集群上独立运行Alluxio1.8使用HA HDFS为底层存储系统
软件版本:
| 软件 | 版本 |
|---|---|
| jdk | jdk1.8.0_191 |
| zookeeper | zookeeper-3.4.12 |
| hadoop | hadoop-2.8.5 |
| alluxio | alluxio-1.8.0-hadoop-2.8 |
配置JDK:
解压并创建软链接:
$ sudo ln -s /opt/Software/jdk1.8.0_191/ /jdk
配置环境变量:
$ vi /etc/profile
添加以下内容:
export JAVA_HOME=/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
更新环境变量文件:
$ source /etc/profile
配置免密钥:
查看本地是否装有SSH 协议:
$ sudo rpm -qa|grep ssh
如果没有需要yum安装 ssh
在用户目录下进入.ssh目录检查是否需要配置免密钥
默认没有 .ssh 目录
如果没有配置执行就生成 SSH 密钥:
$ ssh-keygen -t rsa
连续四个回车执行完毕
将公钥拷贝到目标远程主机和自己:
$ ssh-copy-id dpnice@cdh1
$ ssh-copy-id dpnice@cdh2
$ ssh-copy-id dpnice@cdh3
安装配置zookeeper:
解压zookeeper:
进入解压后zookeeper 目录创建文件夹:
$ mkdir log
$ mkdir data
进入conf目录
$ cp zoo_sample.cfg zoo.cfg
$ vi zoo.cfg
添加或修改以下内容:
dataDir=/opt/Software/zookeeper-3.4.12/data
dataLogDir=/opt/Software/zookeeper-3.4.12/log
server.1=cdh1:2222:2225
server.2=cdh2:2222:2225
server.3=cdh3:2222:2225
在数据目录/opt/Software/zookeeper-3.4.12/data下面新建名为myid的文件:
$ vi /opt/Software/zookeeper-3.4.12/data/myid
添加cdh1的myid文件内容为
1
各个主机对应的内容是不同的,cdh1的内容是1,cdh2的内容是2,cdh3的内容是3,分别对应配置文件中server.x中的x
将配置文件发送到其他节点:
$ scp -r /opt/Software/zookeeper-3.4.12/conf/zoo.cfg dpnice@cdh2:/opt/Software/zookeeper-3.4.12/conf/
$ scp -r /opt/Software/zookeeper-3.4.12/conf/zoo.cfg dpnice@cdh3:/opt/Software/zookeeper-3.4.12/conf/
所有节点执行启动:
$ /opt/Software/zookeeper-3.4.12/bin/zkServer.sh start
查看节点的身份状态:
$ /opt/Software/zookeeper-3.4.12/bin/zkServer.sh status
安装Haoop 配置HA HDFS 、HA YARN:
解压Hadoop:
进入Hadoop目录
$cd /opt/Software/hadoop-2.8.5/
创建文件夹:
mkdir /opt/Software/hadoop-2.8.5/tmp
mkdir /opt/Software/hadoop-2.8.5/data
进入Hadoop配置文件目录:
$ cd etc/hadoop/
编辑配置文件:
$ vi core-site.xml 追加如下内容:
fs.defaultFS
hdfs://nns
hadoop.tmp.dir
/opt/Software/hadoop-2.8.5/tmp
io.file.buffer.size
4096
ha.zookeeper.quorum
cdh1:2181,cdh2:2181,cdh3:2181
fs.trash.interval
1440
默认0,表示不开启垃圾箱功能,大于0时,表示删除的文件在垃圾箱中存留的分钟数,
fs.trash.checkpoint.interval
1440
垃圾回收检查的时间间隔,值应该小于等于 fs.trash.interval。默认0,此时按fs.trash.interval的值大小执行
$ vi hdfs-site.xml
NameNode的名字不能带有 “_” 下划线
dfs.nameservices
nns
dfs.ha.namenodes.nns
nn0,nn1
dfs.namenode.rpc-address.nns.nn0
cdh1:9000
dfs.namenode.http-address.nns.nn0
cdh1:50070
dfs.namenode.rpc-address.nns.nn1
cdh2:9000
dfs.namenode.http-address.nns.nn1
cdh2:50070
dfs.namenode.shared.edits.dir
qjournal://cdh1:8485;cdh2:8485;cdh3:8485/nns
dfs.journalnode.edits.dir
/opt/Software/hadoop-2.8.5/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.nns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/dpnice/.ssh/id_rsa
dfs.namenode.name.dir
file:///opt/Software/hadoop-2.8.5/data/namenode
dfs.datanode.data.dir
file:///opt/Software/hadoop-2.8.5/data/datanode
dfs.replication
2
dfs.permissions.enabled
false
dfs.web.ugi
dpnice,supergroup
dfs.permissions.superusergroup
supergroup
$ cp mapred-site.xml.template mapred-site.xml
$ vi mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
cdh2:10020
mapreduce.jobhistory.webapp.address
cdh2:19888
$ vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序
yarn.resourcemanager.ha.enabled
true
是否启用 ResourceManager 高可用,默认 false
yarn.resourcemanager.cluster-id
cluster1
ResourceManager 集群名
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
cdh1
yarn.resourcemanager.hostname.rm2
cdh2
yarn.resourcemanager.webapp.address.rm1
cdh1:8088
yarn.resourcemanager.webapp.address.rm2
cdh2:8088
yarn.resourcemanager.zk-address
cdh1:2181,cdh2:2181,cdh3:2181
yarn.log-aggregation-enable
true
是否开启日志聚集功能,默认false。应用执行完成后,Log Aggregation 收集每个 Container 的日志到 HDFS 上
yarn.log-aggregation.retain-seconds
25200
聚集日志最长保留时间
追加:hadoop-env.sh文件:
$ vi /opt/Software/hadoop-2.8.5/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/jdk
把配置文件发送到其他节点:
$ scp -rp /opt/Software/hadoop-2.8.5/etc/hadoop/core-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/hdfs-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/yarn-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/mapred-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/hadoop-env.sh cdh2:/opt/Software/hadoop-2.8.5/etc/hadoop/
$ scp -rp /opt/Software/hadoop-2.8.5/etc/hadoop/core-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/hdfs-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/yarn-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/mapred-site.xml /opt/Software/hadoop-2.8.5/etc/hadoop/hadoop-env.sh cdh3:/opt/Software/hadoop-2.8.5/etc/hadoop/
在Zookeeper中创建一个存储NameNode HA相关数据的 zNode
$ /opt/Software/hadoop-2.8.5/bin/hdfs zkfc -formatZK
使用zkCli查看zookeeper:
$ /opt/Software/zookeeper-3.4.12/bin/zkCli.sh -server 192.168.137.130:2181
zkCli查看是否有hadoop-ha目录:
$ ls /
启动所有 JournalNode 进程:
$ /opt/Software/hadoop-2.8.5/sbin/hadoop-daemons.sh start journalnode
执行格式化:
$ /opt/Software/hadoop-2.8.5/bin/hdfs namenode -format
如果需要重新格式化 NameNode,需要先将原来 NameNode 和 DataNode 下的文件全部删除,不然会报错,NameNode 和 DataNode 所在目录是在 core-site.xml 中 hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中,重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致namenode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,不一致时会报错。
在其中一台节点上启动Active NameNode:
$ /opt/Software/hadoop-2.8.5/sbin/hadoop-daemon.sh start namenode
在另一台节点同步 Standby NameNode:
$ /opt/Software/hadoop-2.8.5/bin/hdfs namenode -bootstrapStandby
启动 Standby NameNode:
$ /opt/Software/hadoop-2.8.5/sbin/hadoop-daemon.sh start namenode
至此可以关闭所有组件,然后启动hdfs了
切换第一台为 Active 状态:
$ /opt/Software/hadoop-2.8.5/bin/hdfs haadmin -transitionToActive --forcemanual nn0
–forcemanual 强制使用手动故障转移
关闭:journalnode
$ /opt/Software/hadoop-2.8.5/sbin/hadoop-daemons.sh stop journalnode
关闭:namenode
$ /opt/Software/hadoop-2.8.5/sbin/hadoop-daemon.sh stop namenode
启动HDFS:
$ /opt/Software/hadoop-2.8.5/sbin/start-dfs.sh
[dpnice@cdh1 hadoop-2.8.5]$ jps
13985 NameNode
14737 DFSZKFailoverController
14881 Jps
14147 DataNode
14454 JournalNode
8847 QuorumPeerMain
[dpnice@cdh2 hadoop-2.8.5]$ jps
11760 NameNode
12145 Jps
11942 JournalNode
12056 DFSZKFailoverController
11834 DataNode
8219 QuorumPeerMain
安装配置Alluxio 1.8
简介:
在大数据生态系统中,Alluxio介于计算框架(如Apache Spark,Apache MapReduce,Apache HBase,Apache Hive,Apache Flink)和现有的存储系统(如Amazon S3,OpenStack Swift,GlusterFS,HDFS,MaprFS,Ceph,NFS,OSS)之间。Alluxio为大数据软件栈带来了显著的性能提升。Alluxio与Hadoop是兼容的。现有的数据分析应用,如Spark和MapReduce程序,可以不修改代码直接在Alluxio上运行。
设计:
Alluxio的设计使用了单Master和多Worker的架构。从高层的概念理解,Alluxio可以被分为三个部分,Master,Worker和Client。Master和Worker一起组成了Alluxio的服务端,它们是系统管理员维护和管理的组件。Client通常是应用程序,如Spark或MapReduce作业,或者Alluxio的命令行用户。Alluxio用户一般只与Alluxio的Client组件进行交互。
进程:
AlluxioProxy:该进程使用一个内部Alluxio Java客户端对REST接口和Alluxio服务器之间的通信进行代理。
AlluxioMaster:负责管理元数据
AlluxioWorker:负责数据读写
前提条件:
- Java(JDK 8或更高版本)
- 开启远程登录服务
- 已经安装HDFS且正在运行
- 已经安装Zookeeper且正在运行
- 用户具有sudo权限
安装:
解压,配置环境变量,创建软链接
ln -s /opt/Software/alluxio-1.8.0-hadoop-2.8/ /alluxio
进入Alluxio 的conf目录开始配置:
创建软链接:
$ ln -s /opt/Software/hadoop-2.8.5/etc/hadoop/core-site.xml ./core-site.xml
$ ln -s /opt/Software/hadoop-2.8.5/etc/hadoop/hdfs-site.xml ./hdfs-site.xml
使用HA HDFS 为存储 或者在alluxio-site.properties中配置 alluxio.underfs.hdfs.configuration=/opt/Software/hadoop-2.8.5/etc/hadoop/core-site.xml:/opt/Software/hadoop-2.8.5/etc/hadoop/hdfs-site.xml
配置alluxio-site.properties文件:
$ cp alluxio-site.properties.template alluxio-site.properties
$ vi alluxio-site.properties
添加或追加以下内容:
alluxio.master.hostname=cdh1
alluxio.underfs.address=hdfs://nns/
alluxio.zookeeper.enabled=true
alluxio.zookeeper.address=cdh1:2181,cdh2:2181,cdh3:2181
alluxio.master.journal.folder=hdfs://nns/alluxio/journal
nns为 dfs.nameservices
alluxio.master.hostname 配置只需要在master 节点配置
worker 节点只需要配置 alluxio.zookeeper.enabled和alluxio.zookeeper.address
把配置信息发送到其他节点:
$ /opt/Software/alluxio-1.8.0-hadoop-2.8/bin/alluxio copyDir /opt/Software/alluxio-1.8.0-hadoop-2.8/conf/
同步文件和文件夹到所有的alluxio/conf/workers中指定的主机。如果你只在Alluxio master节点上下载并解压了Alluxio压缩包,你可以使用copyDir命令同步worker节点下的Alluxio文件夹,你同样可以 使用此命令同步conf/alluxio-site.properties中的变化到所有worker节点。
注意使用HA:cdh2需要修改为alluxio.master.hostname=cdh2 保证有两台master
第一次启动需要格式化:
$ /alluxio/bin/alluxio format
格式化后hdfs存在 /alluxio 文件夹:
[dpnice@cdh3 hadoop]$ /hadoop/bin/hdfs dfs -ls /
Found 4 items
drwxr-xr-x - dpnice supergroup 0 2018-11-29 02:06 /alluxio
sudo 免密钥
在Linux文件 /etc/sudoers下添加下面一行,赋予当前用户(“alluxio”)有限的sudo权限 alluxio ALL=(ALL) NOPASSWD: /bin/mount*/mnt/ramdisk, /bin/umount*/mnt/ramdisk, /bin/mkdir*/mnt/ramdisk, /bin/chmod*/mnt/ramdisk 这允许”alluxio”用户应用sudo权限在一个具体路径/mnt/ramdisk 下执行命令mount, umount, mkdir 和 chmod (假设命令在 /bin/) ,并且不需要输入密码。
验证本地环境:
$ /alluxio/bin/alluxio validateEnv local
在cdh1、cdh2启动 master:
$ /alluxio/bin/alluxio-start.sh master
在cdh1、cdh2、cdh3启动 worker:
$ sudo /alluxio/bin/alluxio-start.sh worker Mount
$ /alluxio/bin/alluxio-start.sh worker 使用这种方式需要创建ramfs 并在配置文件中配置路径
运行简单程序:
$ /alluxio/bin/alluxio runTests
验证:
[dpnice@cdh3 hadoop]$ /hadoop/bin/hdfs dfs -ls /
Found 4 items
drwxr-xr-x - dpnice supergroup 0 2018-11-29 02:06 /alluxio
drwxr-xr-x - dpnice dpnice 0 2018-11-29 02:28 /default_tests_files
查看leader节点:
$ /alluxio/bin/alluxio fs leader
[dpnice@cdh3 hadoop]$ /alluxio/bin/alluxio fs leader
cdh2
当leader宕机或者挂掉的时候 其他master会在短暂初始化操作后对外提供服务,未初始化完时显示:
[dpnice@cdh1 conf]$ /alluxio/bin/alluxio fs leader
cdh1
The leader is not currently serving requests.
访问leader节点 http://cdh2:19999
此时standby节点不可用
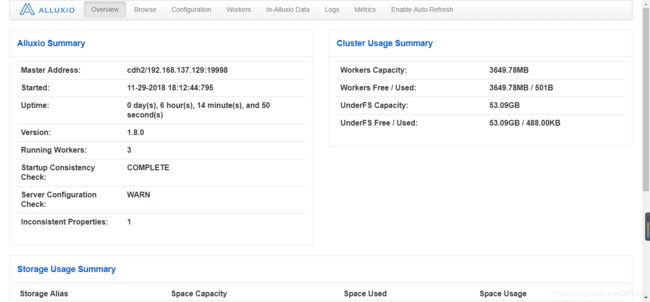
上传文件到alluxio根目录
$ /alluxio/bin/alluxio fs copyFromLocal simple-start-app.sh /
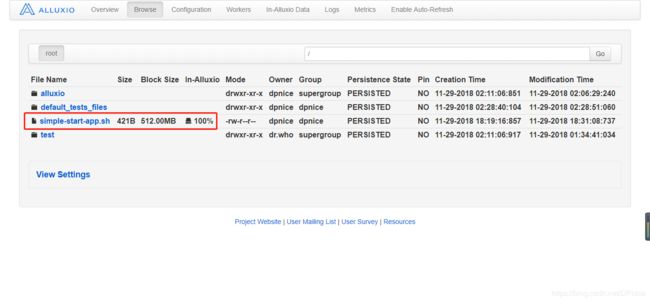
alluxio 文件持久化到HDFS
$ /alluxio/bin/alluxio fs persist /simple-start-app.sh
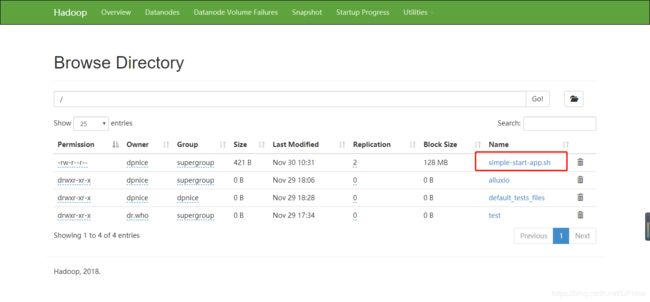
关闭命令:
$ /alluxio/bin/alluxio-stop.sh master
$ /alluxio/bin/alluxio-stop.sh worker
操作demo:
创建文件word
$ vi word.txt
内容为:
spark hadoop
spark hadoop alluxio dpnice
spark hadoop alluxio
spark hadoop alluxio
上传到HDFS:
[dpnice@cdh1 ~]$ /hadoop/bin/hdfs dfs -put ./word.txt /
查看文件:
[dpnice@cdh1 ~]$ /alluxio/bin/alluxio fs ls /
drwxr-xr-x dpnice supergroup 1 PERSISTED 11-29-2018 02:06:29:240 DIR /alluxio
drwxr-xr-x dpnice dpnice 24 PERSISTED 11-29-2018 02:28:51:060 DIR /default_tests_files
drwxr-xr-x dpnice dpnice 0 PERSISTED 11-30-2018 01:14:47:538 DIR /efault_tests_files
drwxr-xr-x dpnice dpnice 0 NOT_PERSISTED 11-30-2018 01:18:21:146 DIR /mnt
-rw-r--r-- dpnice dpnice 421 PERSISTED 11-29-2018 18:31:08:737 100% /simple-start-app.sh
drwxr-xr-x dr.who supergroup 0 PERSISTED 11-29-2018 01:34:41:034 DIR /test
-rw-r--r-- dpnice supergroup 84 PERSISTED 11-30-2018 01:08:06:984 0% /word.txt
HDFS上的word.txt会自动映射到alluxio里,但是Not In Memory,没有存在内存中。
统计word.txt中spark的数量:
[dpnice@cdh1 ~]$ time /alluxio/bin/alluxio fs cat /word.txt | grep -c spark
4
real 0m11.023s
user 0m3.490s
sys 0m1.136s
再次查看文件word.txt:
[dpnice@cdh1 ~]$ /alluxio/bin/alluxio fs ls /word.txt
-rw-r--r-- dpnice supergroup 84 PERSISTED 11-30-2018 01:08:06:984 100% /word.txt
显示已经全部加载到内存中
再次统计hadoop的数量:
[dpnice@cdh1 ~]$ time /alluxio/bin/alluxio fs cat /word.txt | grep -c hadoop
4
real 0m3.649s
user 0m2.289s
sys 0m0.670s
会看到相比第一次明显快了很多(其实还是慢的因为虚拟机的缘故),因为数据已经存放到了Alluxio。
操作列表:
| 操作 | 语法 | 描述 |
|---|---|---|
| cat | cat “path” | 将Alluxio中的一个文件内容打印在控制台中 |
| checkConsistency | checkConsistency “path” | 检查Alluxio与底层存储系统的元数据一致性 |
| checksum | checksum “path” | 计算一个文件的md5校验码 |
| chgrp | chgrp “group” “path” | 修改Alluxio中的文件或文件夹的所属组 |
| chmod | chmod “permission” “path” | 修改Alluxio中文件或文件夹的访问权限 |
| chown | chown “owner” “path” | 修改Alluxio中文件或文件夹的所有者 |
| copyFromLocal | copyFromLocal “source path” “remote path” | 将“source path”指定的本地文件系统中的文件拷贝到Alluxio中"remote path"指定的路径 如果"remote path"已经存在该命令会失败 |
| copyToLocal | copyToLocal “remote path” “local path” | 将"remote path"指定的Alluxio中的文件复制到本地文件系统中 |
| count | count “path” | 输出"path"中所有名称匹配一个给定前缀的文件及文件夹的总数 |
| cp | cp “src” “dst” | 在Alluxio文件系统中复制一个文件或目录 |
| du | du “path” | 输出一个指定的文件或文件夹的大小 |
| fileInfo | fileInfo “path” | 输出指定的文件的数据块信息 |
| free | free “path” | 将Alluxio中的文件或文件夹移除,如果该文件或文件夹存在于底层存储中,那么仍然可以在那访问 |
| getCapacityBytes | getCapacityBytes | 获取Alluxio文件系统的容量 |
| getfacl | getfacl “path” | |
| getUsedBytes | getUsedBytes | 获取Alluxio文件系统已使用的字节数 |
| help | help “cmd” | 打印给定命令的帮助信息,如果没有给定命令,打印所有支持的命令的帮助信息 |
| leader | leader | 打印当前Alluxio leader master节点主机名 |
| load | load “path” | 将底层文件系统的文件或者目录加载到Alluxio中 |
| loadMetadata | loadMetadata “path” | 将底层文件系统的文件或者目录的元数据加载到Alluxio中 |
| location | location “path” | 输出包含某个文件数据的主机 |
| ls | ls “path” | 列出给定路径下的所有直接文件和目录的信息,例如大小 |
| masterInfo | masterInfo | 打印Alluxio master容错相关的信息,例如leader的地址、所有master的地址列表以及配置的Zookeeper地址 |
| mkdir | mkdir “path1” … “pathn” | 在给定路径下创建文件夹,以及需要的父文件夹,多个路径用空格或者tab分隔,如果其中的任何一个路径已经存在,该命令失败 |
| mount | mount “path” “uri” | 将底层文件系统的"uri"路径挂载到Alluxio命名空间中的"path"路径下,"path"路径事先不能存在并由该命令生成。 没有任何数据或者元数据从底层文件系统加载。当挂载完成后,对该挂载路径下的操作会同时作用于底层文件系统的挂载点。 |
| mv | mv “source” “destination” | 将"source"指定的文件或文件夹移动到"destination"指定的新路径,如果"destination"已经存在该命令失败。 |
| persist | persist “path1” … “pathn” | 将仅存在于Alluxio中的文件或文件夹持久化到底层文件系统中 |
| pin | pin “path” | 将给定文件锁定到内容中以防止剔除。如果是目录,递归作用于其子文件以及里面新创建的文件 |
| report | report “path” | 向master报告一个文件已经丢失 |
| rm | rm “path” | 删除一个文件,如果输入路径是一个目录该命令失败 |
| setfacl | setfacl “newACL” “path” | |
| setTtl | setTtl “path” “time” | 设置一个文件的TTL时间,单位毫秒 |
| stat | stat “path” | 显示文件和目录指定路径的信息 |
| tail | tail “path” | 将指定文件的最后1KB内容输出到控制台 |
| test | test “path” | 测试路径的属性,如果属性正确,返回0,否则返回1 |
| touch | touch “path” | 在指定路径创建一个空文件 |
| unmount | unmount “path” | 卸载挂载在Alluxio中"path"指定路径上的底层文件路径,Alluxio中该挂载点的所有对象都会被删除,但底层文件系统会将其保留。 |
| unpin | unpin “path” | 将一个文件解除锁定从而可以对其剔除,如果是目录则递归作用 |
| unsetTtl | unsetTtl “path” | 删除文件的ttl值 |
ramfs和tmpfs的区别:https://www.cnblogs.com/dosrun/p/4057112.html
http://www.alluxio.org/docs/1.8/cn/deploy/Running-Alluxio-on-a-Cluster.html#配置alluxio
http://www.alluxio.org/docs/1.8/cn/ufs/HDFS.html#基本配置
http://www.alluxio.org/docs/1.8/cn/basic/Command-Line-Interface.html#操作列表