scrapy的阿里云部署笔记
————阿里云部署scrapyd————
首先python、lxml、OpenSSL这些工具Ubuntu是自带的,不用管它们。
其次安装pip,在命令行中执行以下命令:
sudo apt-get install python-pip
安装Scrapy需要的依赖库,在命令行中分别执行以下三条命令:
sudo apt-get install python-dev sudo apt-get install libevent-dev sudo apt-get install libssl-dev #在阿里云上配置的时候发现还要安这个
最后安装Scrapy,在命令行中执行以下命令:
sudo pip install scrapy
最新版Scrapy就安装好了,可以执行下列命令查看版本号:
scrapy version
其次需要安装以下依赖:
pip install requests、scrapyd、scrapyd-client、gerapy(爬虫界面控制平台)
1.修改default_scrapyd.conf的配置:
* 首先找到default_scrapyd.conf——》find -name default_scrapyd.conf
* 修改:(vi ./myvenvs/.reptile/lib/python3.5/site-packages/scrapyd/default_scrapyd.conf)
* 将bind_address = 127.0.0.1改为bind_address = 0.0.0.0
切记:阿里云服务器必须开启6800端口号!打包文件以及运行爬虫需要同时打开scrapyd
3.进入虚拟环境,进入到你的爬虫项目中,进入带有scrapy.cfg文件的目录,执行scrapyd-deploy
4.打开爬虫项目中的scrapy.cfg文件,这个文件就是给scrapyd-deploy使用的,将url这行代码解掉注释,并且给设置你的部署名称。
5.再次执行scrapyd-deploy -l 启动服务,可以看到设置的名称.
6.开始打包前,执行一个命令:scrapy list ,这个命令执行成功说明可以打包了,如果没执行成功说明还有工作没完成。
7.执行打包命令: scrapyd-deploy 部署名称 -p 项目名称
如:scrapyd-deploy bk -p baike(scrapyd-deploy p1 -p people)
8.部署scrapy
curl http://localhost:6800/schedule.json -d project=项目名称 -d spider=爬虫名称
可以去网页中127.0.0.1:6800查看爬虫运行状态
(如:curl http://47.106.201.6:6800/schedule.json -d project=people -d spider=mypeople)
——>停止爬虫
curl http://localhost:6800/cancel.json -d project=项目名称 -d job=运行ID
——>删除scrapy项目
注意:一般删除scrapy项目,需要先执行命令停止项目下在远行的爬虫
curl http://localhost:6800/delproject.json-d project=scrapy项目名称
——>查看有多少个scrapy项目在api中
curl http://localhost:6800/listprojects.json
——>查看指定的scrapy项目中有多少个爬虫
curl http://localhost:6800/listspiders.json?project=scrapy项目名称
——>如果我们想用 Python 程序来控制一下呢?我们还要用 requests 库一次次地请求这些 API ?这就太麻烦了吧,所以为了解决这个需求,Scrapyd-API 又出现了,
GitHub:https://github.com/djm/python-scrapyd-api
有了它我们可以只用简单的 Python 代码就可以实现 Scrapy 项目的监控和运行:
from scrapyd_api import ScrapydAPI
scrapyd = ScrapydAPI('http://localhost:6800')
scrapyd.list_jobs('project_name')
返回结果:
{
'pending': [
],
'running': [
{
'id': u'14a65...b27ce',
'spider': u'spider_name',
'start_time': u'2018-01-17 22:45:31.975358'
},
],
'finished': [
{
'id': '34c23...b21ba',
'spider': 'spider_name',
'start_time': '2018-01-11 22:45:31.975358',
'end_time': '2018-01-17 14:01:18.209680'
}
]
}
————阿里云部署gerapy————
1.安装gerapy:pip3 install gerapy
2.初始化:gerapy init(执行完毕后本地会生成一个名字为 gerapy 的文件夹,接着进入该文件夹,可以看到有一个 projects 文件夹)
3.执行数据库初始化命令(会在 gerapy 目录下生成一个 SQLite 数据库,同时建立数据库表):
cd gerapy
gerapy migrate
4.启动服务:gerapy runserver 0.0.0.0:8000,并登陆界面
5.同时需要进入gerapy文件启动scrapyd,创建主机:
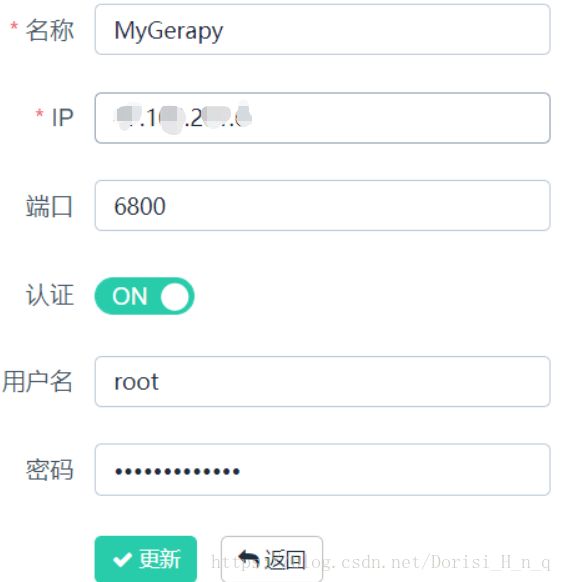
6.将爬虫文件丢入projects 文件夹,并打包部署:

7.进入主机管理进行调度:启动或停止

8.gerapy界面、scrapyd界面地址:
http://4.1X6.XXX.6:8000/#/project
http://4.1X6.XXX.6:6800/jobs