Oracle基础(二)
表查询
1.单表查询
1.1,基本查询语法:
select [all | distinct] [selec_column | *] from table_name
[where search_condition]
[group by columns]
[having search_condition]
[order by column [asc | desc]]
[all | distinct]:用于标识查询结果集中相同数据的处理方式,all关键字表示显示查询到的所有数据,包括重复的行;distinct 关键字表示查询数据中的重复行只显示一次。
[where search_condition]:指定插叙的条件,只有符合条件的数据才会被查询出来
[group by columns]:用于设置分组查询的列
[having search_condition]:用于设置分组的条件,须要与group by 语句结合使用
[order by column [asc | desc]]:用于指定结果集的排序方式,asc为升序,desc为降序,默认为升序。
如果希望查询的结果集为表中的所有数据,则应查询的列设为"*".
例子:
select empno,ename,job from emp;
select *from emp;
1.2,条件查询
当查询语句中需要用到多个条件的时候,条件之间用和或或进行连接
例子:select * from emp,其中sal> 2000,sal <3000;
select * from emp其中sal在2000到3000之间;
1.3,模糊查询
在实际应用中如果不能完全确定查询条件,但是又了解这些条件的特征,就可以通过模糊查询来解决问题,模糊查询可以查询所具备特定的数据。在哪里子句中可以使用喜欢或不喜欢编写模糊查询条件。实现模糊查询需要用到两个通配符,分别为“%”,“_”。
“%”:表示一个一个或多个任意字符。
“_“:表示一个任意字符
示例:


1.4,排序查询
通过可以将查询的结果按照升序或者降序进行排列。

1.5,分组查询
分组操作可以使用group by by子句实现,group by用于指定分组的列,具有用于指定分组的条件

一般情况下,分组查询要结合甲骨文系统函数进行使用
--- AVG()
- - 太阳()
--- MAX()
---分钟()
--- count()总数
2,子查询与多表查询
2.1,单行子查询
如果某个操作希望依赖于另一个选择语句的查询结果,那么就可以在这个操作中嵌入选择语句,当查询操作中嵌入了选择语句后,就形成了一个子查询。
从emp2中选择mgr,其中ename ='FORD'; 相当于X;
select * from emp2,其中empno = x;
两句整合

2.2,多行子查询
2.2.1,使用在运算符查询只要字段的值与子查询结果中的某一值匹配成功,字段的值所在的行就会被查询出来。
select * from emp2 where deptno in(选择deptno来自emp2,其中dname!='SALES');

2.2.2,使用任何运算符查询
使用任何运算符可以将字段的值与子查询结果进行匹配,只要字段的值匹配上子查询中的任意一个结果条件就会被查询出来。
查询EMP2表中工资高于30号部门任意一个员工的其他部门的员工信息。
select * from emp2 where deptno!= 30 and sal> any(从emp2中选择sal,其中deptno = 30);

任何与在的区别在于,任何只能与比较运算符结合使用,在只能单独使用而。
2.2.3,使用的所有运算符查询
查询EMP2表中工资高于20号部门所有员工的其他部门的员工信息
select * from emp2 where deptno!= 20 and sal> all(从emp2中选择sal,其中deptno = 20);

3,关联子查询
在一些特殊需求的子查询操作中,子查询需要借助于主查询,而主查询又离不开子查询的支持,这种主查询与子查询相关联的情况称为关联子查询。
查询EMP2表中工资大于同等工作平均工资的员工信息,
从emp中选择*;
选择工作,按工作分组从emp组中选择avg(sal); Ë
选择* from emp as e where sal>(从emp中选择avg(sal),其中job = e.job)

如图4所示,多表查询
需要多张表进行查询操作,
4.1,笛卡尔积
笛卡尔积指的是将多张表中的数据做乘积运算而产生的冗余结果集,笛卡尔积出现的原因很多,一般是在多表查询中缺失表连接的条件或者连接条件不足造成的
- 查询EMP2表与部门表中的数据
![]()
4.2,多表连接查询
查询EMP2表与部门表中的数据

5,自连接查询
某些表可能会拥有自引用式外键,自引用式外键指的是表中的某一列可以作为该表主键的外键

3.3 外连接查询与分页查询
3.3.1 联合查询
1.UNION操作符
通过UNION操作符可以将两个或多个查询结果组成一个结果集,UNION ALL 表示显示重复的数据行,而UNION 操作符默认的
情况下会删除结果集中的重复行。


2.INTERSECT操作符
INTERECT 指的是交集,通过改操作符可以获取两个查询结果集的共有数据

3.MINUS操作符
MINUS指的是差集,通过该操作符可以获取第一个查询结果集减去第二个查询结果集剩余的数据

3.3.2外连接查询
获取两张表对应列不匹配的行进行则需要使用外连接来实现。
语法:
SELECT column1,column2,...FROM table_name1 {LEFT | RIGHT | FULL} [OUTER] JOIN table2 ON condition
(1)左外连接:获取两张表中对应列匹配的数据行,以及JOIN关键字左边表中不匹配的数据行。
(2)右外连接:获取两张表中对应列匹配的数据行,以及JOIN关键字右边表中不匹配的数据行。
(3)全外链接:获取两张表中对应列匹配的数据行与对应列不匹配的数据行。
1.左外连接
--为了查询效果更加明显,先向emp2表中插入一条部门编号为50的雇员数据
--设置日期格式

--插入数据
![]()
--使用外键连接查询数据

另外外连接也可以使用操作符“(+)”实现。

2.右外连接

![]()
通过(+)号实现右外连接


3.全外链接


3.3.3分页查询
分页查询每次只会查询表中的部分数据,分批次的进行查询操作,可以减轻服务器压力,提高程序的效率。
--编写查询语句
select*from emp2;
--将第一条查询语句作为基础表进行查询,并添加伪列
select rownum,e.*from (select*from emp2) e;
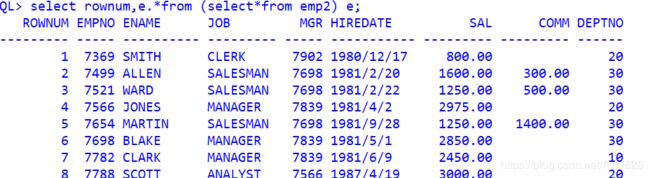
--获取编号小于等于6的数据

--获取编号小于等于6大于等于3的数据
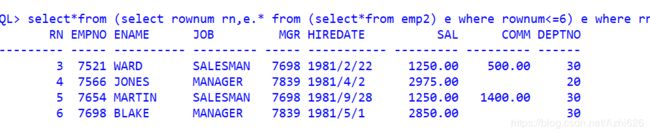
编写分页查询语句时,一定要先对伪列的值做小于判断,在对伪列的值做大于判断,否则就查询不到有效的数据。