三个Python爬虫版本,带你以各种方式爬取校花网,轻松入门爬虫
原文链接: https://mp.weixin.qq.com/s?__biz=MzIwNDA1OTM4NQ==&mid=2649543094&idx=2&sn=dc2c1fa8a9bfe28f73e10dfba4b06ee0&chksm=8edd9620b9aa1f36d87e6f508ede851ec177257a117af53b36a6ca81269502c28b2912a57f08&scene=0&xtrack=1&key=6836e4d006a8e5e05c94f6909117e8609789ee98e4dd
爬虫是什么?
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,
沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序;
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
基本环境配置
版本:Python3
系统:Windows
IDE:Pycharm
爬虫所需工具:
请求库:requests,selenium(可以驱动浏览器解析渲染CSS和JS,但有性能劣势(有用没用的网页都会加载);)
解析库:正则,beautifulsoup,pyquery
存储库:文件,MySQL,Mongodb,Redis

Python爬虫基本流程
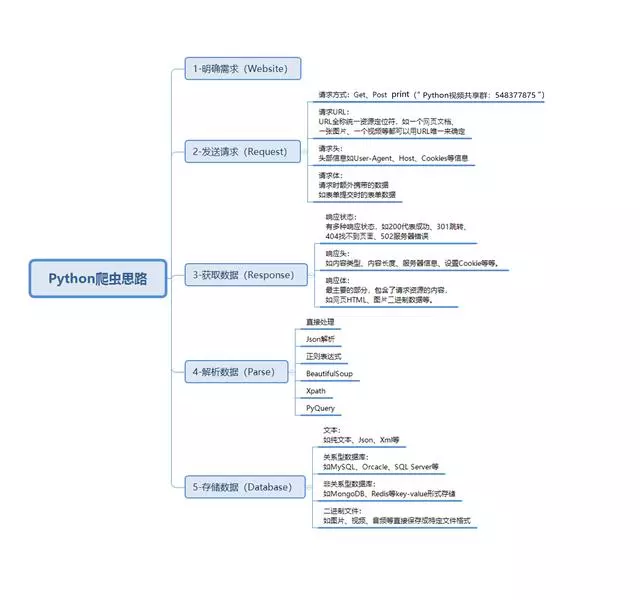
基础版:
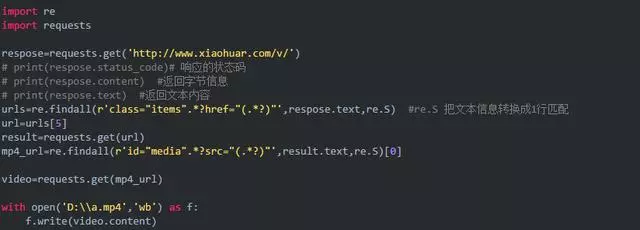
函数封装版
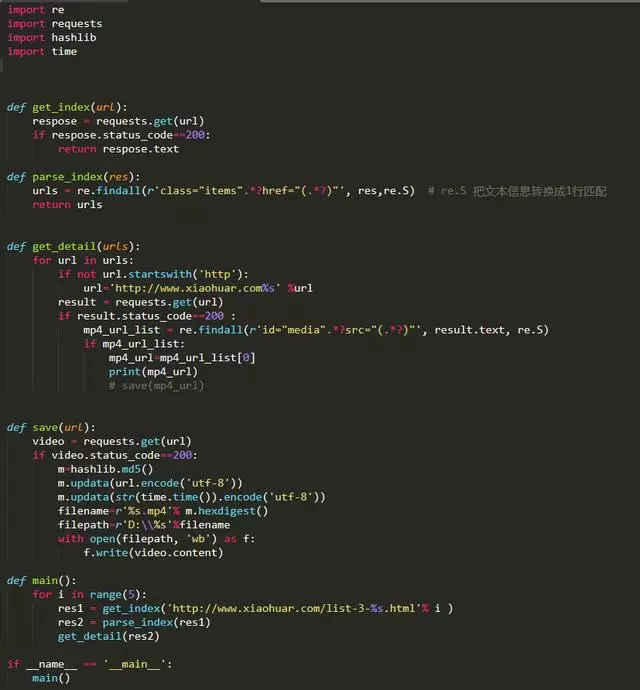
并发版
(如果一共需要爬30个视频,开30个线程去做,花的时间就是 其中最慢那份的耗时时间)

明白了Python爬虫的基本流程,然后对照代码是不是觉得爬虫特别的简单呢?