CTR 预测理论(三):决策树家族之ID3, C4.5与CART总结
决策树之ID3, C4.5与CART区别
| 算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 |
|---|---|---|---|---|---|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
| CART | 分类,回归 | 二叉树 | 基尼系数,均方差 | 支持 | 支持 | 支持 |
本文将介绍一个简单常见的机器学习方法–决策树。包括但不限于:
- ID3
- C4.5
- CART
- 决策树剪枝
1. 决策树简介
什么是决策树呢?下面的图来自西瓜书,这就是一棵决策树,这个决策树用来判断一个瓜是否位好瓜。

对于一个瓜,首先看其纹理,
- 纹理模糊,说明是坏瓜
- 纹理稍糊,还得看其触感,如果触感硬滑为好瓜,触感软粘为坏瓜
- 纹理清晰,则接下来看根蒂….
可以看出,决策树是一个可解释性很强的模型,用数据结构里的树来描述的话,是一棵多叉树,其中间结点代表决策步骤,叶子结点代表决策结果(或者说类别标签),而从根结点到叶子结点则描述了我们决策的过程。
不过,如何训练决策树呢?给定训练数据,可能存在多棵能拟合数据的决策树,如果要求解全局最优的决策树,那么是一个NP问题,因此,我们往往采用贪心法建立次优决策树。
采用贪心法建立决策树的框架如下(采用分治法(Divide and conquer)递归的建树):

上图中,有2种情形使得递归返回,
- 情形1:即代码2-4行,当前结点的样本都属于同一类别,无需划分,递归返回
- 情形2:即代码5-7行,在当前属性集为空,或是所有样本在所有属性上取值都相同,无法进一步划分,所以返回
很简单是不是!我们只需要搞定第8行就可以了,如何选择最优划分属性呢?这就是不同贪心算法采用的不同策略了。
PS: 周志华的西瓜书中,认为第12行应该标记完然后return;我觉得是错误的。因为还有其它取值非空的Dv。因此这里我将图上的return去除了。
2. ID3与信息增益
一般而言,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的纯度越来越高。而ID3中采用信息增益来衡量“纯度”的变化,从而选择划分点。
信息论与概率统计中,熵(Entropy)用来表示随机变量不确定性的大小,熵越大,不确定性越大。(概率可以视为表示确定性大小,概率越大,确定性越大)
设随机变量 D 有 d 个取值 { a 1 , a 2 , ⋯ , a d } \{a_1,a_2,⋯,a_d\} {a1,a2,⋯,ad}, 取值为 a i a_i ai 的概率为 p i p_i pi, 则随机变量的熵定义为:
(2-1) H ( D ) = − ∑ i = 1 d p i log p i H(D) = -\sum_{i=1}^{d} p_i \log\ p_i \tag{2-1} H(D)=−i=1∑dpilog pi(2-1)
计算时约定当 p = 0 时, p i l o g p i = 0 p_i \ log \ p_i =0 pi log pi=0
应用在分类数据集中, p i p_i pi 可以表示第 i 个类别占总样本的比重。
接着介绍条件熵(conditional entropy),即给定随机变量 a 后,D 剩余的不确定性(熵):
(2-2) H ( D ∣ A ) = ∑ i = 1 d p ( A = a i ) H ( D ∣ A = a i ) H(D|A)= \sum_{i=1}^dp(A=a_i)H(D|A=a_i)\tag{2-2} H(D∣A)=i=1∑dp(A=ai)H(D∣A=ai)(2-2)
看不懂条件熵的式子?其实就是按特征A的取值划分数据,对取值为 a i a_i ai 的数据计算熵,然后乘以取值为 a i a_i ai 的概率。
信息增益(information gain)描述的是,给定随机变量 A 后,X 所减少的不确定性(即熵 – 条件熵):
(2-3) I G ( D ∣ A ) = H ( D ) – H ( D ∣ A ) IG(D|A) = H(D) – H(D | A) \tag{2-3} IG(D∣A)=H(D)–H(D∣A)(2-3)
一般而言,信息增益越大,说明选择属性 A 来进行划分所获得的“纯度”提升越大。因此,著名的ID3决策树学习算法就是用信息增益来划分属性的。
例子
以周志华的西瓜书中西瓜数据2.0为例:
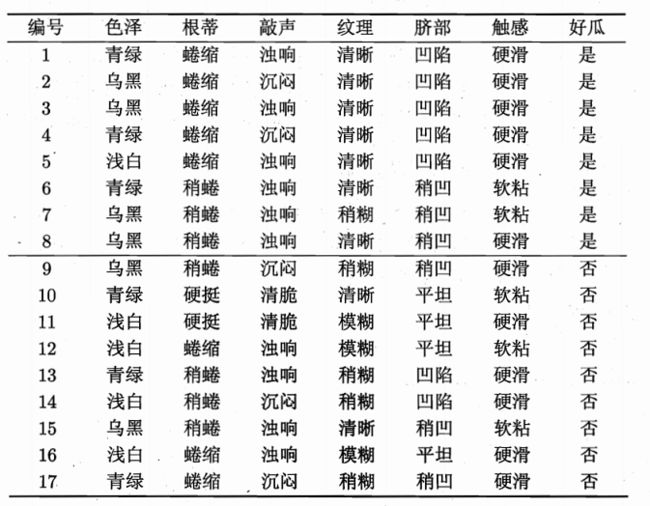
该数据共有17条,我们可以用这个数据来学习一棵判断一个瓜是否为好瓜的决策树。
首先看好瓜出现了8次,坏瓜出现了9次,因此可以用式2-1计算出根结点的熵为:
H ( D ) = − ∑ i = 1 2 p i log p i = – ( 8 17 log 2 8 17 + 9 17 log 2 9 17 ) = 0.998 H(D) =-\sum_{i=1}^2p_i\log p_i= – (\frac{8}{17}\log_2\frac{8}{17}+\frac{9}{17}\log_2\frac{9}{17}) = 0.998 H(D)=−i=1∑2pilogpi=–(178log2178+179log2179)=0.998
接着,查看可选取的特征有:{色泽、根蒂、敲声、纹理、脐部、触感}
先查看色泽特征,有三种取值,{青绿, 乌黑,浅白},
- 色泽为青绿的时候,有{1, 4, 6, 10, 13, 17} 6个样例,其中好瓜为{1,4,6}
- 色泽为乌黑时有{2, 3, 7, 8, 9, 15} 6个样例,其中好瓜为{2,3,7,8}
- 色泽为浅白时有{5, 11, 12, 14, 16} 5个样例,其中好瓜为{5}
因此我们用式子2-2计算条件熵:
H ( D ∣ 色 泽 ) = ∑ i = 1 3 p ( A = a i ) H ( D ∣ A = a i ) = p ( A = 青 绿 ) H ( D ∣ A = 青 绿 ) + p ( A = 乌 黑 ) H ( D ∣ A = 乌 黑 ) + p ( A = 浅 白 ) H ( D ∣ A = 浅 白 ) = 6 17 ( – ( 3 6 log 2 3 6 + 3 6 log 2 3 6 ) ) + 6 17 ( – ( 4 6 log 2 4 6 + 2 6 log 2 2 6 ) ) + 5 17 ( – ( 1 5 log 2 1 5 + 4 5 log 2 4 5 ) ) = 6 17 ∗ 1.000 + 6 17 ∗ 0.918 + 5 17 ∗ 0.722 = 0.8893 H(D | 色泽) = \sum_{i=1}^3p(A=a_i)H(D|A=a_i) \\ =p(A=青绿)H(D|A=青绿) +p(A=乌黑)H(D|A=乌黑)+p(A=浅白)H(D|A=浅白) \\ =\frac{6}{17}\left( – (\frac{3}{6}\log_2\frac{3}{6} + \frac{3}{6}\log_2\frac{3}{6}) \right) + \frac{6}{17}\left( – (\frac{4}{6}\log_2\frac{4}{6} + \frac{2}{6}\log_2\frac{2}{6}) \right) + \frac{5}{17}\left( – (\frac{1}{5}\log_2\frac{1}{5} + \frac{4}{5}\log_2\frac{4}{5}) \right)\\ =\frac{6}{17}*1.000 + \frac{6}{17}*0.918 + \frac{5}{17}*0.722\\ = 0.8893 H(D∣色泽)=i=1∑3p(A=ai)H(D∣A=ai)=p(A=青绿)H(D∣A=青绿)+p(A=乌黑)H(D∣A=乌黑)+p(A=浅白)H(D∣A=浅白)=176(–(63log263+63log263))+176(–(64log264+62log262))+175(–(51log251+54log254))=176∗1.000+176∗0.918+175∗0.722=0.8893
最后用2-3计算给定了色泽特征的信息增益:
I G ( D ∣ 色 泽 ) = H ( D ) – H ( D ∣ 色 泽 ) = 0.998 − 0.8893 = 0.109 IG(D|色泽) = H(D) – H(D | 色泽) = 0.998-0.8893=0.109 IG(D∣色泽)=H(D)–H(D∣色泽)=0.998−0.8893=0.109
同理计算出其它特征的信息增益,
I G ( D ∣ 根 蒂 ) = 0.143 ; I G ( D ∣ 敲 声 ) = 0.141 I G ( D ∣ 纹 理 ) = 0.381 ; I G ( D ∣ 脐 部 ) = 0.289 I G ( D ∣ 触 感 ) = 0.006 ; IG(D|根蒂) = 0.143;IG(D|敲声) =0.141\\ IG(D|纹理) = 0.381;IG(D|脐部) =0.289\\ IG(D|触感) = 0.006; IG(D∣根蒂)=0.143;IG(D∣敲声)=0.141IG(D∣纹理)=0.381;IG(D∣脐部)=0.289IG(D∣触感)=0.006;
因为纹理的信息增益最大,所以会选纹理作为这次的划分特征。
根据前面讲的决策树算法框架,会将数据集根据纹理的取值划分,
- 纹理清晰:{1, 2, 3, 4, 5, 6, 8, 10, 15}
- 纹理稍糊: {7, 9, 13, 14, 17}
- 纹理模糊: {11, 12, 16}
然后,建立递归的建立三棵子树,不过子树中就没有纹理特征了。
以纹理清晰的子树为例,有9个样例(设为D1用来和原始数据进行区分),
H ( D 1 ) = − ∑ i = 1 2 p i log p i = – ( 7 9 log 2 7 9 + 2 9 log 2 2 9 ) = 0.7642 H(D^1) =-\sum_{i=1}^2p_i\log p_i= – (\frac{7}{9}\log_2\frac{7}{9}+\frac{2}{9}\log_2\frac{2}{9}) =0.7642 H(D1)=−i=1∑2pilogpi=–(97log297+92log292)=0.7642
可以用{色泽、根蒂、敲声、脐部、触感}这五个特征计算信息增益,来选择信息增益最大的特征,从而进一步划分。
这里继续以色泽特征的信息增益计算为例:{1, 2, 3, 4, 5, 6, 8, 10, 15} 有三种取值,{青绿, 乌黑,浅白},
- 色泽为青绿的时候,有{1, 4, 6, 10} 4个样例,其中好瓜为{1, 4, 6}
- 色泽为乌黑时有{2, 3, 8, 15} 4个样例,其中好瓜为{2, 3, 8}
- 色泽为浅白时有{5} 1个样例,其中好瓜为{5}
H ( D 1 ∣ 色 泽 ) = ∑ i = 1 3 p ( A = a i ) H ( D 1 ∣ A = a i ) = p ( A = 青 绿 ) H ( D 1 ∣ A = 青 绿 ) + p ( A = 乌 黑 ) H ( D 1 ∣ A = 乌 黑 ) + p ( A = 浅 白 ) H ( D 1 ∣ A = 浅 白 ) = 4 9 ( – ( 3 4 log 2 3 4 + 1 4 log 2 1 4 ) ) + 4 9 ( – ( 3 4 log 2 3 4 + 1 4 log 2 1 4 ) ) + 1 9 ( – ( 1 1 log 2 1 1 + 0 1 log 2 0 1 ) ) = 4 9 ∗ 0.8113 + 4 9 ∗ 0.8113 + 1 9 ∗ 0 = 0.7215 H(D^1 | 色泽) = \sum_{i=1}^3p(A=a_i)H(D^1|A=a_i) \\ =p(A=青绿)H(D^1|A=青绿) +p(A=乌黑)H(D^1|A=乌黑)+p(A=浅白)H(D^1|A=浅白) \\ =\frac{4}{9}\left( – (\frac{3}{4}\log_2\frac{3}{4} + \frac{1}{4}\log_2\frac{1}{4}) \right) + \frac{4}{9}\left( – (\frac{3}{4}\log_2\frac{3}{4} + \frac{1}{4}\log_2\frac{1}{4}) \right) + \frac{1}{9}\left( – (\frac{1}{1}\log_2\frac{1}{1} + \frac{0}{1}\log_2\frac{0}{1}) \right)\\ =\frac{4}{9}*0.8113 + \frac{4}{9}*0.8113 + \frac{1}{9}*0\\ = 0.7215 H(D1∣色泽)=i=1∑3p(A=ai)H(D1∣A=ai)=p(A=青绿)H(D1∣A=青绿)+p(A=乌黑)H(D1∣A=乌黑)+p(A=浅白)H(D1∣A=浅白)=94(–(43log243+41log241))+94(–(43log243+41log241))+91(–(11log211+10log210))=94∗0.8113+94∗0.8113+91∗0=0.7215
因此信息增益为:
I G ( D 1 ∣ 色 泽 ) = H ( D 1 ) – H ( D 1 ∣ 色 泽 ) = 0.7642 − 0.7215 = 0.043 IG(D^1|色泽) = H(D^1) – H(D^1 | 色泽) = 0.7642-0.7215=0.043 IG(D1∣色泽)=H(D1)–H(D1∣色泽)=0.7642−0.7215=0.043
类似可以算出其它的信息增益,然后选最大进行划分。
最终的决策树即为本文一开始给出的图,这里再贴出来方便读者查看:
3. C4.5
ID3有一些不足的地方:
- 选择分裂变量时会倾向于选择类别较多的变量
- 只能处理类别变量,不能处理连续性变量(实数的)
- 不能处理缺失值
下面来看看C4.5是如何改进的。
3.1 增益率
信息增益对可取值数目较多的特征有所偏好(你可以想象极端情况,只有一个取值的时候,信息增益为0),为减少这种偏好的影响,C4.5决策树算法采用增益率:
(3-1) G a i n _ r a t i o ( D ∣ A ) = I G ( D ∣ A ) H ( A ) = H ( D ) – H ( D ∣ A ) H ( A ) {\rm Gain\_ratio}(D|A) = \frac{IG(D|A)}{H(A)} \tag{3-1} = \frac{H(D) – H(D | A) }{H(A)} Gain_ratio(D∣A)=H(A)IG(D∣A)=H(A)H(D)–H(D∣A)(3-1)
2-4只有分母是仿佛我们没见过的?其实就是特征A的熵,之前我们计算H(D)是按D的类别(好瓜、坏瓜),而H(A)则按A的取值来计算。
如以上面的样例数据,再次以色泽为例,
H ( 色 泽 ) = − ∑ i = 1 3 p i log 2 p i = − ( 6 17 log 2 6 17 + 6 17 log 2 6 17 + 5 17 log 2 5 17 ) = 1.580 H(色泽) = -\sum_{i=1}^3p_i\log_2p_i = -(\frac{6}{17}\log_2\frac{6}{17} + \frac{6}{17}\log_2\frac{6}{17}+\frac{5}{17}\log_2\frac{5}{17}) = 1.580 H(色泽)=−i=1∑3pilog2pi=−(176log2176+176log2176+175log2175)=1.580
注意的是,增益率对可取值数目较少的特征有所偏好,因此 C4.5 并不是直接选取增益率最大的特征作为划分,而是先从候选特征中找出信息增益高于平均水平的特征,然后再从中选出增益率最高的。
注:使用信息增益与使用信息增益率作为属性选择的差别:从信息增益的定义式不难发现,若以信息增益作为属性选择依据,则该决策树生成时更倾向于选择可取值数目较多的属性(西瓜书中也有 “实际上,信息增益准则对可取值数目较多的属性有所偏好”).因此C4.5决策树算法作为ID3决策树算法的改进版,引入增益率,来消除这种不利影响,但“增益率准则对可取数目较少的属性有所偏好”,
因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找到信息增益高于平均水平的属性,在从中选择增益率最高的。“
3.2 连续变量处理
C4.5 中,处理连续变量的方法是对连续变量离散化。
如我们有一个连续的特征 A,共有 n 个不同的取值,将这些取值从小到大进行排序,得到: { a 1 , a 2 , … , a n } \{a_1,a_2,…,a_n\} {a1,a2,…,an}
这样,可以在相邻的取值 a i a^i ai 和 a i + 1 a^{i+1} ai+1 中间点 t 处进行切分,将数据划分为两部分,一部分小于等于 t,另一部分大于 t。
可能的划分点有n-1种: t ∈ { a 1 + a 2 2 , a 2 + a 3 2 , ⋯ , a n − 1 + a n 2 } t \in \{\frac{a_1 + a_2}{2},\frac{a_2 + a_3}{2},\cdots,\frac{a_{n-1} + a_n}{2} \} t∈{2a1+a2,2a2+a3,⋯,2an−1+an}
这样,在 n – 1 个取值中选择最优划分点即可。
例如对 信息增益 Gain 进行改造:
G a i n ( D , a ) = m a x t ∈ T a G a i n ( D , a , t ) = m a x t ∈ T a E n t ( D ) − ∑ λ ∈ { − , + } ∣ D t λ ∣ ∣ D ∣ E n t ( D t λ ) Gain(D, a) = max_{t \in T_a} Gain(D,a,t) = max_{t \in T_a} Ent(D) - \sum_{\lambda \in \{-,+\} \frac{|D_t^{\lambda}|}{|D|}}Ent(D_t^{\lambda}) Gain(D,a)=maxt∈TaGain(D,a,t)=maxt∈TaEnt(D)−λ∈{−,+}∣D∣∣Dtλ∣∑Ent(Dtλ)
其中 G a i n ( D , a , t ) Gain(D,a,t) Gain(D,a,t) 是样本集 D 基于划分点 t 进行二分后的信息增益。于是,我们可选择使 Gain(D,a,t) 最大化的划分点。(例子可参考西瓜书 P84。)
注:
- C4.5 虽然可以处理连续变量,但是其连续变量处理方式与 CART 不同,C4.5 依旧是采用将连续变量离散化,作为离散变量看待,进行左右切分计算信息增益率,而后进行分支的(结合其分支策略,C4.5 对连续属性切分一律也是二分叉)。
- 其次,C4.5 与 ID3 相同,都是多叉树,虽然 C4.5 对连续属性进行地是二分叉,但是对离散属性还是先求分类所对应信息增益率,选出信息增益率最大的分类属性进行划分,该分类属性有几种分类取值,就对应有几种分叉,因此 C4.5 也是多叉树,这点与 CART 有明显区别,CART 对分类,按照属性取值进行分类,左分支取值是,右分支取值否;对连续属性也是首先对连续属性进行离散化,再排序划分,但划分依据不再是修正后的信息增益准则,而是采用回归树平方误差损失求解最优的切分特征 j 和切分点 s:
(4-3) min j , s [ min c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + min c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 ] \min_{j, s} \left[ \min_{c_1} \sum_{x_i \in R_1(j, s)} (y_i -c_1)^2 + \min_{c_2} \sum_{x_i \in R_2(j, s)} (y_i -c_2)^2 \right ] \tag{4-3} j,smin⎣⎡c1minxi∈R1(j,s)∑(yi−c1)2+c2minxi∈R2(j,s)∑(yi−c2)2⎦⎤(4-3)- 对 C4.5 连续属性划分需要注意的是,与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性,只是分割阈值不同。如下图所示的一颗决策树,“含糖率”这个属性在根节点用了一次,后代结点也用了一次,只是两次划分点取值不同。
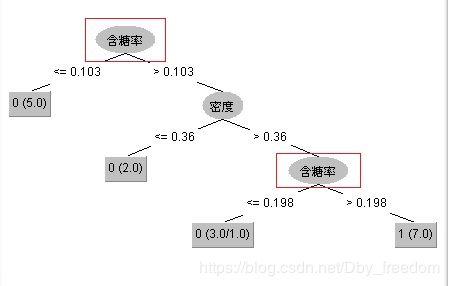
3.3 缺失值处理
在真实数据中,往往会遇到不完整的样本,即样本中某些特征式缺失的。那么要如何处理呢?
要处理缺失值,需要解决两个问题:
- 如何在属性值缺失的情况下进行划分属性选择?
- 给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
给定训练数据集 D 和属性 a,令 D ~ \tilde{D} D~ 表示 D 中在属性 a 上没有缺失值的样本子集。对于问题1,我们尽可根据 D ~ \tilde{D} D~ 来判断属性 a 的优劣,假定 a 有 V 个可取值 { a 1 , a 2 , ⋯ , a V } \{a^1,a^2,\cdots,a^V\} {a1,a2,⋯,aV},令 D ~ v \tilde{D}^v D~v 表示 D ~ \tilde{D} D~ 中在属性 a 上取值为 a v a^v av 的样本, D ~ k \tilde{D}_k D~k 表示 D ~ \tilde{D} D~ 中属于第 k 类的样本子集,则显然有 D ~ = ⋃ k = 1 K D ~ k = ⋃ v = 1 V D ~ v \tilde{D} = \bigcup_{k=1}^K\tilde{D}_k = \bigcup_{v=1}^V\tilde{D}^v D~=⋃k=1KD~k=⋃v=1VD~v
假定我们为每个样本 x 赋予一个权重 w x w_x wx,并定义
ρ = ∑ x ∈ D ~ w x ∑ x ∈ D w x p ~ k = ∑ x ∈ D ~ k w x ∑ x ∈ D ~ w x r ~ v = ∑ x ∈ D ~ v w x ∑ x ∈ D ~ w x \rho = \frac{\sum_{x \in \tilde{D}}w_x}{\sum_{x \in D}w_x}\\ \tilde{p}_k = \frac{\sum_{x \in \tilde{D}_k}w_x}{\sum_{x \in \tilde{D}}w_x}\\ \tilde{r}_v = \frac{\sum_{x \in \tilde{D}^v}w_x}{\sum_{x \in \tilde{D}}w_x} ρ=∑x∈Dwx∑x∈D~wxp~k=∑x∈D~wx∑x∈D~kwxr~v=∑x∈D~wx∑x∈D~vwx
直观上看,对属性 a,
- ρ \rho ρ 表示无缺失值样本所占的比例
- p ~ k \tilde{p}_k p~k表示无缺失样本中第 k 类的比例
- r ~ v \tilde{r}_v r~v 表示无缺失样本在属性 a 上取值 a v a^v av 的样本所占的比例
显然 ∑ k = 1 K p ~ k = 1 ; ∑ v = 1 V r ~ v = 1 \sum_{k=1}^K\tilde{p}_k=1; \ \sum_{v=1}^V\tilde{r}_v =1 ∑k=1Kp~k=1; ∑v=1Vr~v=1
基于上述定义,可以将信息增益2-3推广为
G a i n ( D , a ) = ρ × G a i n ( D ~ , a ) = ρ × ( H ( D ~ ) – ∑ v = 1 V r ~ v H ( D ~ v ) ) ) H ( D v ~ ) = − ∑ k = 1 K p ~ k log 2 p ~ k Gain(D, a) =\rho \times Gain(\tilde{D}, a) = \rho\times\left( H(\tilde{D}) – \sum_{v=1}^V\tilde{r}_vH(\tilde{D}^v)) \right)\\ H(\tilde{D^v})= -\sum_{k=1}^K \tilde{p}_k \log_2 \tilde{p}_k Gain(D,a)=ρ×Gain(D~,a)=ρ×(H(D~)–v=1∑Vr~vH(D~v)))H(Dv~)=−k=1∑Kp~klog2p~k
其实上式和原来的差不多,只是计算熵和条件熵的时候,采用的是没有缺失的样本子集 D ~ \tilde{D} D~,并且是加权的结果,然后最后信息增益乘以 D ~ \tilde{D} D~ 占 D D D 的加权比重
对于问题2
- 若样本 x 在划分属性 a 上的取值已知,则将 x 划入与其取值对应的子结点。
- 取值未知,则将 x 同时划入所有的子结点,且样本权值在属性值 a v a^v av 对应的子结点调整为 r ~ v ⋅ w x \tilde{r}_v \cdot w_x r~v⋅wx,即让同一个样本以不同的概率划入不同的子结点中
例子
下面的例子以西瓜数据2.0α为例:

学习开始时,根节点包含全部17个样本,各个样例的权值为1。以特征色泽为例,无缺失的有14个样本,其中,包含正例6个,负例8个。因此:
H ( D v ~ ) = − ∑ k = 2 K p ~ k log 2 p ~ k = − ( 6 14 log 2 6 14 + 8 14 log 2 8 14 ) = 0.985 H(\tilde{D^v}) = -\sum_{k=2}^K \tilde{p}_k \log_2 \tilde{p}_k \\ = -(\frac{6}{14}\log_2\frac{6}{14}+\frac{8}{14}\log_2\frac{8}{14}) = 0.985 H(Dv~)=−k=2∑Kp~klog2p~k=−(146log2146+148log2148)=0.985
D ~ 1 , D ~ 2 , D ~ 3 \tilde{D}^1,\tilde{D}^2,\tilde{D}^3 D~1,D~2,D~3 分别表示特征色泽上取值为“青绿”,“乌黑”,以及“浅白”的样本子集,有:
H ( D 1 ~ ) = − ( 2 4 log 2 2 4 + 2 4 log 2 2 4 ) = 1.000 H ( D 2 ~ ) = − ( 4 6 log 2 4 6 + 2 6 log 2 2 6 ) = 0.918 H ( D 3 ~ ) = − ( 0 4 log 2 0 4 + 4 4 log 2 4 4 ) = 0.000 H(\tilde{D^1}) = -(\frac{2}{4}\log_2\frac{2}{4}+\frac{2}{4}\log_2\frac{2}{4}) = 1.000\\ H(\tilde{D^2}) = -(\frac{4}{6}\log_2\frac{4}{6}+\frac{2}{6}\log_2\frac{2}{6}) = 0.918\\ H(\tilde{D^3}) = -(\frac{0}{4}\log_2\frac{0}{4}+\frac{4}{4}\log_2\frac{4}{4}) = 0.000 H(D1~)=−(42log242+42log242)=1.000H(D2~)=−(64log264+62log262)=0.918H(D3~)=−(40log240+44log244)=0.000
因此,样本子集 D ~ \tilde{D} D~ 上属性“色泽”的信息增益为 :
G a i n ( D , a ) = ρ × ( H ( D ~ ) – ∑ v = 1 V r ~ v H ( D ~ v ) ) ) = 14 17 ∗ ( 0.985 – ( 4 14 ∗ 1 + 6 14 ∗ 0.918 + 4 14 ∗ 0 ) ) = 14 17 ∗ 0.306 = 0.252 Gain(D, a) = \rho\times\left( H(\tilde{D}) – \sum_{v=1}^V\tilde{r}_vH(\tilde{D}^v)) \right)\\ = \frac{14}{17} *\left(0.985 – (\frac{4}{14} * 1+\frac{6}{14} * 0.918+ \frac{4}{14}* 0) \right)\\ = \frac{14}{17} * 0.306 = 0.252 Gain(D,a)=ρ×(H(D~)–v=1∑Vr~vH(D~v)))=1714∗(0.985–(144∗1+146∗0.918+144∗0))=1714∗0.306=0.252
其它类别依次类推。最后发现纹理取得最大信息增益。
- {1, 2, 3, 4, 5, 6, 15}进入纹理= 清晰分支
- {7, 9, 13, 14, 17} 进入纹理= 稍糊分支
- {11, 12, 16}进入纹理=模糊分支
- 对于编号8的样本,它缺失,因此同时进入三个分支中,但权重分别调整为 7 15 , 5 15 , 3 15 \frac{7}{15},\frac{5}{15},\frac{3}{15} 157,155,153,编号10同理。
- 这里计算采用的是计算修正后的信息增益,而 ID3 是不支持缺失值分类的,C4.5 才支持,而 C4.5 计算应该采用的是修正后的信息增益率(上述计算是用的修正的信息增益,没有考虑划分属性的熵),这里是为了与西瓜书保持一致。
- 其次,值得注意的是,上述只是对训练过程出现缺省值进行了处理,当预测值出现缺失值时呢?目前的处理步骤是对测试数据,进行预测前先进行缺省值处理(如采用平均数填充、众数、中位数填充等方式),再调用树模型进行分类、回归预测。
3.4 C4.5 算法不足
C4.5虽然改进或者改善了ID3算法的几个主要的问题,仍然有优化的空间。
-
由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,C4.5的剪枝方法有优化的空间。思路主要是两种,一种是预剪枝,即在生成决策树的时候就决定是否剪枝。另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝。后面在下篇讲CART树的时候我们会专门讲决策树的减枝思路,主要采用的是后剪枝加上交叉验证选择最合适的决策树。
-
C4.5生成的是多叉树,即一个父节点可以有多个节点。很多时候,在计算机中二叉树模型会比多叉树运算效率高。如果采用二叉树,可以提高效率。
-
C4.5只能用于分类,如果能将决策树用于回归的话可以扩大它的使用范围。
-
C4.5由于使用了熵模型,里面有大量的耗时的对数运算,如果是连续值还有大量的排序运算。如果能够加以模型简化可以减少运算强度但又不牺牲太多准确性的话,那就更好了。
4. CART算法
CART算法想必你也有所耳闻,其全称为classification and regression tree,即分类与回归树。从这个名字就可以发现它很强大,因为它可分类可回归!
CART基本上和之前的决策树算法框架相同,不过CART假设决策树为二叉树,左边分支为取值“是”, 右边分支取值为”否“。此外,其划分的策略也不是信息增益或信息增益率。
这点十分值得注意:CART 算法特性:1. 既可分类,又可做回归;2. CART 树特指二叉树(对比 ID3, C4.5 均为多分支树)
4.1 分类树生成
对于分类问题,采用基尼指数(Gini index)来判断分界点。假设有 K 个类,属于第 k 个类的概率为 p k p_k pk,则基尼指数为:
(4-1) G i n i ( D ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 {\rm Gini(D)}= \sum_{k=1}^Kp_k(1-p_k) = 1 -\sum_{k=1}^Kp_k^2\tag{4-1} Gini(D)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2(4-1)
基尼指数反应了从数据集中抽取两个样本,其类别不一致的概率。因此Gini(D)越小,则数据集的纯度越高。也可以说,Gini(D)越大表示了集合D的不确定性越大。因此,划分的时候我们采用的是基尼指数最小的属性作为划分属性。
基尼指数可以明显看出其表征类别不一致的概念,而熵也是表示平均不确定性,两者是近似的,但用基尼系数进行表征,可以大大减少计算量,这是基尼系数的优势所在,具体推导可参考下文。
若在特征 A 的条件下,样本 D 根据特征 A 的某一可能取值a被分割为 D 1 = { ( x , y ) ∈ D ∣ A ( x ) = a } , D 2 = D − D 1 D_1=\{(x,y) \in D|A(x) = a\},\ D_2=D-D_1 D1={(x,y)∈D∣A(x)=a}, D2=D−D1,集合D的基尼指数定义为:
(4-2) G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) {\rm Gini(D, A)} = \frac{|D_1|}{|D|}{\rm Gini(D_1)} + \frac{|D_2|}{|D|}{\rm Gini(D_2)}\tag{4-2} Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)(4-2)
4-2是不是和条件熵2-2也很类似? 关于基尼指数和熵的关系可以看下图(图来自李航老师):
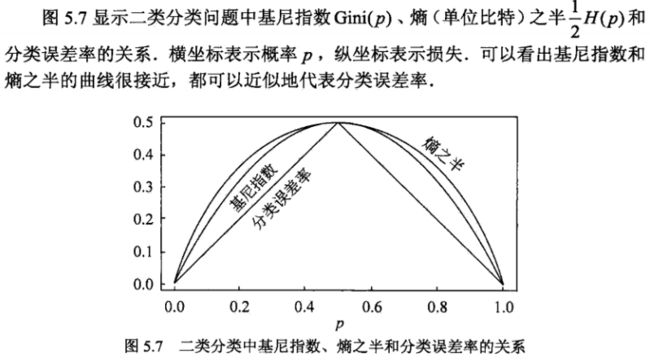
可以看出二者非常接近,此外,我们可以在 p i = 1 p_i=1 pi=1 对 − l o g p i −log \ p_i −log pi 进行泰勒展开:
f ( p i ) = − log p i f ( p i ’ ) = f ( p i ) + f ′ ( p i ) ( p i − 1 ) = f ( 1 ) + f ′ ( 1 ) ( p i − 1 ) = 1 − p i f(p_i) = -\log p_i\\ f(p_i’) = f(p_i) + f'(p_i)(p_i-1) = f(1) +f'(1) (p_i-1) = 1-p_i f(pi)=−logpif(pi’)=f(pi)+f′(pi)(pi−1)=f(1)+f′(1)(pi−1)=1−pi
带入信息熵得:
∑ i p i log p i ≈ ∑ i p i ( 1 − p i ) \sum_{i} p_i\log p_i \approx \sum_i p_i(1-p_i) i∑pilogpi≈i∑pi(1−pi)
即基尼系数!虽说他们数值上接近,但是gini的计算相比熵要简单的多,所以会更加的高效。
对于分类树和ID3的算法基本上相同,不过CART是二叉树,因此不像之前按特征划分,而是按特征取值划分。
- 对于给定的结点数据集为 D,对于每一个特征 A,对其所有可能的取值 a,根据样本点对 A=a 的测试为“是”或“否”将 D 分割成 D 1 , D 2 D_1, \ D_2 D1, D2两部分,利用4-2计算 A=a 的基尼系数,从中选取基尼系数最小的特征以及对应的切分点作为最优特征与最优切分点,从现结点生成两个子结点,将训练数据集分配到两个子结点中去。
- 类似之前的算法递归调用步骤1直到满足停止条件即可。
可以看出,CART由于每次都是二分裂(划分成两部分),不像ID3是多分裂的,因此也没有ID3的倾向于取值较多的变量的缺陷。
4.2 回归树生成
回归树采用平方误差最小化为准则。
如何做呢?选择第j个特征x(j)和它的取值s,作为切分变量和切分点,并定义两个区域:
R 1 ( j , s ) = { x ∣ x ( j ) ≤ s } R 2 ( j , s ) = { x ∣ x ( j ) > s } R_1(j,s) = \{x|x^{(j)} \le s\} \\ R_2(j,s) = \{x|x^{(j)} \gt s\} R1(j,s)={x∣x(j)≤s}R2(j,s)={x∣x(j)>s}
PS: 这里真实中一般不直接用取值s来作为切分点,而先把特征的取值排序 { v 1 , v 2 , ⋯ , v n } \{v_1,v_2,\cdots,v_n\} {v1,v2,⋯,vn},然后可能的阈值有: { v 1 + v 2 2 , v 2 + v 3 2 , ⋯ , v n − 1 + v n 2 } \{\frac{v_1 + v_2}{2},\frac{v_2 + v_3}{2},\cdots,\frac{v_{n-1} + v_n}{2} \} {2v1+v2,2v2+v3,⋯,2vn−1+vn}。这里和C4.5中处理连续变量的方法一样。
然后采用平方误差损失求解最优的切分特征j 和切分点s:
(4-3) min j , s [ min c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + min c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 ] \min_{j, s} \left[ \min_{c_1} \sum_{x_i \in R_1(j, s)} (y_i -c_1)^2 + \min_{c_2} \sum_{x_i \in R_2(j, s)} (y_i -c_2)^2 \right ] \tag{4-3} j,smin⎣⎡c1minxi∈R1(j,s)∑(yi−c1)2+c2minxi∈R2(j,s)∑(yi−c2)2⎦⎤(4-3)
其中 c 1 , c 2 c_1,c_2 c1,c2 为对应的 R1,R2 部分的均值。
c ^ m = 1 N m ∑ x i ∈ R m ( j , s ) y i , x ∈ R m , m = 1 , 2 \hat c_m = {1\over N_m}\sum_{x_i\in R_m(j,s)}y_i , \quad x\in R_m , m=1,2 c^m=Nm1xi∈Rm(j,s)∑yi,x∈Rm,m=1,2
根据划分的区域递归的继续进行划分,最后就得到了回归树。
回归树例子
假设数据的特征就一个(就不用比较各个特征了),数据如下:
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.70 | 5.91 | 6.40 | 6.80 | 7.05 | 8.90 | 8.70 | 9.00 | 9.05 |
可以考虑划分点{1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5},以s = 1.5为例,此时对应的c1= 5.56, c2=7.50
这里开挂用python代码计算剩下的:
import numpy as np
data = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])
for k in range(len(data) - 1):
left = data[:k + 1]
right = data[k + 1:]
left_mean = left.mean()
right_mean = right.mean()
left_error = np.sum([(left_mean - x) ** 2 for x in left])
right_error = np.sum([(right_mean - x) ** 2 for x in right])
mean_error = (left_error + right_error)
print(k + 1.5, left, right, 'mean_error={0:5.2f} c1={1:5.2f} c2={2:5.2f}'.format(mean_error, left_mean, right_mean))
"""
1.5 [ 5.56] [ 5.7 5.91 6.4 6.8 7.05 8.9 8.7 9. 9.05] mean_error=15.72 c1= 5.56 c2= 7.50
2.5 [ 5.56 5.7 ] [ 5.91 6.4 6.8 7.05 8.9 8.7 9. 9.05] mean_error=12.08 c1= 5.63 c2= 7.73
3.5 [ 5.56 5.7 5.91] [ 6.4 6.8 7.05 8.9 8.7 9. 9.05] mean_error= 8.37 c1= 5.72 c2= 7.99
4.5 [ 5.56 5.7 5.91 6.4 ] [ 6.8 7.05 8.9 8.7 9. 9.05] mean_error= 5.78 c1= 5.89 c2= 8.25
5.5 [ 5.56 5.7 5.91 6.4 6.8 ] [ 7.05 8.9 8.7 9. 9.05] mean_error= 3.91 c1= 6.07 c2= 8.54
6.5 [ 5.56 5.7 5.91 6.4 6.8 7.05] [ 8.9 8.7 9. 9.05] mean_error= 1.93 c1= 6.24 c2= 8.91
7.5 [ 5.56 5.7 5.91 6.4 6.8 7.05 8.9 ] [ 8.7 9. 9.05] mean_error= 8.01 c1= 6.62 c2= 8.92
8.5 [ 5.56 5.7 5.91 6.4 6.8 7.05 8.9 8.7 ] [ 9. 9.05] mean_error=11.74 c1= 6.88 c2= 9.03
9.5 [ 5.56 5.7 5.91 6.4 6.8 7.05 8.9 8.7 9. ] [ 9.05] mean_error=15.74 c1= 7.11 c2= 9.05
"""
可以看出,选6.5的时候最小,因此选6.5作为划分点。因此得到回归树 T 1 T_1 T1 为:
T 1 ( x ) = { 6.24 , x ≤ 6.5 8.91 , x > 6.5 T_1(x) = \begin{cases} 6.24, & x\le 6.5 \\ 8.91, & x \gt 6.5 \\ \end{cases} T1(x)={6.24,8.91,x≤6.5x>6.5
接下来对 R 1 R_1 R1 和 R 2 R_2 R2 区域做同样的操作直到达到终止条件即可。
假如树的深度多允许为2,则最后的回归树为
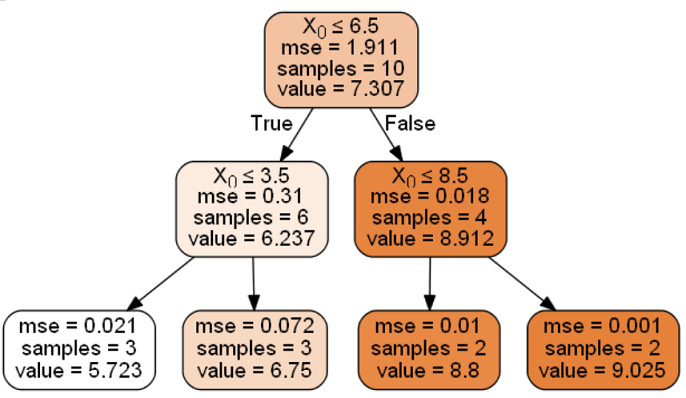
PS: 使用下面的代码生成``
import numpy as np
from sklearn.tree import DecisionTreeRegressor
X = np.arange(1, 11).reshape(-1, 1)
y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])
tree = DecisionTreeRegressor(max_depth=2).fit(X, y)
# import os
# os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
from sklearn.externals.six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = export_graphviz(tree, out_file=None,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
回归树的空间划分
在上面的例子中,可以画出对应的回归为:

对应的python代码为``
import matplotlib.pyplot as plt
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black", c="darkorange", label="data")
plt.plot(X, tree.predict(X), color="cornflowerblue", label="regression tree", linewidth=2)
plt.xlabel("X")
plt.ylabel("Y")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
可以看出,一个回归树对应着输入空间(特征空间)的一个划分以及在划分的单元上的输出值。上图就是对输入空间 X 的划分。假设已经将输入空间划分为 K 个单元 R 1 , R 2 , … , R K R_1, R_2, \ldots, R_K R1,R2,…,RK, 在每个单元 R k R_k Rk 上有个固定的输出 c k c_k ck, 则回归树可以表示为:
(4-4) f ( X ) = ∑ k = 1 K c k I ( X ∈ R k ) f(\mathbf{X}) = \sum_{k=1}^K c_k I(\mathbf{X} \in R_k) \tag{4-4} f(X)=k=1∑KckI(X∈Rk)(4-4)
式4-4就是回归树比较数学的表示方法。比如上面的例子, x ∈ ( 3.5 , 6.5 ] ) x \in (3.5, 6.5]) x∈(3.5,6.5]) 时值就是6.75。可以看出各个划分空间是不相交的。
当输入空间的划分确定时,可以用平方误差 ∑ x i ∈ R k ( y i – f ( x i ) ) 2 \sum_{x_i \in R_k}(y_i – f(x_i))^2 ∑xi∈Rk(yi–f(xi))2 来表示回归树对于训练数据的预测误差,显然,单元 R k R_k Rk 上的 c k c_k ck 的 k 最优值是 R k R_k Rk 上所有输入实例 x i x_i xi 对应的 y i y_i yi 的均值。
从这点也更容易看出 决策树 是一种生成模型,是 基于数据的,数据量越大,其预测精度空间越完整,预测准度越大,但是也正是这个特点,决策树算法并未对数据进行建模,而是一种特征空间切分,仅适用于预测数据涵盖在训练空间中(即内插),而不适用于预测 “未曾见识过的数据”(外插);
而作为对比 LR,则是典型地对数据进行建模拟合,不仅适用于内插数据,也适用于外插数据,这类对数据进行建模的方式的优化算法也基本都是采用梯度下降(包括神经网络、SVM等)。
4.3 CART 树不足
看起来CART算法高大上,那么CART算法还有没有什么缺点呢?有!主要的缺点我认为如下:
- 应该大家有注意到,无论是ID3, C4.5还是CART,在做特征选择的时候都是选择最优的一个特征来做分类决策,但是大多数,分类决策不应该是由某一个特征决定的,而是应该由一组特征决定的。这样决策得到的决策树更加准确。这个决策树叫做多变量决策树(multi-variate decision tree)。在选择最优特征的时候,多变量决策树不是选择某一个最优特征,而是选择最优的一个特征线性组合来做决策。这个算法的代表是OC1,这里不多介绍。
- 如果样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习里面的随机森林之类的方法解决。
4.4 CART 算法小结
上面我们对 CART 算法做了一个详细的介绍,CART 算法相比 C4.5 算法的分类方法,采用了简化的二叉树模型,同时特征选择采用了近似的基尼系数来简化计算。当然 CART 树最大的好处是还可以做回归模型,这个 C4.5 没有。下表给出了 ID3,C4.5 和 CART 的一个比较总结。希望可以帮助大家理解。
| 算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 |
|---|---|---|---|---|---|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
| CART | 分类,回归 | 二叉树 | 基尼系数,均方差 | 支持 | 支持 | 支持 |
5. 决策树剪枝
决策树的生成算法递归的产生决策树,直到满足终止条件位置。产生的决策树可能过于复杂,对训练数据分类准确,但是对未知样本可能准确性不高。换句话说,决策树算法容易过拟合。为了防止过拟合,可以通过剪枝算法来降低复杂度,减少过拟合的风险。
决策树剪枝算法的基本策略有”预剪枝“和”后剪枝“两种策略。基本思路是极小化损失函数。
- 预剪枝即在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能的提升,则停止划分当前结点,并标记为叶结点。
- 后剪枝是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该节点对应的子树替换为叶子结点能带来决策树的泛化性能提升,则将该子树替换为叶子结点。
上面的泛化性能考察,就要求我们对数据集划分,比如划分一部分为训练集,另一部分为验证集。然后考察在验证集上的准确率。
因此,我们划分出新的数据如下表,双线上部分为训练集,双线下部分为验证集
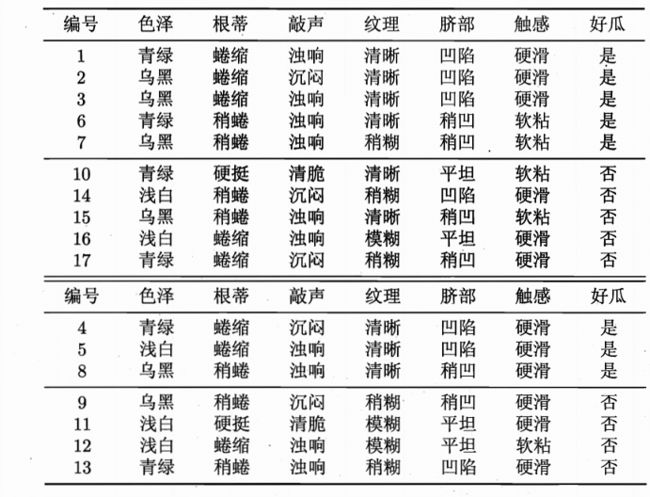
如果不经过剪枝,训练出来的决策树如下:
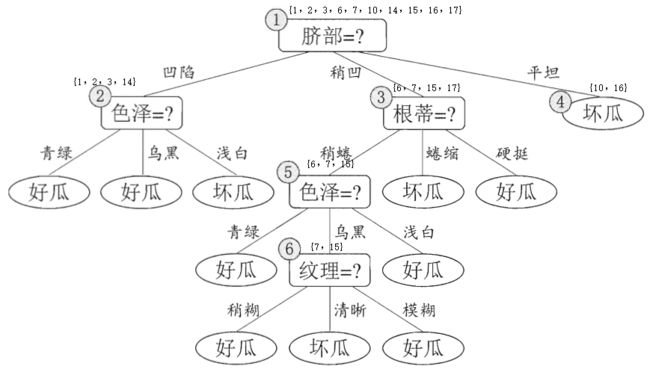
假设采用信息增益作为划分依据,现在来看看预剪枝和后剪枝怎么做的。
5.1 预剪枝
在不剪枝的做法中,我们根据信息增益准则,选取信息增益最大的脐部特征来进行划分,并产生3个分支。
而在预剪枝的过程中,我们需要看用脐部进行划分是否能提升泛化性能。
- 若不划分,根结点被标记为叶子结点,类别为最多的类别,即设为正例”好瓜”(这个训练集中正例=负例,因此随便选一类都可以),则验证集的7个样本中有3个样本正确分类,因此,精度为3 / 7 * 100% = 42.9%
- 进行划分,
- 结点2,包含编号{1, 2, 3, 14} => 好瓜
- 结点3,包含编号{6, 7, 15, 17} =>好瓜
- 结点4,包含编号{10, 16} =>坏瓜
- 在测试集中,根据脐部特征的取值到相应的结点上,如编号4的验证数据为“凹陷”就到2号结点上,为好瓜。以此类推有{4,5,8,11,12}5个样本分类正确,因此精度为5 / 7 * 100% = 71.4%
- 因为划分后的精度(71.4%)比不划分的(42.9%)高,所以进行划分。
对之后的结点2,3,4是否划分采用类似的过程。最后的决策树如下图所示:
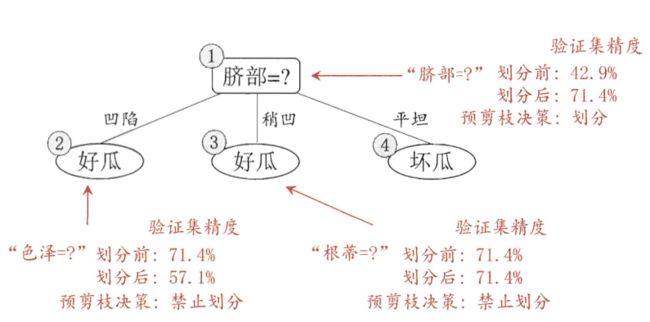
这是一棵只有一层划分的决策树,称为“决策树桩” (decision stump)。
预剪枝使得很多分支都没有展开,降低了过拟合的风险,也降低了决策树训练和预测的开销。但可能导致欠拟合。
5.2 后剪枝
后剪枝是作用在完整的决策树上的,因此我们先训练出一棵完整的决策树(即该小节一开始给的图)。
可以看出,验证集有{4, 11, 12}三个数据划分对了,因此精度为3/7=42.9%。
现在进行剪枝,先考察结点6,包含训练集{7, 15},验证集{8,9},若不剪枝为42.9%,若剪枝,则标记为好瓜,精度提高到57.1%,因此剪枝。
然后考察结点5,包含训练集{6, 7, 15},验证集{8, 9},若剪枝,则标记为好瓜,剪枝前后都是57.1%。根据奥卡姆剃刀原则,应选择简单的模型,因此应该进行剪枝。但是为了画图的直观,这里采用不剪枝的保守策略。
然后对于结点2,包含训练集{1, 2, 3, 14} ,验证集{4,5,13},若进行剪枝,则标记为好瓜,精度提升到71.4%,因此剪枝。
对结点3和结点1做同样剪枝判断处理,但是精度并不提高,因此保留:
最后的决策树如下:

6. 小结
6.1 对决策树划分样本特征空间的理解
若我们把每个属性视为坐标空间中的一个坐标轴, 则 d 个属性描述的样本就对应了 d 维空间中的一个数据点, 对样本分类则意味着在这个坐标空间中寻找不同类样本的分类边界. 决策树所形成的分类边界有一个明显的特点: 轴平行(axis-parallel), 即它的分类边界由若干个与坐标轴平行的分段组成. 这样的分类边界使得学习结果有较好的可解释性, 因为每一段划分都直接对应了某个属性取值. 但在学习任务的真实分类边界比较复杂时, 必须使用很多段划分才能获得较好的近似. 此时的决策树会相当复杂, 由于要进行大量的属性测试, 预测时间开销会很大.
6.2 决策树对比
终于到了最后的总结阶段了,这里我们不再纠结于ID3, C4.5和 CART,我们来看看决策树算法作为一个大类别的分类回归算法的优缺点。这部分总结于scikit-learn的英文文档。
首先我们看看决策树算法的优点:
1)简单直观,生成的决策树很直观。
2)基本不需要预处理,不需要提前归一化,处理缺失值。
3)使用决策树预测的代价是 O ( l o g 2 m ) O(log_2m) O(log2m)。 m为样本数。
4)既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者连续值。
5)可以处理多维度输出的分类问题。
6)相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
7)可以交叉验证的剪枝来选择模型,从而提高泛化能力。
8) 对于异常点的容错能力好,健壮性高。
我们再看看决策树算法的缺点:
1)决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
2)决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
3)寻找最优的决策树是一个 NP难 的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
4)有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。
5)如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
参考资料
- 『我爱机器学习』决策树
- 《机器学习》 – 周志华
- 《统计学习方法》 – 李航
- 机器学习技法 – 林轩田
- http://leijun00.github.io/2014/10/decision-tree-2/
- https://cethik.vip/2016/09/21/machineCAST/
- https://www.cnblogs.com/pinard/p/6050306.html
- http://www.cnblogs.com/pinard/p/6053344.html