python2 scrapy-redisd搭建,简单使用。爬取豆瓣点评
Scrapy 和 scrapy-redis的区别
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。
Scrapy-redis提供了下面四种组件(components):(四种组件意味着这四个模块都要做相应的修改)
- Scheduler
- Duplication Filter
- Item Pipeline
- Base Spider
安装scrapy-redis
pip install scrapy-redisscrapy-redis架构
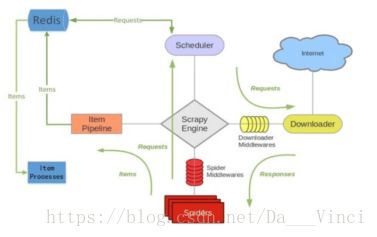
如上图所⽰示,scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下组件:
Scheduler:
Scrapy改造了python本来的collection.deque(双向队列)形成了自己的Scrapy queue(https://github.com/scrapy/queuelib/blob/master/queuelib/queue.py)),但是Scrapy多个spider不能共享待爬取队列Scrapy queue, 即Scrapy本身不支持爬虫分布式,scrapy-redis 的解决是把这个Scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
Scrapy中跟“待爬队列”直接相关的就是调度器Scheduler,它负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。它把待爬队列按照优先级建立了一个字典结构,比如:
{
优先级0 : 队列0
优先级1 : 队列1
优先级2 : 队列2
}
然后根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的scheduler组件。
Duplication Filter
Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。这个核心的判重功能是这样实现的:
def request_seen(self, request):
# self.request_figerprints就是一个指纹集合
fp = self.request_fingerprint(request)
# 这就是判重的核心操作
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
Item Pipeline:
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。
修改过Item Pipeline可以很方便的根据 key 从 items queue 提取item,从⽽实现 items processes集群。
Base Spider
不在使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。
一个是当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request。
爬取豆瓣点评
豆瓣内容为静态的,便于爬取。作为本文示例。感谢豆瓣数据。
创建scrapy项目

RedisPipeline
在setting中设置Redis通道,爬到的数据会自动储存到Redis数据库中,若无明确指示,会保存在本机的db0中。
ITEM_PIPELINES = {
'scrapy_redis_test.pipelines.spider1JsonPipeline' : 401,
'scrapy_redis.pipelines.RedisPipeline' : 400,
}启动Redis
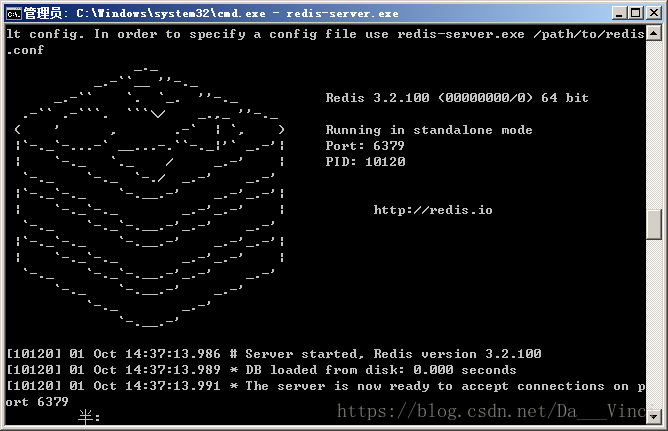
爬虫文件Spider
# -*- coding: utf-8 -*-
from scrapy.spiders import Rule
from scrapy_redis.spiders import RedisCrawlSpider
import scrapy
from ..items import DoubanspiderItem
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]
start = 0
url = 'https://movie.douban.com/top250?start='
end = '&filter='
start_urls = [url + str(start) + end]
def parse(self, response):
item = DoubanspiderItem()
movies = response.xpath("//div[@class=\'info\']")
for each in movies:
title = each.xpath('div[@class="hd"]/a/span[@class="title"]/text()').extract()
content = each.xpath('div[@class="bd"]/p/text()').extract()
score = each.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()
info = each.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
item['title'] = title[0]
item['content'] = ';'.join(content) # 以;作为分隔,将content列表里所有元素合并成一个新的字符串
item['score'] = score[0]
item['info'] = info[0]
# 提交item
yield item
if self.start <= 225:
self.start += 25
yield scrapy.Request(self.url + str(self.start) + self.end, callback=self.parse)
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyRedisTestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class DoubanspiderItem(scrapy.Item):
# 电影标题
title = scrapy.Field()
# 电影评分
score = scrapy.Field()
# 电影信息
content = scrapy.Field()
# 简介
info = scrapy.Field()middlewares.py自动生成
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
class ScrapyRedisTestSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class ScrapyRedisTestDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
piplines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.conf import settings
import pymongo
import json
class ScrapyRedisTestPipeline(object):
def process_item(self, item, spider):
return item
class DoubanspiderPipeline(object):
def __init__(self):
# 获取setting主机名、端口号和数据库名
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbname = settings['MONGODB_DBNAME']
# pymongo.MongoClient(host, port) 创建MongoDB链接
client = pymongo.MongoClient(host=host,port=port)
# 指向指定的数据库
mdb = client[dbname]
# 获取数据库里存放数据的表名
self.post = mdb[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
data = dict(item)
# 向指定的表里添加数据
self.post.insert(data)
return item
class spider1JsonPipeline(object):
def __init__(self):
self.file = open('tiezi.json', 'wb')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + ",\n"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for scrapy_redis_test project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'scrapy_redis_test'
SPIDER_MODULES = ['scrapy_redis_test.spiders']
NEWSPIDER_MODULE = 'scrapy_redis_test.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'scrapy_redis_test (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'scrapy_redis_test.middlewares.ScrapyRedisTestSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'scrapy_redis_test.middlewares.ScrapyRedisTestDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'scrapy_redis_test.pipelines.ScrapyRedisTestPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 使用了scrapy-redis里的去重组件,不使用scrapy默认的去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用了scrapy-redis里的调度器组件,不实用scrapy默认的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 使用队列形式
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
# 允许暂停,redis请求记录不丢失
SCHEDULER_PERSIST = True
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'newdongguan (+http://www.yourdomain.com)'
USER_AGENT = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"
ITEM_PIPELINES = {
'scrapy_redis_test.pipelines.spider1JsonPipeline' : 401,
'scrapy_redis.pipelines.RedisPipeline' : 400,
}
MONGODB_DBNAME = 'db0'
MONGODB_HOST = '127.0.0.1'
MONGODB_PORT = 6379
FEED_EXPORT_ENCODING = 'utf-8'
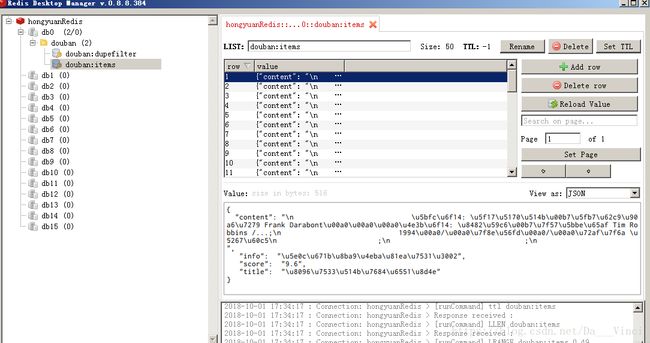
结果:
.json
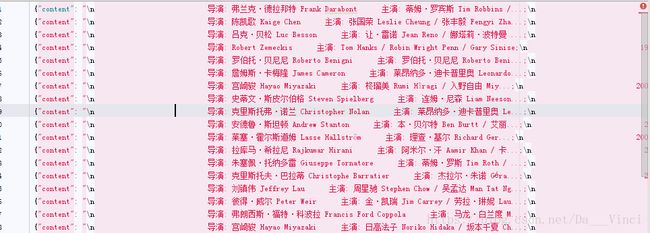
Redis库
有问题请留言
更多机会与学习资料,请加QQ群