第一章 计算机网络和因特网
目录
文章目录
- 目录
- 因特网
- 端系统
- 数据中心
- 通信链路
- 报文
- 分组(packet)
- 分组交换机
- 存储转发传输(store-and-forward transmission)
- 排队时延
- 丢包(packet loss)
- 传播时延
- 端系统之间的吞吐量
- 瞬时吞吐量
- 平均吞吐量
- 分组交换网中的时延
- 处理时延(processing delay)
- 排队时延(queuing delay)
- 传输时延(Transmission delay)
- 传播时延
- 路由选择协议
- IP地址
- 转发表
- 电路交换
- 接入网
- 边缘路由器
- 路径
- 因特网服务提供商(ISP)
- 协议
- 网络协议
- TCP
- 因特网标准
- 分布式应用程序
- 应用程序编程接口
因特网
因特网是最大的系统,该系统包括:
- 数以亿计:计算机、通信链路、交换机
- 数十亿:便携计算机、平板电脑、智能手机
- 还有一批与因特网连接的新型设备: 传感器、web摄像机、游戏机、相框、洗衣机
也就是说:因特网组件众多,那么因特网的工作原理到底是怎么样的?
端系统
端系统(end system)/主机(host):
通常把与因特网相连的计算机和其他设备称为端系统。因为它们位于因特网的边缘,所以被称为端系统。
因特网的端系统包括了
- 桌面PC,Mac和linux盒
- 服务器(例如,Web和电子邮件服务器)
- 移动计算机(例如智能手机,平板电脑,便携机)
- 此外,越来越多的非传统设备正被作为端系统与因特网相连
端系统也被称为主机。因为它们容纳(即运行)应用程序。
例如
- Web浏览器程序
- Web服务器程序
- 电子邮件阅读程序
- 电子邮件服务器程序
主机有时被进一步划分为两类:
- 客户(client)
- 桌面PC, 移动PC, 智能手机
- `服务器(server)
- 更为强大的机器,用于存储和发布Web页面、流视频、中继电子邮件等
数据中心
数据中心(data center)
1个数据中心中有很多服务器,Google公司拥有30-50个数据中心,其中许多数据中心都有10万太以上的服务器。
通信链路
通信链路(communication link):根据物理媒体不同(同轴电缆,铜线,光纤和无线电频谱)可以分为不同的类型,传输速率(bit/s, bps)也不同
报文
报文:消息,message
在各种网络应用中,端系统彼此交换报文。
- 报文能够包含协议涉及这需要的任何东西。
- 报文可以执行一种控制功能(例如,“你好“),也可以包含数据(例如,电子邮件数据,JPEG图像,或者MP3音频文件)。
分组(packet)
分组(packet):当一台端系统要向另一台端系统发送数据时,发送端系统将数据分段,并为每段加上首部字节。由此形成的信息包用计算机网络的术语来说称为分组。
即:分段+首部字节 = 分组
源端系统将报文划分成较小的数据块,称之为分组(packet)
分组交换机
分组交换机(packet switch): 种类很多,两种最著名的类型是:
路由器(router):通常用于网络核心中。链路层交换机(link-layer switch):通常用于接入网中
在源主机和目的主机之间,每个分组都通过通信链路和分组交换机传送。
分组在通信链路上的传输速度:该链路最大传输速率
看个例题:如果某源端系统或者分组交换机经过一条链路发送一个L bits的分组,链路的传输S速率为R bit/s,则传输该分组的时间为L/R 秒。
存储转发传输(store-and-forward transmission)
多数分组交换机在链路的输入端使用存储转发传输机制。什么意思?!
存储转发机制是指:在分组交换机能够开始向输出链路传输该分组的第一个bit之前,必须接收到整个分组。
举个例子讲解一下存储转发机制!
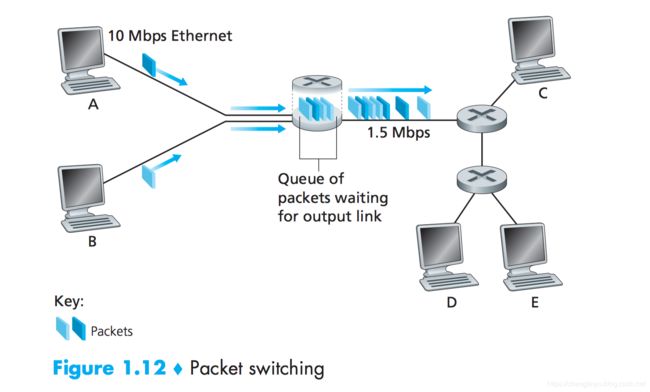
假如现在有个网络:两个经一台路由器(分组交换机的一种,通常用于网络核心)连接的端系统构成的简单网络。如下图所示

一台路由器通常有多条繁忙的链路,因为它的任务就是把一个入分组交换到一条出链路。在这个简单例子中,该路由器的任务相当简单:将分组从一条输入链路转移到另一条唯一的连接链路。在上图所示的特定时刻,源主机已经传输了分组1的一部分,分组1的前沿已经到达了路由器。
但是因为该路由器使用了存储转发机制,所以此时它还不能传输已经接收的比特,而是必须先缓存(即存储)该分组的比特。仅当该路由器已经接收完了该分组的所有比特后,它才能开始向出链路传输(即“转发”)该分组。
为了深刻领悟存储转发传输,我们现在计算一下从源主机开始发送分组到目的主机接收到整个分组所经过的时间。
这里我们将忽略传播时延———即我们假设这些比特以接近光速的速度跨越线路所需要的时间)
-
例1
源主机从0时刻开始传输,在时刻L/R秒,该路由器刚好接收到整个分组,所以它能够朝着目的主机向出链路开始传输分组;
在时刻2L/R,路由器已经传输了整个分组,并且这个分组已经被目的地接收。
所以总时延是2L/R.
如果交换机一旦比特达到就转发比特(不必接收到整个分组),则因为比特没有在路由器保持,总时延将是L/R。
好了,我们会计算时延了,但是有什么用吗? -
例2
现在我们来计算从源开始发送第一个分组知道目的地接收到所有3个分组所需的时间。与前面一样,在时刻L/R,路由器开始转发第一个分组。
而在时刻L/R,因为源主机已经完成了发送整个第一个分组,所以源主机也开始发送第二个分组,所以在时刻2L/R,目的地已经收到第一个分组并且路由器已经收到第二个分组。
类似地,在时刻3L/R,目的地已经收到前两个分组并且路由器已经收到第三个分组,所以在时刻4L/R,目的地已经收到所有3个分组! -
例3
我们现在考虑通过由N条速率均为R的链路构成的路径(所以,在源主机和目的地主机之间有N-1台路由器),从源主机到目的地主机之间发送一个分组,所需要的端到端时延是:
d e n d − t o − e n d = N L R d_{\mathrm{end}-\mathrm{to}-\mathrm{end}}=N \frac{L}{R} dend−to−end=NRL
你就这么想:从源主机发送要一个L/R,中间每个路由器发送又需要(N-1)L/R,所以最后的时间就是NL/R.
排队时延
每个分组交换机有多条链路与之相连。对于每条相连的链路,该分组交换机具有一个输出缓存(output buffer),也称为输出队列(output queue),这个缓存用于存储路由器准备发往那条链路的分组。这个输出缓存在分组交换中起什么作用呢?
如果到达路由器的分组需要传输到某条链路,但是发现该链路正忙于传输其他分组,该到达分组必须在该输出缓存中等待。所以,除了存储转发时延以外,分组还要承受输出缓存的排队时延。这些时延是变换的,变化的程度取决于网络中的拥塞程度。
因为缓存空间的大小是有限的,一个到达的分组可能发现该缓存已经被其他等待传输的分组完全充满了。在此情况下,将出现分组丢失(丢包)(packet lost),到达的分组或者已经排队的分组之一将被丢弃。不懂!
丢包(packet loss)
A packet can arrive to find a full queue. With no place to store such a packet, a router will drop that packet; that is, the packet will be lost.
传播时延
在理想情况下,我们希望因特网能够在任意两个端系统之间瞬间移动我们想要的大量数据而没有任何数据丢失,然而,理想很丰满,现实很骨感。计算机网络肯定要限制在端系统之间的吞吐量(每秒能够传送的数据量),在端系统之间引入delays, 并且在实际中确实会出现丢包。
端系统之间的吞吐量
端系统之间每秒能够传送的数据量。
瞬时吞吐量
平均吞吐量
这话还不是一句两句能说清楚的。好吧,看后面的详细解说
分组交换网中的时延
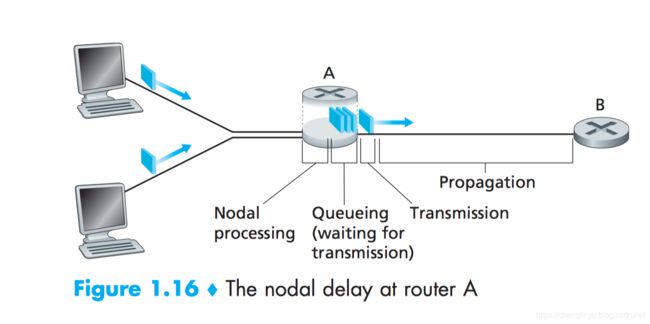
分组在沿途的每个节点经受了几种不同类型的时延。我们只需要记住下面这几种
结点处理时延(nodal processing delay)排队时延(queuing delay)传输时延(transmission delay)传播时延(propagation delay)
这些时延累加起来是:结点总时延(total nodal delay)
我用下面这个图跟大家将清楚这些类型的时延到底是什么?如何计算?
处理时延(processing delay)
当一个分组到达一个路由器之后,路由器干这些事情话费的时间就叫做处理时延
- 检查分组的头
- 决定将这个分组往哪个地方分发(就是查转发表)
- 检查分组中比特级别差错花费的时间
排队时延(queuing delay)
在节点处理之后,路由器就会将这个分组导入到相应的输出队列中。如果没有分组正在前面的路上,这个分组就直接走。如果有分组正在路上,这个分组就等一会儿。那么这个排队等待的时间就是排队时延。如果幸运,路上没有人,那么排队时延就是0
传输时延(Transmission delay)
先来先服务在分组交换网络中很普遍,我们的分组仅能在整个分组到达之后才能够上路。假设分组是以一种先来先服务的方式进行传输,设分组的长度为L bits, 从路由器A到路由器B的链路的传输速率是R bits/sec, 举个例子,对于一个10Mbps的以太网链路, 那么传输速率R = 10 Mbps. 对于一个100Mbps的以太网链路,R = 100 Mbps. 传输时延就是L/R。说白了,就是发送的时间。总得一个bit,一个bit的发送吧。
打个比方:
就像一个班的学生(一个分组)过一条狭窄的山路(链路),这条小道一次容纳一个人(一个bit)的身体。你作为老师在这边放学生过的时候,你总得间隔一段时间才能放一个学生吧(传输速率)。你要是放的快了,后面的学生踩前面学生的脚后跟。每个学生上了山路之后,总得慢慢的走,才能走到对岸吧。(这个时间是传播时延)
传播时延
就是一个学生从桥的这头走到桥的那头花的时间。但是这个时间不取决于学生,因为这个桥装上了传送带。速度取决于传送带的速度。
到目前为止:我感觉把链路比喻成传送带是最恰当的。把bit位比喻成物体是最恰当的。
就是一个bit从链路的这头传播到链路的那头花的时间。
Once a bit is pushed into the link, it needs to propagate to router B. The time required to propagate from the beginning of the link to router B is the propagation delay.
时间 = 路程/速度。现在路程已经定了,所以传播时延就取决于速度。这个速度就是链路的传播速度。链路的传播速度取决于链路的物理介质。跟我这个bit位没有关系。
英文解释绝对精辟!
The transmission delay is the amount of time required for the router to push out the packet; it’s a function of the packet’s length and the transmission rate of the link, but has nothing to do with the distance between the two routers.
The propagation delay, on the other delay, is the time it takes a bit to propagate from one router to the next; it is a function of the distance of the two routers, but has nothing to do with the packet’s length, or the transmission rate of the link.
路由选择协议
在因特网中,每个端系统具有一个称为IP地址的地址。当源主机要向目的主机发送一个分组时,源主机在该分组的首部包含了目的地主机的IP地址。如同邮政地址一样,该地址具有一种等级结构。当一个分组到达网路中的路由器时,路由器检查该分组的目的地主机地址的一部分,并向一台相邻路由器转发该分组。更特别的是,每天路由器具有一个转发表(forwarding table),用于将目的地主机地址(或者目的地主机IP地址的一部分)映射成为输出链路。当某分组到达一台路由器时,路由器检查该地址,并用这个目的地址搜索转发表,映射成出链路。路由器则将分组导向该出链路。
一个路由选择协议可以决定从每台路由器到每个目的地的最短路径,并使用这些最短路径结果来配置路由器中的转发表。
IP地址
在因特网中,每个主机被IP地址所标识,IP地址是一个32位的二进制传,即4个字节。
转发表
key:目的地主机地址 value:出链路的编号.
转发表是如何配置的?因特网具有一些特殊的路由选择协议(routing protocol),用于自动地设置这些转发表。
电路交换
通过网路链路和交换机移动数据有两种基本方法:电路交换(circuit switching)和分组交换(packet switching)
在电路交换网络中,在端系统之间通信会话期间,预留了端系统之间通信沿路经所需要的资源(缓存,线路传输速率)。
在分组交换网络中,端系统之间通信沿路经所需要的资源(缓存,线路传输速率)则不是预留的。其后果可能是不得不等待(即排队)接入通信线路。
好了,为了进一步理解电路交换和分组交换的区别,我们来打个比方!
两家餐厅,一家需要顾客预订,而另一家不需要预订但是不保证能安排顾客。
对于需要预订的那家餐馆,我们在离开家之前必须承受先打电话的麻烦。但是当我们到达该餐馆时,原则上我们能够立即入座并点菜。
对于不需要预订的那家餐馆,我们不必麻烦预订餐桌,但是也许不得不先等待一张餐桌空闲后才能够入座。
所以,需要预订的餐厅就是电路交换,不需要预订的餐厅就是分组交换。
传统的电话网络就是电路交换网络的例子。
当一个人通过电话网向另一个人发送消息(语音或者传真)时所发生的情况。在发送方能够发送消息之前,该网络必须在发送方和接受方之间建立一条连接(相当于预订餐桌)。这是一个名副其实的连接,因为此时沿着发送方和接收方之间路径上的交换机都将为该链接维护连接状态。用电话的术语来讲,该连接被称为一条电路(circuit).
当网络创建这种电路时,它也在连接期间在该网络链路上预留了恒定的传输速率(表示为每条链路传输容量的一部分)。
既然已经为发送方——接收方连接 预留了带宽,则发送方能够以确保的恒定速率向接收方发送数据。
接入网
接入网(access network)
指将端系统连接到边缘路由器(edge router)的物理链路。
边缘路由器
边缘路由器(edge router)
边缘路由器是端系统到任何其他远程端系统的路径上第一台路由器。
哪些环境要使用接入网?这个暂时不细讲
- 家庭接入
- 企业(和家庭)接入:以太网和Wifi。以太网是局域网的一种,以太网到目前为止是当前公司、大学和家庭网络中最为流行的接入技术。
- 广域无线接入:3G和LTE,不懂!
端系统通过通信链路和分组交换机连接到一起。分组交换机的作用就是转发分组。分组交换机从它的一条入通信链路接收到达的分组,并从它的一条出通信链路转发该分组。
路径
路径
从发送端系统到接收端系统,一个分组所经历的一系列通信链路和分组交换机称为通过该网络的路径.
即:路径 = 通信链路 + 分组交换机
用于传送分组的分组交换网络非常类似于承载运输车辆的运输网络。
一个工厂需要将大量货物搬运到数千公里以外的某个目的地仓库。在工厂中,货物要分开并装上卡车车队。然后,每辆卡车独立地通过高速公路、公路和立交桥组成的网络向该仓库运送货物。
在目的地仓库,卸下这些货物,并且与一起装载的同一批货物的其余部分堆放在一起。
分组 —>卡车
通信链路 —> 高速公路和公路
分组交换机 -----> 立交桥
端系统 -----> 建筑物
因特网服务提供商(ISP)
因特网服务提供商(Internet Service Provider, ISP)
端系统通过ISP接入因特网。
ISP是由多个分组交换机和多段通信链路组成的网络。
因为因特网就是将端系统彼此互联,因此为端系统提供接入的ISP也必须互联。
每个ISP都是独立管理的,运行着IP协议。
协议
协议
端系统、分组交换机和其他因特网部件都要运行一系列协议(protocol),这些协议控制因特网中的信息的接收和发送。
就是一些列约定俗成的动作。
网络协议
网络协议
网络协议类似于人类协议。**在因特网中,凡是涉及两个或者多个远程通信实体的所有活动都收到协议的制约。**例如,
- 在两台物理机上连接的计算机中,
硬件实现的协议控制了在两块网络接口卡间的“线上”的比特流; - 在端系统中,
拥塞控制协议控制了在发送方和接受方之间传输的分组发送的速率。
向Web服务器发送请求:即在Web浏览器(chrome, firefox and so on)中输入一个Web网页的URL。这个过程到底是怎么样的呢?
- 你的计算机向Web服务器发送一条
连接请求报文,并等待回答 - Web服务器接受到连接请求报文后,返回一条连接响应报文。
- 计算机收到连接响应报文,得知请求该Web文档正常以后,计算机则在一条GET报文中发送要从这台Web服务器上取回的网页名字。
- Web服务器向计算机返回该Web网页(文件)
定义一个协议的关键元素:报文的交换以及发送和接收这些报文时所采取的动作
一个协议定义了在两个或者多个通信实体之间交换的报文格式和次序,以及报文发送/接收或者是其他事件所采取的动作。
TCP
TCP(Transmission Control Protocol):传输控制协议
IP(Internet Protocol):网际协议:定义了路由器和端系统之间发送和接收的分组格式
是因特网中两个最重要的协议。
因特网的主要协议统称为TCP/IP。
由于因特网协议和重要,所有每个人就各个协议及其作用取得一致认识很重要。这样人们才能够创造出协同工作的系统和产品。 这个一致认识就叫做因特网标准(internet standard)
因特网标准
因特网标准由因特网工程任务组(Internet Engineerning Task Force, IETF)研发,IETF的标准文档称为请求评论(Request For Comment(RFC)),这些文档定义了HTTP, TCP ,IP, SMTP等协议。目前已经有近6000个RFC.
分布式应用程序
分布式应用程序
什么是分布式应用程序?下面这些就都是:
电子邮件,Web冲浪,即时讯息,社交网络,IP语音(VoIP), 流式视频,分布式游戏,对等文件共享(peer-to-peer P2P),文件共享,因特网电视,远程注册等。
定义:涉及多台相互交换数据的端系统的应用程序!并且应用程序运行在端系统上,即它们并不运行在网络核心中的分组交换机中。即尽管分组交换机促进端系统之间的数据交换,但是它们并不关心作为数据的源或者宿的应用程序。
应用程序编程接口
应用程序编程接口(Application Programming Interface, API
运行在一个端系统上的应用程序怎样才能指令因特网向运行在另一个端系统上的软件发送数据呢?
与因特网相连的端系统提供了一个应用程序编程接口,对就是端系统为应用程序提供了应用程序编程接口。
该API规定了运行在一个端系统上的软件 请求 因特网基础实施 向 运行在 另一个端系统上的特定目的地软件交付数据的方式。
所以发送消息的软件必须遵循这些API, 这样因特网才能够将数据交付给目的地。
有关API,我们打个比方就懂了!
假定Alice使用邮政服务向Bob发一封信,当然,Alice不能只是写了这封信,然后将该信丢出窗外。相反,邮政服务要求Alice将信放入一个信封中;在信封的中央写上Bob的全名、地址和邮政编码。封上信封;在信封的右上角贴上邮票;最后将信封丢进一个邮局的邮政服务邮箱中。因此该邮政服务有自己的”邮政服务API"或者一套规则,这是Alice必须遵循的。这样邮政服务才能将自己的信件交付给Bob。同理,因特网也有一个发送数据的程序必须遵循的API, 使得因特网向接收数据的程序交付数据。
总结:应用程序之于API ---------- 寄信人之于邮局规定的寄信规则。