图像局部特征(七)--SURF原理总结
作者写的非常好。
原文:
http://www.cnblogs.com/ronny/p/4045979.html
如果说SIFT算法中使用DOG对LOG进行了简化,提高了搜索特征点的速度,那么SURF算法则是对DoH的简化与近似。虽然SIFT算法已经被认为是最有效的,也是最常用的特征点提取的算法,但如果不借助于硬件的加速和专用图像处理器的配合,SIFT算法以现有的计算机仍然很难达到实时的程度。对于需要实时运算的场合,如基于特征点匹配的实时目标跟踪系统,每秒要处理8-24帧的图像,需要在毫秒级内完成特征点的搜索、特征矢量生成、特征矢量匹配、目标锁定等工作,这样SIFT算法就很难适应这种需求了。SURF借鉴了SIFT中简化近似的思想,把DoH中的高斯二阶微分模板进行了简化,使得模板对图像的滤波只需要进行几个简单的加减法运算,并且,这种运算与滤波器的尺度无关。实验证明,SURF算法较SIFT在运算速度上要快3倍左右。
1. 积分图像
SURF算法中要用到积分图像的概念。借助积分图像,图像与高斯二阶微分模板的滤波转化为对积分图像的加减运算。
积分图像中任意一点(i,j) (i,j)的值ii(i,j) ii(i,j),为原图像左上角到点(i,j) (i,j)相应的对角线区域灰度值的总和,即
ii(i,j)=∑ r≤i, c≤j p(r,c) ii(i,j)=∑r≤i, c≤jp(r,c)
式中,p(r,c) p(r,c)表示图像中点(r,c) (r,c)的灰度值,ii(i,j) ii(i,j)可以用下面两式迭代计算得到
S(i,j)=S(i,j−1)+p(i,j) S(i,j)=S(i,j−1)+p(i,j)
ii(i,j)=ii(i−1,j)+S(i,j) ii(i,j)=ii(i−1,j)+S(i,j)
式中,S(i,j) S(i,j)表示一列的积分,且S(i,−1)=0,ii(−1,j)=0 S(i,−1)=0,ii(−1,j)=0。求积分图像,只需要对原图像所有像素进行一遍扫描。
OpenCV中提供了用于计算积分图像的接口
/*
* src :输入图像,大小为M*N
* sum: 输出的积分图像,大小为(M+1)*(N+1)
* sdepth:用于指定sum的类型,-1表示与src类型一致
*/
void integral(InputArray src, OutputArray sum, int sdepth = -1);值得注意的是OpenCV里的积分图大小比原图像多一行一列,那是因为OpenCV中积分图的计算公式为:
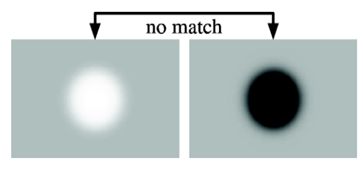
ii(i,j)=∑ r<i, c<j p(r,c) ii(i,j)=∑r 一旦积分图计算好了,计算图像内任何矩形区域的像素值的和只需要三个加法,如上图所示。 在斑点检测这篇文章中已经提到过,我们可以利用Hessian矩阵行列式的极大值检测斑点。下面我们给出Hessian矩阵的定义。 给定图像I I中的一个点x(i,j) x(i,j),在点x x处,尺度为σ σ的Hessian矩阵H(x,σ) H(x,σ)定义如下: H(x,σ)=[L xx (x,σ)L xy (x,σ) L xy (x,σ)L yy (x,σ) ] H(x,σ)=[Lxx(x,σ)Lxy(x,σ)Lxy(x,σ)Lyy(x,σ)] 式中,L xx (x,σ) Lxx(x,σ)是高斯二阶微分∂ 2 g(σ)∂x 2 ∂2g(σ)∂x2在点x x处与图像I I的卷积,L x,y (x,σ) Lx,y(x,σ)和L yy (x,σ) Lyy(x,σ)具有类似的含义。 下面显示的是上面三种高斯微分算子的图形。 但是利用Hessian行列式进行图像斑点检测时,有一个缺点。由于二阶高斯微分被离散化和裁剪的原因,导致了图像在旋转奇数倍的π/4 π/4时,即转换到模板的对角线方向时,特征点检测的重复性降低(也就是说,原来特征点的地方,可能检测不到特征点了)。而在π/2 π/2时,特征点检测的重现率真最高。但这一小小的不足不影响我们使用Hessian矩阵进行特征点的检测。 为了将模板与图产像的卷积转换为盒子滤波运算,我们需要对高斯二阶微分模板进行简化,使得简化后的模板只是由几个矩形区域组成,矩形区域内填充同一值,如下图所示,在简化模板中白色区域的值为正数,黑色区域的值为负数,灰度区域的值为0。 对于σ=1.2 σ=1.2的高斯二阶微分滤波器,我们设定模板的尺寸为9×9 9×9的大小,并用它作为最小尺度空间值对图像进行滤波和斑点检测。我们使用D xx 、D xy Dxx、Dxy和D yy Dyy表示模板与图像进行卷积的结果。这样,便可以将Hessian矩阵的行列式作如下的简化。 Det(H)=L xx L yy –L xy L xy =D xx L xx D xx D yy L yy D yy −D xy L xy D xy D xy L xy D xy ≈D xx D yy –(wD xy ) 2 Det(H)=LxxLyy–LxyLxy=DxxLxxDxxDyyLyyDyy−DxyLxyDxyDxyLxyDxy≈DxxDyy–(wDxy)2 滤波器响应的相关权重w w是为了平衡Hessian行列式的表示式。这是为了保持高斯核与近似高斯核的一致性。 w=|L xy (σ)| F |D xx (σ) F ||L xx (σ)| F |D xy (σ) F | =0.912 w=|Lxy(σ)|F|Dxx(σ)F||Lxx(σ)|F|Dxy(σ)F|=0.912 其中|X| F |X|F为Frobenius范数。理论上来说对于不同的σ σ的值和对应尺寸的模板尺寸,w w值是不同的,但为了简化起见,可以认为它是同一个常数。 使用近似的Hessian矩阵行列式来表示图像中某一点x x处的斑点响应值,遍历图像中所有的像元点,便形成了在某一尺度下琉璃点检测的响应图像。使用不同的模板尺寸,便形成了多尺度斑点响应的金字塔图像,利用这一金字塔图像,就可以进行斑点响应极值点的搜索,其过程完全与SIFT算法类同。 通常想要获取不同尺度的斑点,必须建立图像的尺度空间金字塔。一般的方法是通过不同σ σ的高斯函数,对图像进行平滑滤波,然后重采样图像以获得更高一层的金字塔图像。SIFT特征检测算法中就是通过相邻两层图像金字塔相减得到DoG图像,然后再在DoG图像上进行斑点和边缘检测工作的。 由于采用了盒子滤波和积分图像,所以,我们并不需要像SIFT算法那样去直接建立图像金字塔,而是采用不断增大盒子滤波模板的尺寸的间接方法。通过不同尺寸盒子滤波模板与积分图像求取Hessian矩阵行列式的响应图像。然后在响应图像上采用3D非最大值抑制,求取各种不同尺度的斑点。 如前所述,我们使用9×9 9×9的模板对图像进行滤波,其结果作为最初始的尺度空间层(此时,尺度值为s=1.2,近似σ=1.2 σ=1.2的高斯微分),后续的层将通过逐步放大滤波模板尺寸,以及放大后的模板不断与图像进行滤波得到。由于采用盒子滤波和积分图像,滤波过程并不随着滤波模板尺寸的增加而使运算工作量增加。 与SIFT算法类似,我们需要将尺度空间划分为若干组(Octaves)。一个组代表了逐步放大的滤波模板对同一输入图像进行滤波的一系列响应图。每个组又由若干固定的层组成。由于积分图像离散化的原因,两个层之间的最小尺度变化量是由高斯二阶微分滤波器在微分方向上对正负斑点响应长度l 0 l0决定的,它是盒子滤波器模板尺寸的1/3 1/3。对于9×9 9×9的模板,它的l 0 =3 l0=3。一下层的响应长度至少应该在l 0 l0的基础上增加2个像素,以保证一边一个像素,即l 0 =5 l0=5。这样模板的尺寸就为15×15 15×15。以此类推,我们可以得到一个尺寸增大模板序列,它们的尺寸分别为:9×9,15×15,21×21,27×27 9×9,15×15,21×21,27×27,黑色、白色区域的长度增加偶数个像素,以保证一个中心像素的存在。 采用类似的方法来处理其他几组的模板序列。其方法是将滤波器尺寸增加量翻倍(6,12,24,38)。这样,可以得到第二组的滤波器尺寸,它们分别为15,27,39,51。第三组的滤波器尺寸为27,51,75,99。如果原始图像的尺寸仍然大于对应的滤波器尺寸,尺度空间的分析还可以进行第四组,其对应的模板尺寸分别为51,99,147和195。下图显示了第一组至第三组的滤波器尺寸变化。 在通常尺度分析情况下,随着尺度的增大,被检测到的斑点数量迅速衰减。所以一般进行3-4组就可以了,与此同时,为了减少运算量,提高计算的速度,可以考虑在滤波时,将采样间隔设为2。 对于尺寸为L的模板,当用它与积分图运算来近似二维高斯核的滤波时,对应的二维高斯核的参数σ=1.2×L9 σ=1.2×L9,这一点至关重要,尤其是在后面计算描述子时,用于计算邻域的半径时。 为了在图像及不同尺寸中定位兴趣点,我们用了3×3×3 3×3×3邻域非最大值抑制。具体的步骤基本与SIFT一致,而且Hessian矩阵行列式的最大值在尺度和图像空间被插值。 下面显示了我们用的快速Hessian检测子检测到的兴趣点。 这份源码来自OpenCV nonfree模块。 这里先介绍SURF特征点定位这一块,关于特征点的描述下一篇文章再介绍。 特征点定位的主干函数为fastHessianDetector,该函数接受一个积分图像,以及尺寸相关的参数,组数与每组的层数,检测到的特征点保存在vector 这个函数首先定义了尺寸为9的第一层图像的三个模板。模板分别为一个3×5 3×5、3×5 3×5、4×5 4×5的二维数组表示,数组的每一行表示一个黑白块的位置参数。函数里只初始化了第一层图像的模板参数,后面其他组其他层的Harr模板参数都是用resizeHaarPattern这个函数来计算的。这个函数返回的是一个SurfHF的结构体,这个结构体由两个点及一个权重构成。 resizeHaarPattern这个函数非常的巧妙,它把模板中的点坐标。转换到在积分图中的相对(模板左上角点)坐标。 在用积分图计算近似卷积时,用的是calcHaarPattern函数。这个函数比较简单,只用知道左上与右下角坐标即可。 最终我们可以看到了整个calcLayerDetAndTrack的代码 这里算法思路很简单,值得注意的是里面的一些坐标的转换很巧妙,里面比较重的函数就是interpolateKeypoint函数,通过插值计算最大值点。 总体来说,如果理解了SIFT算法,再来看SURF算法会发现思路非常简单。尤其是局部最大值查找方面,基本一致。关键还是一个用积分图来简化卷积的思路,以及怎么用不同的模板来近似原来尺度空间中的高斯滤波器。 定位篇: http://www.cnblogs.com/ronny/p/4048213.html 总体来说算法思路和SIFT相似,只是每一步都做了不同程度的近似与简化,提高了效率。 为了保证特征矢量具有旋转不变性,与SIFT特征一样,需要对每个特征点分配一个主方向。为些,我们需要以特征点为中心,以6s 6s(s=1.2∗L/9 s=1.2∗L/9为特征点的尺度)为半径的圆形区域,对图像进行Haar小波响应运算。这样做实际就是对图像进行梯度运算只不过是我们需要利用积分图像,提高计算图像梯度的效率。在SIFT特征描述子中我们在求取特征点主方向时,以是特征点为中心,在以4.5σ σ为半径的邻域内计算梯度方向直方图。事实上,两种方法在求取特征点主方向时,考虑到Haar小波的模板带宽,实际计算梯度的图像区域是相同的。用于计算梯度的Harr小波的尺度为4s。 与SIFT类似,使用σ=2s σ=2s的高斯加权函数对Harr小波的响应值进行高斯加权。为了求取主方向值,需要设计一个以特征点为中心,张角为π/3 π/3的扇形滑动窗口。以步长为0.2弧度左右,旋转这个滑动窗口,并对滑动窗口内的图像Harr小波响应值dx、dy进行累加,得到一个矢量(m w ,θ w ) (mw,θw): m w =∑ w dx+∑ w dy mw=∑wdx+∑wdy θ w =arctan(∑ w dx/∑ w dy) θw=arctan(∑wdx/∑wdy) 主方向为最大Harr响应累加值所对应的方向,也就是最长矢量所对应的方向,即 θ=θ w |max{m w } θ=θw|max{mw} 可以依照SIFT求方方向时策略,当存在另一个相当于主峰值80%能量的峰值时,则将这个方向认为是该特征点的辅方向。一个特征点可能会被指定具有多个方向(一个主方向,一个以上辅方向),这可以增强匹配的鲁棒性。和SIFT的描述子类似,如果在m w mw中出现另一个大于主峰能量max{m w }80 max{mw}80时的次峰,可以将该特征点复制成两个特征点。一个主的方向为最大响应能量所对应的方向,另一个主方向为次大响应能量所对应的方向。 图 1 求取主方向时扇形滑动窗口围绕特征点转动,统计Haar小波响应值,并计算方向角 生成特征点描述子与确定特征点方向有些类似,它需要计算图像的Haar小波响应。不过,与主方向的确定不同的是,这次我们不是使用一个圆形区域,而是在一个矩形区域来计算Haar小波响应。以特征点为中心,沿上一节讨论得到的主方向,沿主方向将s20s×20s s20s×20s的图像划分为4×4 4×4个子块,每个子块利用尺寸2s 2s的Harr模板进行响应值进行响应值计算,然后对响应值进行统计∑dx ∑dx、∑|dx| ∑|dx|、∑dy ∑dy、∑|dy| ∑|dy|形成特征矢量。如下图2所示。图中,以特征点为中心,以20s为边长的矩形窗口为特征描述子计算使用的窗口,特征点到矩形边框的线段表示特征点的主方向。 图2 特征描述子表示 将20s 20s的窗口划分成4×4 4×4子窗口,每个子窗口有5s×5s 5s×5s个像素。使用尺寸为2s 2s的Harr小波对子窗口图像进行其响应值计算,共进行25次采样,分别得到沿主方向的dy和垂直于主方向的dx。然后,以特征点为中心,对dy和dx进行高斯加权计算,高斯核的参数为σ=3.3s(即20s/6) σ=3.3s(即20s/6)。最后,分别对每个子块的响应值进行统计,得到每个子块的矢量: V 子块 =[∑dx,∑|dx|,∑dy,∑|dy|] V子块=[∑dx,∑|dx|,∑dy,∑|dy|] 由于共有4×4 4×4个子块,因此,特征描述子共由4×4×4=64 4×4×4=64维特征矢量组成。SURF描述子不仅具有尺度和旋转不变性,而且对光照的变化也具有不变性。使小波响应本身就具有亮度不变性,而对比度的不变性则是通过将特征矢量进行归一化来实现。图3 给出了三种不同图像模式的子块得到的不同结果。对于实际图像的描述子,我们可以认为它们是由这三种不同模式图像的描述子组合而成的。 图3 不同的图像密度模式得到的不同的描述子结果 为了充分利用积分图像进行Haar小波的响应计算,我们并不直接旋转Haar小波模板求得其响应值,而是在积图像上先使用水平和垂直的Haar模板求得响应值dy和dx,然后根据主方向旋转dx和dy与主方向操持一致,如下图4所示。为了求得旋转后Haar小波响应值,首先要得到旋转前图像的位置。旋转前后图偈的位置关系,可以通过点的旋转公式得到: x=x 0 –j×scale×sin(θ)+i×scale×cos(θ) x=x0–j×scale×sin(θ)+i×scale×cos(θ) y=y 0 –j×scale×cos(θ)+i×scale×sin(θ) y=y0–j×scale×cos(θ)+i×scale×sin(θ) 在得到点(j,i) (j,i)在旋转前对应积分图像的位置(x,y) (x,y)后,利用积分图像与水平、垂直Harr小波,求得水平与垂直两个方向的响应值dx和dy。对dx和dy进行高斯加权处理,并根据主方向的角度,对dx和dy进行旋转变换,从而,得到旋转后的dx’和dy’。其计算公式如下: dx ′ =w(−dx×sin(θ)+dy×cos(θ)) dx′=w(−dx×sin(θ)+dy×cos(θ)) dy ′ =w(−dx×cos(θ)+dy×sin(θ)) dy′=w(−dx×cos(θ)+dy×sin(θ)) 图4 利用积分图像进行Haar小波响应计算示意图,左边为旋转后的图像,右边为旋转前的图像 一般而言,特征矢量的长度越长,特征矢量所承载的信息量就越大,特征描述子的独特性就越好,但匹配时所付出的时间代价就越大。对于SURF描述子,可以将它扩展到用128维矢量来表示。具体方法是在求∑dx ∑dx、∑|dx| ∑|dx|时区分dy<0 dy<0和dy≥0 dy≥0情况。同时,在求取∑dy ∑dy、∑|dy| ∑|dy|时区分dx<0 dx<0和dx≥0 dx≥0情况。这样,每个子块就产生了8个梯度统计值,从而使描述子特征矢量的长度增加到8×4×4=128 8×4×4=128维。 为了实现快速匹配,SURF在特征矢量中增加了一个新的变量,即特征点的拉普拉斯响应正负号。在特征点检测时,将Hessian矩阵的迹的正负号记录下来,作为特征矢量中的一个变量。这样做并不增加运算量,因为特征点检测进已经对Hessian矩阵的迹进行了计算。在特征匹配时,这个变量可以有效地节省搜索的时间,因为只有两个具有相同正负号的特征点才有可能匹配,对于正负号不同的特征点就不进行相似性计算。 简单地说,我们可以根据特征点的响应值符号,将特征点分成两组,一组是具有拉普拉斯正响应的特征点,一组是具有拉普拉斯负响应的特征点,匹配时,只有符号相同组中的特征点才能进行相互匹配。显然,这样可以节省特征点匹配的时间。如下图5所示。 图5 黑背景下的亮斑和白背景下的黑斑 因为它们的拉普拉斯响应正负号不同,不会对它们进行匹配 特征点描述子的生成这一部分的代码主要是通过SURFInvoker这个类来实现。在主流程中,通过一个parallel_for_()函数来并发计算。 实际上有文献指出,SURF比SIFT工作更出色。他们认为主要是因为SURF在求取描述子特征矢量时,是对一个子块的梯度信息进行求和,而SIFT则是依靠单个像素梯度的方向。 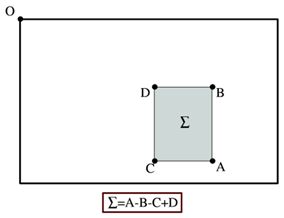
2. DoH近似

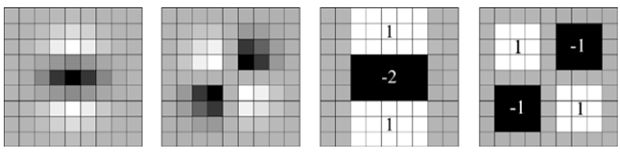
3. 尺度空间表示
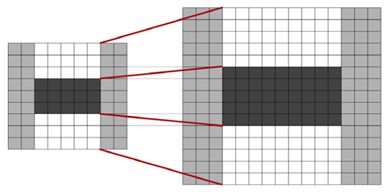

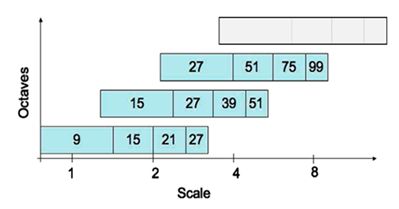
4. 兴趣点的定位
5. SURF源码解析
5.1 主干函数 fastHessianDetector
![]()
static void fastHessianDetector(const Mat& sum, const Mat& msum, vector![]()
5.2 计算Hessian矩阵的行列式与迹calcLayerDetAndTrace
![]()
struct SurfHF
{
int p0, p1, p2, p3;
float w;
SurfHF() : p0(0), p1(0), p2(0), p3(0), w(0) {}
};![]()
![]()
static void
resizeHaarPattern(const int src[][5], SurfHF* dst, int n, int oldSize, int newSize, int widthStep)
{
float ratio = (float)newSize / oldSize;
for (int k = 0; k < n; k++)
{
int dx1 = cvRound(ratio*src[k][0]);
int dy1 = cvRound(ratio*src[k][1]);
int dx2 = cvRound(ratio*src[k][2]);
int dy2 = cvRound(ratio*src[k][3]);
/*巧妙的坐标转换*/
dst[k].p0 = dy1*widthStep + dx1; // 转换为一个相对距离,距离模板左上角点的 在积分图中的距离 !!important!!
dst[k].p1 = dy2*widthStep + dx1;
dst[k].p2 = dy1*widthStep + dx2;
dst[k].p3 = dy2*widthStep + dx2;
dst[k].w = src[k][4] / ((float)(dx2 - dx1)*(dy2 - dy1));// 原来的+1,+2用 覆盖的所有像素点平均。
}
}![]()
![]()
inline float calcHaarPattern(const int* origin, const SurfHF* f, int n)
{
/*orgin即为积分图,n为模板中 黑白 块的个数 */
double d = 0;
for (int k = 0; k < n; k++)
d += (origin[f[k].p0] + origin[f[k].p3] - origin[f[k].p1] - origin[f[k].p2])*f[k].w;
return (float)d;
}![]()
![]()
static void calcLayerDetAndTrace(const Mat& sum, int size, int sampleStep,
Mat& det, Mat& trace)
{
const int NX = 3, NY = 3, NXY = 4;
const int dx_s[NX][5] = { { 0, 2, 3, 7, 1 }, { 3, 2, 6, 7, -2 }, { 6, 2, 9, 7, 1 } };
const int dy_s[NY][5] = { { 2, 0, 7, 3, 1 }, { 2, 3, 7, 6, -2 }, { 2, 6, 7, 9, 1 } };
const int dxy_s[NXY][5] = { { 1, 1, 4, 4, 1 }, { 5, 1, 8, 4, -1 }, { 1, 5, 4, 8, -1 }, { 5, 5, 8, 8, 1 } };
SurfHF Dx[NX], Dy[NY], Dxy[NXY];
if (size > sum.rows - 1 || size > sum.cols - 1)
return;
resizeHaarPattern(dx_s, Dx, NX, 9, size, sum.cols);
resizeHaarPattern(dy_s, Dy, NY, 9, size, sum.cols);
resizeHaarPattern(dxy_s, Dxy, NXY, 9, size, sum.cols);
/* The integral image 'sum' is one pixel bigger than the source image */
int samples_i = 1 + (sum.rows - 1 - size) / sampleStep; // 最大能遍历到的 行坐标,因为要减掉一个模板的尺寸
int samples_j = 1 + (sum.cols - 1 - size) / sampleStep; // 最大能遍历到的 列坐标
/* Ignore pixels where some of the kernel is outside the image */
int margin = (size / 2) / sampleStep;
for (int i = 0; i < samples_i; i++)
{
/*坐标为(i,j)的点是模板左上角的点,所以实际现在模板分析是的i+margin,j+margin点处的响应*/
const int* sum_ptr = sum.ptr![]()
5.3 局部最大值搜索findMaximaInLayer
![]()
/*
* Maxima location interpolation as described in "Invariant Features from
* Interest Point Groups" by Matthew Brown and David Lowe. This is performed by
* fitting a 3D quadratic to a set of neighbouring samples.
*
* The gradient vector and Hessian matrix at the initial keypoint location are
* approximated using central differences. The linear system Ax = b is then
* solved, where A is the Hessian, b is the negative gradient, and x is the
* offset of the interpolated maxima coordinates from the initial estimate.
* This is equivalent to an iteration of Netwon's optimisation algorithm.
*
* N9 contains the samples in the 3x3x3 neighbourhood of the maxima
* dx is the sampling step in x
* dy is the sampling step in y
* ds is the sampling step in size
* point contains the keypoint coordinates and scale to be modified
*
* Return value is 1 if interpolation was successful, 0 on failure.
*/
static int
interpolateKeypoint(float N9[3][9], int dx, int dy, int ds, KeyPoint& kpt)
{
Vec3f b(-(N9[1][5] - N9[1][3]) / 2, // Negative 1st deriv with respect to x
-(N9[1][7] - N9[1][1]) / 2, // Negative 1st deriv with respect to y
-(N9[2][4] - N9[0][4]) / 2); // Negative 1st deriv with respect to s
Matx33f A(
N9[1][3] - 2 * N9[1][4] + N9[1][5], // 2nd deriv x, x
(N9[1][8] - N9[1][6] - N9[1][2] + N9[1][0]) / 4, // 2nd deriv x, y
(N9[2][5] - N9[2][3] - N9[0][5] + N9[0][3]) / 4, // 2nd deriv x, s
(N9[1][8] - N9[1][6] - N9[1][2] + N9[1][0]) / 4, // 2nd deriv x, y
N9[1][1] - 2 * N9[1][4] + N9[1][7], // 2nd deriv y, y
(N9[2][7] - N9[2][1] - N9[0][7] + N9[0][1]) / 4, // 2nd deriv y, s
(N9[2][5] - N9[2][3] - N9[0][5] + N9[0][3]) / 4, // 2nd deriv x, s
(N9[2][7] - N9[2][1] - N9[0][7] + N9[0][1]) / 4, // 2nd deriv y, s
N9[0][4] - 2 * N9[1][4] + N9[2][4]); // 2nd deriv s, s
Vec3f x = A.solve(b, DECOMP_LU);
bool ok = (x[0] != 0 || x[1] != 0 || x[2] != 0) &&
std::abs(x[0]) <= 1 && std::abs(x[1]) <= 1 && std::abs(x[2]) <= 1;
if (ok)
{
kpt.pt.x += x[0] * dx;
kpt.pt.y += x[1] * dy;
kpt.size = (float)cvRound(kpt.size + x[2] * ds);
}
return ok;
}
static void findMaximaInLayer(const Mat& sum, const Mat& mask_sum,
const vector![]()
6. 总结
1. SURF特征点方向分配
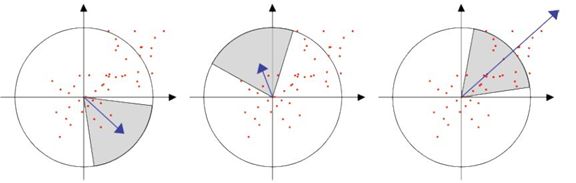
2. 特征点特征矢量生成
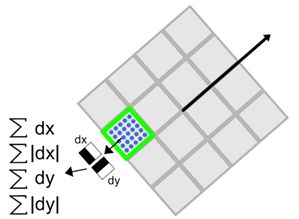
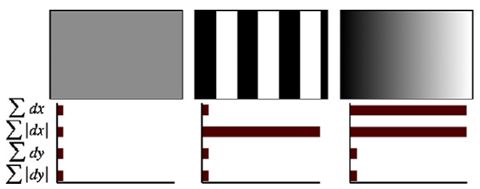

3. 特征描述子的维数
4. 源码解析
![]()
struct SURFInvoker
{
enum{ORI_RADIUS = 6, ORI_WIN = 60, PATCH_SZ = 20};
// Parameters
const Mat* img;
const Mat* sum;
vector![]()
5. 总结