络自己重新搭建即
graph_op = tf.import_graph_def(graph_def,name='',input_map={'input/x:0':x_place}, return_elements=['layer2/layer2:0','layer1/weights:0'])
4.总结
使用tf.train.Saver.save()会保存运行tensorflow程序所需要的全部信息(graph结构,变量值,检查点列表信息),然而有时候并不需要上述所有信息,例如在测试或者离线预测时,其实我们只需要知道如何从神经网络的输入层经过前向传播计算得到输出层即可,而不需要类似变量初始化,模型保存等辅助节点的信息,另外,将变量取值和图的结构分成不同的文件保存有时候也不方便,尤其是当我们需要将训练好的model从一个平台部署到另外一个平台时,例如从PC端部署到android,解决这个问题分为两种情况:
①如果我们已经有了model的分开保存的文件,可以采用tensorflow安装目录./tensorflow/tensorflow/python/tools下的freeze_graph.py脚本提供的方法,将前面保存的cpkt文件和.pb文件(.pbtxt)或者.meta文件统一到一起生成一个单一的文件;