HADOOP学习笔记总结三: HBASE
一、HADOOP生态系统
HBase是HADOOP的生态系统,是建立在Hadoop文件系统(HDFS)之上的分布式、面向列的数据库,通过利用Hadoop的文件系统提供容错能力。

二、HBase是什么
三、HBase处理数据
虽然Hadoop是一个高容错、高延时的分布式文件系统和高并发的批处理系统,但是它不适用于提供实时计算;HBase是可以提供实时计算的分布式数据库,数据被保存在HDFS分布式文件系统上,由HDFS保证其高容错性,但是再生产环境中,HBase是如何基于hadoop提供实时性呢? HBase上的数据是以StoreFile(HFile)二进制流的形式存储在HDFS上block块儿中;但是HDFS并不知道的HBase用于存储什么,它只把存储文件认为是二进制文件,也就是说,HBase的存储数据对于HDFS文件系统是透明的。
四、HBase与HDFS
在下面的表格中,我们对HDFS与HBase进行比较:
| HDFS | HBase |
|---|---|
| HDFS适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找。 | HBase提供在较大的表快速查找 |
| HDFS提供了高延迟批量处理;没有批处理概念。 | HBase提供了数十亿条记录低延迟访问单个行记录(随机存取)。 |
| HDFS提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。 |
五、HBASE数据模型
HBase通过表格的模式存储数据,每个表格由列和行组成,其中,每个列又被划分为若干个列族(row family)
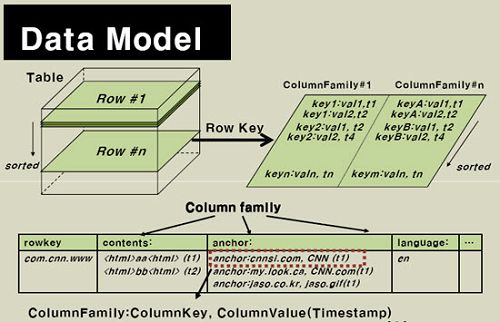
Hbase数据模型:
CELL单元格由rowkey、列、时间戳来决定,以字节码数组
HLog日志记录写入数据的归属信息
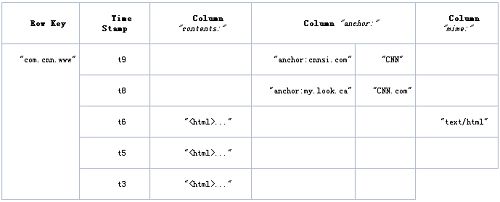
Hbase建议每个表列族最好 不要超过3个。

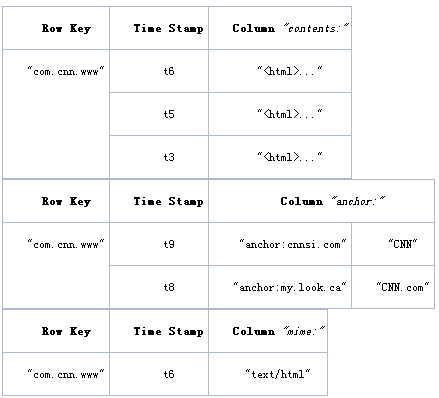
物理数据模型:
六、HBase架构
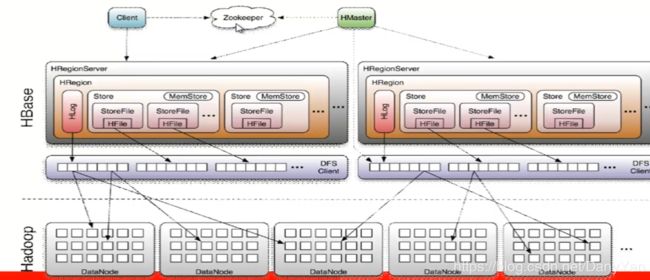
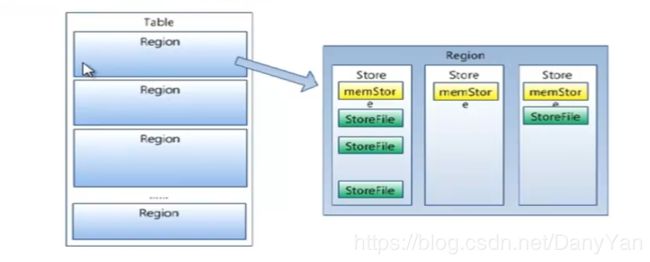

Hbase中的每张表都按照一定范围被分割成多个子表(HRegion),默认一个Hregion的某个列族超过256M就要被分割成两个(裂变),由HRegionServer来管理,而管理此HRegionServer具体管理哪些HRegion由Hmaster来分配。
具体组成部件的作用:
Client:包含访问的HBase的接口,并维护CACHE来加快对HBASE的访问。
Zookeeper:Hbase是需要依赖Zookeeper的,默认情况下HBase管理Zookeeper实例(启动或关闭Zookeeper),也可以通过配置注册到Zookeeper集群去。Master与RegionServers启动时会向Zookeeper注册。
zookeeper起如下作用:
- 保证任何时候,集群中只有一个master
- 存储所有Region的寻址入口
- 实时监控Region server的上线和下线信息。并实时通知给master
- 存储HBase的schema和table元数据
HRegionServer:用来维护Hmaster分配给他的region,处理对这些region的io请求;负责切分正在运行过程中变的过大的region。
HRegion:HBase表在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。Region按大小分隔,每个表一般是只有一个region,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
Store:每一个Region由一个或多个Store组成,至少是一个Store,HBase会把一起访问的数据放在一个Store里面,即为每个ColumnFamily建一个Store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者多个StoreFile组成。Store的大小被HBase用来判断是否需要切分Region。
StoreFile:memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存,以二进制形式保存在HDFS中。
Hlog:HLog记录数据的所有变更,可以用来恢复文件,一旦region server 宕机,就可以从log中进行恢复。
Hmaster:为regionserver分配region,发现失效的regionserver并重新分配其上的region,管理用户对talbe的增删改操作
官方文档:http://hbase.apache.org/book.html
五、表结构设计
参考https://blog.csdn.net/ymh198816/article/details/51244911
六、python操作HBASE
python连接操作HBASE的库有好多,在github上最多星的happyhbase,hbase-thrift这两个库,都是thrift的服务来实现对hbase的操作。所以Hadoop集成得开启THRIFT服务,给它设置后台运行(daemon模式)
happybase参考:https://blog.csdn.net/qq_34218221/article/details/80486475
hbase-thrift参考:https://blog.csdn.net/y472360651/article/details/79055875
七:安装与配置
http://abloz.com/hbase/book.html#standalone_dist
https://www.cnblogs.com/freeweb/p/5526080.html