deep learning入门(三)
DL入门(三)powered by @李宏毅
第九课(GAN概念)

1 Basic Idea of GAN
(1) Generator
generator就是一个neural network或者一个function,输入一个vector,输出一个vector。

(2) Discriminator
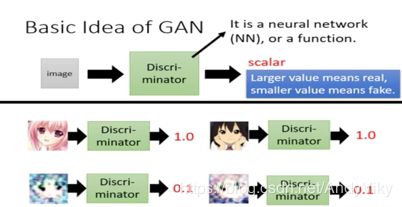
discriminator就是一个neural network或者一个function,输入为一张图片或者一个句子…
输出为一个scalar,scalar越大表示越真实。
(3) 总览
Generator不接触真实数据,Discriminator接触真实数据,第一代的G和D非常弱,可以说是随机生成的,接下来G1开始进化为G2使得D1检测G2的效果下降,D1根据G2同样进行相应的进化(训练)直到对G2达到较好的效果,接下来G和D在不断竞争中进化。

(4) 算法步骤
第一步:初始化Generator和Discriminator
第二步:固定住Generator的参数,update Discriminator的参数
第三步:固定住Discriminator的参数,update Generator的参数
第四步:迭代第二步至第三步

具体步骤:
图中公式表示为:
Learning D:最大化sample出来的真实的m张图片的分数,最小化G产生出来的m张图片的分数。
Learning G:最大化G生成的图片在D中的分数,意味着G必须调整自己的参数使得生成的图片越来越接近真实的图片。

2 GAN as Structured learning
3 Can generator learn by itself?
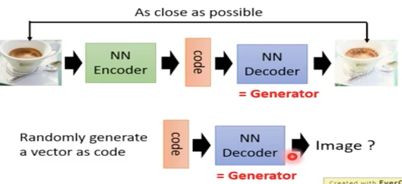
generator完全可以自己训练,generator就相当于auto-encoder中的decoder模块,输入一个vector输出一个图片或者句子等…甚至可以直接拿出decoder模块作为generator。
但是单纯地使用auto-encoder和GAN做对比地话,往往auto-encoder需要更大的neural才能和GAN达到近似的结果。
4 Can Discriminator generator?
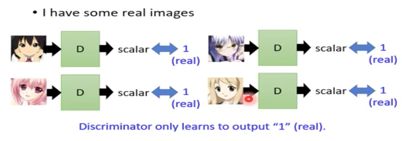
Discriminator自己可以完成产生图片的过程。只要穷举所有的image然后丢到discriminator中并找出得分最高的那张图片(此处假设穷举可以由某种演算法实现)。

但是我们的训练数据全部都是真实的,并没有一些negetive的图片,这样会导致训练出来的discriminitor对全部的图片都打高分的情况。
那么如何得到一批negetive的图片呢?
由下图所示:
第一步:先随机产生图片进行training
第二步:然后经由演算法穷举得出分数较好的图片
第三步:将分数较好的图片替代training中的随机图片继续train
第四步:循环第二到第三步

5 Discriminator vs Generator

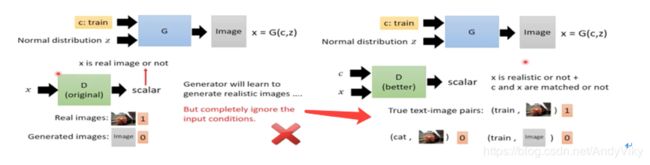
6 Conditional GAN
如图所示:需要做到输入一行文字得到对应的图片,那么需要在训练时给Generator和Discriminator都加上一个输入c(代表了训练集中图片的真实label)。而Discriminitor在评估结果时有三种可能:正确的文字和图片,正确文字和错误的图片,错误的文字和正确的图片,只有第一种时高分,后面两种都是低分。
详细演算法:

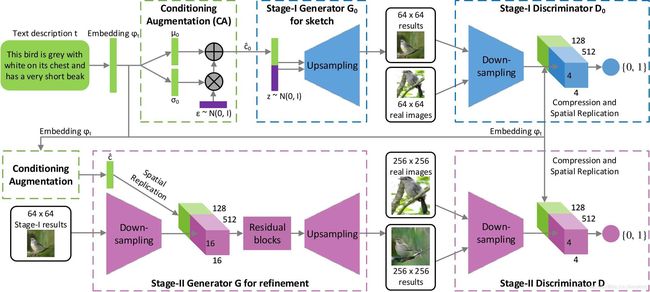
(1) Stack GAN
借鉴: https://blog.csdn.net/a312863063/article/details/83574422
StackGAN本质上就是两个Conditional GAN的堆叠。如果我们没办法一次生成高分辨率又 plausible 的图片,那么可以分两次生成。第一阶段的Conditional GAN利用文本描述提取出的嵌入向量(text embedding)粗略勾画物体主要的形状和颜色,生成低分辨率的图片。第二阶段的对抗生成网络将第一阶段的低分辨率图片和文本描述提取出的嵌入向量(text embedding)作为输入,生成细节丰富的高分辨率图片。
(2) Image to Image
输入为一张图片,输出也为图片。
下图Testing中出现的第一个房子是使用普通NN得出来的,可以看到图片比较模糊;第二个房子是使用普通GAN得出来的,可以看到会多出一些奇怪的东西;第三个是在Generator产生图片的同时最小化和真实数据差距的情况下得出来的,可以看出效果很好也没有出现其他的东西。

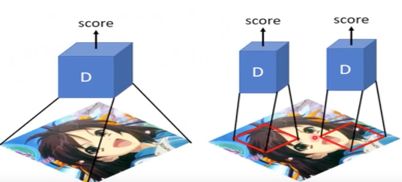
(3) Patch GAN
Discriminator一次只查看一部分的图片。

7 Unsupervised Conditional GAN
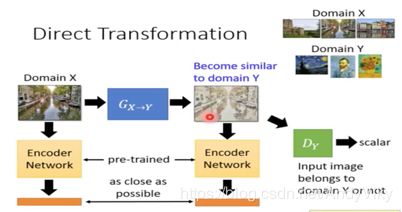
(1) Direct Transformation
由下图所示:将会出现一个问题,当Generator需要骗过Discriminator时只需要输出一张和database中存在差不多的图片即可。但是我们需要的是和输入图片近似的图片。
那么如何解决这个问题呢?

- 忽略这个问题,因为一般的Generator在没有做要求的情况下输入和输出不会相差太大。
- 如下图所示,训练一个encoder,将Generator的输入输出转为向量,并且让这两个向量尽可能的相似。
- Cycle GAN
如下图所示:Cycle GAN的核心思想是训练一个由X->Y的Generator再训练一个由Y->X的Generator,输入一张图得到Y,再将Y作为输入得到X1,我们需要确保X和X1的差异保持尽可能的小。
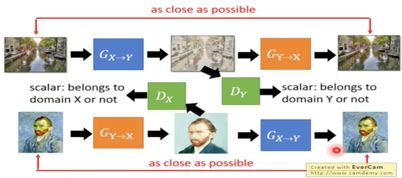
- Star GAN
StarGAN只需要训练一个Generator,输入为inputImage和target domain输出outputImage,再将outputImage加上origin domain作为同一个Generator的输入,输出的Image需要和inputImage尽可能的相似。

example:
先利用Discriminator得出inputImage的origin domain,然后进行Image转换。
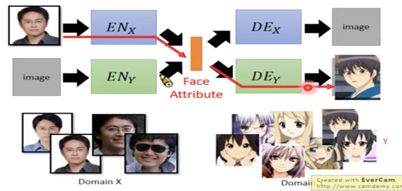
(2) Projection to Common Space
由下图所示:各自训练两个VAE GAN,然后用X的encoder丢到Y的decoder中。
但是由于是各自训练,导致两个model的latent space可能不一样。我们需要使两个encoder的输出都在一个distribution上。
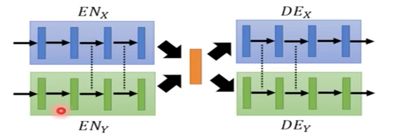
由下图所示:在encdoer中共用后几层的参数,在decoder中共用前几层的参数。
8 Tips For Improving GAN

由上图可知,实际上,PG和Pdata几乎没有重合,那么在没有重合的情况下,JS-divergence计算出来的值永远是log2。
(1) LSGAN(Least Square GAN)
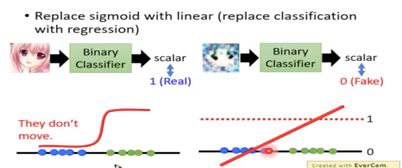
由上图可知,Least Square GAN主要在于将sigmoid函数换成线性函数,使得不会出现在一边特别平坦。
(1) WGAN(Wasserstein GAN)
将原始的Js divergence替换为Earth Mover`s Distance。

由下图所示,可能由很多中方式可以将P拼成Q,那么就需要穷举所有的方法,寻找其中转移量平均值最小的那一个作为Earth Mover Distance。

如下图所示:Wasserstein distance的公式如下,将real-data的分数拉高,generator产生的分数拉低,但是如果没有限制条件,那么将会无限地拉高和拉低。

一:在原始的GAN中,使用的是Weight-clipping的方法防止无限的拉高和拉低,给定限制条件,w的最大值和最小值都被固定。

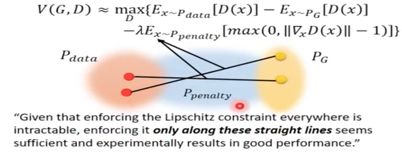
二:类似于Regularization,给V(G, D)加上限制条件,对于所有的x都必须得到D(x)的gradient norm<=1,但是穷举所有的x显然是不可能的,我们将区间缩小到Ppenalty。穷举该区间的x必须使D(x)的gradient norm<=1。

Ppenalty可以是在Pdata和PG中各sample一个点的连线中的任意一点,如下图蓝色区域为Ppenalty。
但是在2018年的有些paper中提到Ppenalty的取值区间应该在Pdata范围内,这样将会得到更好的效果。
三:Spectrum norm
可以保证在任何地方,其gradient norm都是小于等于1的。
9 Feature Extraction
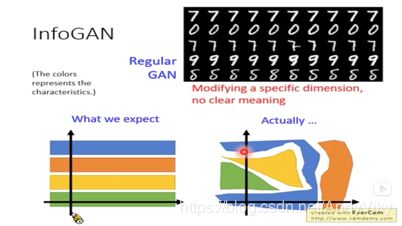
(1) Info GAN
如下图所示:我们往往希望输入的vector的每一维可以控制生成图像的特征,例如第一维代表字体粗细,第二维代表字体颜色…但是实际上训练出来的mode的分布是非常紊乱的。
如下图所示:InfoGAN的目的就在于能够训练处分布规则的model,相比于普通的GAN,InfoGAN增加了一个Classifier,并且将输入切割为两块(c. z`),输入数据到Generator产生X,再将X输入Classifier希望能够反推出c,这样的话就可能会使C带上某种规则,Classifier会学到这种规则快速推出c。
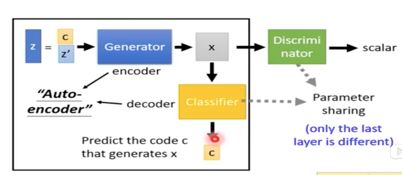
不是因为c本身就带有控制的规则,而是我们希望训练出控制的规则才产生了c。

(2) VAE GAN
VAEGAN的结构图如下图所示。

VAEGAN的演算法。
如下图所示:VAEGAN共有三类的图片(图中表明)。
Encoder的作用:希望缩小真实Image和reconstruct的Image之间的差距,希望真实图片产生的code接近norm distribution。
Decoder的作用:希望缩小真实Image和reconstruct的Image之间的差距,希望产生出来的东西可以骗过Discriminator。
Discriminator的作用:对输入的图片评分。

(3) BiGAN
BiGAN需要分别train一个Encoder和一个Decoder,这两个是分开的,同时还要train一个Discriminator。这个Discriminator的输入为一个Encoder或者Decoder的输入和输出,输出是需要确定输入的值是来自Encoder还是Decoder。

演算法:从数据库中sampleM个图片,利用Encoder得到M个coder。从norm distribution sample M个coder,利用Decoder生成M张图片。输入Discriminator中,当时Encoder时给高分,是Decoder时给低分。

(4) Feature Disentangle(特征分离)
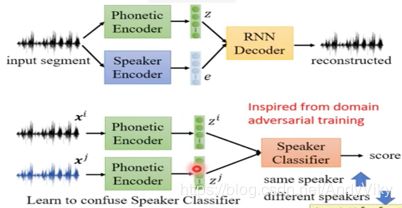
10 Improving Sequence Generation by GAN

(1) RL和Maximum Likelihood的比较

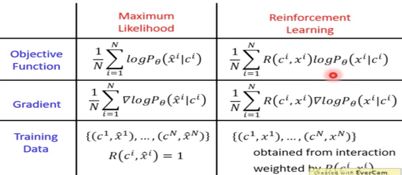
Maximum Likelihood和RL的主要区别在于RL在求gradient的时候都要乘上一个Reward,并且RL中的xi有可能是错误的。
(2) 引入GAN的概念
众所周知,在一般情境中人无法给出所有的正确的reward,所以RL在一般情况下train不起来。
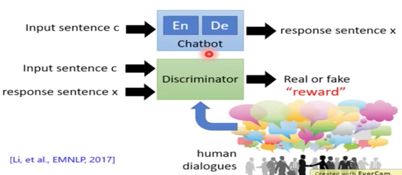
如上图所示,我们需要训练一个Discriminator充当Human的角色,当然一开始这个Discriminator是非常弱的,我们同时也需要去update Discriminator的参数。

演算法如上图所示,和一般的conditional GAN一样。但是有一个问题,我们的Chatbot是一个RNN,即当前轮次都需要考虑前面所得到的结果,那么如何解决呢?我们可以自定义我们的Discriminator架构,例如将input和ouput全部接起来丢入Discriminator得到一个结果等等。

如上图所示在用GAN做text的时候会经过一个sample process,之后将无法进行gradient descent。
1 Gumbel-softmax
核心思想就是想出一个trick使得可以微分。
2 Continue Input for Discriminator
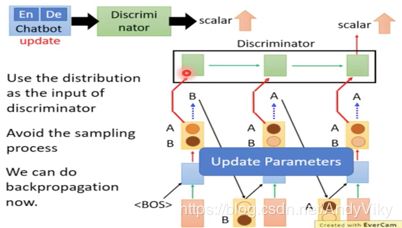
如上图所示,省去sampling process,直接将distribution传给Discriminator。
但是由于输入的是distribution,但是真实的数据都是one-hot的,那么Discriminator很有可能直接学会不管语意不管对错直接将distribution压成one-hot的形式。

(3) Unsupervised Conditional Sequence GAN
1 text style transfer

将语意好的句子转为差的句子等等。
可以使用cycle GAN直接train,只需要把图像转为句子即可。

也可以使用Project to Common Space的方法,把图像转为句子即可。

2 abstractive summarization(摘要总结)
可以使用seq2seq硬train下去,但是至少需要100w份文章和摘要才有可能训练出好的结果。

加上GAN的思想即可以做到unsupervised的training,

思想和cycle GAN一样。
11 Evaluation
如何评估训练出来的GAN model的好坏。
(1) 在传统上使用Likelihood
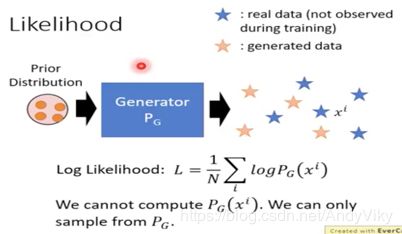
由于使用GAN的时候我们无法通过Generator计算出产生某张特定图片的机率。

由上图所示,我们可以使用Generator产生出一批的数据,然后使用高斯去逼近这些数据,最后叠加形成一个高斯模型,这样我们就可以计算出P(xi)。但是我们不知道使用多少个高斯分布也不知道sample出多少个点…
(2) Objective Evaluation
事先训练好一个Classifier来Evaluation产生出来的结果的好坏,同时还需要检测当前产出的结果是否每个分类都平均。
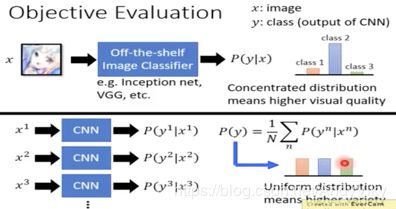

如上图所示,将Generator产出的某张图片丢入Classifier中,得到的distribution中的某个分类的值越大越好。将所有的output丢入Classifier中,得到许多的distribution做平均,每个分类的数值越接近越好。