mysql常用的一些查询语句
一、 Like字段模糊搜索:
SELECT * FROM fs_performance_details WHERE dimension_name LIKE 'UI%’; (或者%UI%,%UI来表示前后,前,有参数内容)
二、 order by和desc结合使用:
SELECT * FROM fs_performance_details WHERE dimension_name LIKE 'UI%' ORDER BY id DESC;
三、LEFT JOIN :
SELECT column_name(s) FROM table_name1 LEFT JOIN table_name2 ON table_name1.column_name=table_name2.column_name
LEFT JOIN,左联表(以左边表为依照,右边表没有的空显示) ,RIGHT JOIN, 右联表(以右边表为依照,左边表对应内容不全空显示) ,Inner Join,(两者内容都有匹配才显示,一方没有匹配,另一方也不显示) ,Full Join, (只要有一方有内容匹配就显示)
知识点:
UNION返回两个结果集的并集。还有一个union all的用法(union没有包含重复列,union all 包含重复列)
EXCEPT 返回两个结果集的差(即从左查询中返回右查询没有找到的所有非重复值(第一个表有,第二个表无))。
INTERSECT 返回 两个结果集的交集(即两个查询都返回的所有非重复值)。
四、求合集
1.union 的用法
语法:
UNION 子句的基本语法如下所示:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
例:
select test1_num,test1_address from test1
union
select test2_num,test2_address from test2;
解析:
在使用 UNION 的时候,每个 SELECT 语句必须有相同数量的选中列、相同数量的列表达式、相同的数据类型,并且它们出现的次序要一致,不过长度不一定要相同。
如:两个表查询的都是两列,即select语句有相同的数量的选中列;test1_num和test2_num都是相同的数据类型,且都是在查询的结果中第一个出现,即出现的次序要一致。
2.union all 的用法
UNION ALL 运算符用于将两个 SELECT 语句的结果组合在一起,重复行也包含在内。
UNION ALL 运算符所遵从的规则与 UNION 一致。
语法:
UNION ALL的基本语法如下:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION ALL
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
五、求差集。
使用not in 求差集,但效率低
SELECT t1.* FROM t1 WHERE name NOT IN (SELECT name FROM t2)
(except 的用法,mysql里面没有这个内容
语法:
EXCEPT 子句的基本语法如下所示:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
EXCEPT
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition] )
六、求交集。
(intersect 的用法 mysql内部没有这个字段内容使用
语法:
EXCEPT 子句的基本语法如下所示:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
intersect
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
例如:
select t1_num,t1_name from t1
intersect
select t2_num,t2_name from t2;
)
此时只有id name age 所有都一样才是符合要求的
SELECT id, NAME, age FROM (SELECT id, NAME, age FROM t1 UNION ALL SELECT id, NAME, age FROM t2) a GROUP BY id, NAME, age HAVING COUNT(*) > 1 (最后的count>1要根据有多少个联合数组size-1使用,他表示的是重复的次数)
七、sql IN
SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,...)对应求一个字段对应多个值所对应的数据内容
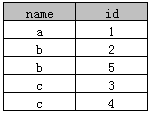
八、SQL中distinct的用法
在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。关键词 distinct用于返回唯一不同的值。
表A:

表B:
1.作用于单列
select distinct name from A
执行后结果如下:

2.作用于多列
示例2.1
select distinct name, id from A
执行后结果如下:
实际上是根据name和id两个字段来去重的,这种方式Access和SQL Server同时支持。
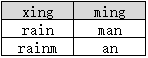
示例2.2
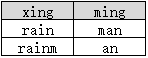
select distinct xing, ming from B
返回如下结果:
返回的结果为两行,这说明distinct并非是对xing和ming两列“字符串拼接”后再去重的,而是分别作用于了xing和ming列。
3.COUNT统计
select count(distinct name) from A; --表中name去重后的数目, SQL Server支持,而Access不支持
count是不能统计多个字段的,下面的SQL在SQL Server和Access中都无法运行。
select count(distinct name, id) from A;
若想使用,请使用嵌套查询,如下:
select count(*) from (select distinct xing, name from B) AS M;
4.distinct必须放在开头
select id, distinct name from A; --会提示错误,因为distinct必须放在开头
5.其他
distinct语句中select显示的字段只能是distinct指定的字段,其他字段是不可能出现的。例如,假如表A有“备注”列,如果想获取distinc name,以及对应的“备注”字段,想直接通过distinct是不可能实现的。但可以通过其他方法实现关于SQL Server将一列的多行内容拼接成一行的问题讨论