H2数据库集群
H2数据库集群
1. H2数据库简介
1.1 H2数据库优势
常用的开源数据库:H2,Derby,HSQLDB,MySQL,PostgreSQL。其中H2,HSQLDB类似,十分适合作为嵌入式数据库使用,其它的数据库大部分都需要安装独立的客户端和服务器端。
H2的优势:
1、h2采用纯Java编写,因此不受平台的限制。
2、h2只有一个jar文件,十分适合作为嵌入式数据库试用。
3、性能和功能的优势
H2比HSQLDB的最大的优势就是h2提供了一个十分方便的web控制台用于操作和管理数据库内容,这点比起HSQLDB的swing和awt控制台实在好用多了。
H2和各数据库特征比较
1.2 H2特征
1.2.1 主要特征
• 超快的数据库引擎
• 开源
• 纯JAVA编写
• 支持标准SQL和JDBC
• 支持内嵌模式、服务器模式和集群
• 高强度的安全保障
• 支持PostgreSQL的ODBC驱动
• 多种并发机制
1.2.2 其他特征
• 支持磁盘和内存数据库,支持只读数据库,支持临时表
• 支持事务(读提交和序列化事务隔离),支持2阶段提交
• 支持多连接,支持表级锁
• 使用基于成本的优化机制,对于复杂查询使用零遗传算法进行管理
• 支持可滑动可更新的结果集,支持大型结果集、支持结果集排序,支持方法返回结果集
• 支持数据库加密(使用AES或XTEA进行加密),支持SHA-256密码加密,提供加密函数,支持SSL
1.3 连接模式
1.3.1 内嵌模式
内嵌模式下,应用和数据库同在一个JVM中,通过JDBC进行连接。内嵌模式是最快和最容易的连接模式。它的缺点是任何时候数据库只能在一台虚拟机(和加载类)。像所有的模式,持久数据库和内存数据库都被支持。没有打开连接数和打开数据库数量方面的限制。
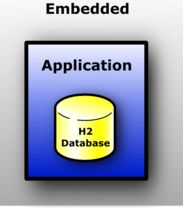
1.3.2 服务器模式
使用服务器模式(有时被称为远程模式或是C/S模式)时,应用可以通过JDBC或ODBC打开一个远程的数据库。服务器可以启动在同一个虚拟机或是不同的虚拟机上,也可以启动在不同的计算机上。大量的应用可以同时连接到同一个数据库上。服务器模式相比内嵌模式性能慢一些,因为所有的数据都需要通过TCP/IP进行传输。像所有的模式一样,支持持久数据库和内存数据库。没有打开连接数和打开数据库数量方面的限制。
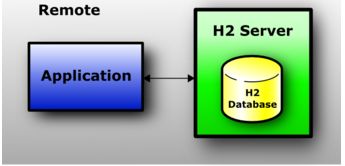
备注:
H2支持三种服务模式:
web server:此种运行方式支持使用浏览器访问H2 Console
TCP server:支持客户端/服务器端的连接方式
PG server:支持PostgreSQL客户端
启动tcp服务连接字符串示例:
jdbc:h2:tcp://localhost/~/test (使用用户主目录)
jdbc:h2:tcp://localhost/data/test (使用绝对路径)
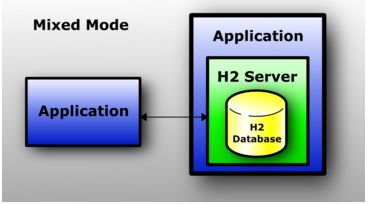
1.3.3 混合模式
混合模式是内嵌模式和服务器模式的组合。第一个应用通过内嵌模式与数据库建立连接,同时也作为一个服务器启动,于是另外的应用(运行在不同的进程或是虚拟机上)可以同时访问同样的数据。第一个应用的本地连接与嵌入式模式的连接性能一样的快,而远程连接有点慢。
服务器能通过应用来进行启动和停止(使用服务API),或是是自动的方式(自动混合模式)。当使用自动混合模式,所有客户端都需要使用同样的URL进行连接(不管它是一个本地还是一个远程连接。
1.3.4 数据库URL综述
数据库支持多种连接模式和连接设置,不同的连接模式和连接设置是通过不同的URL来区分的,URL中的设置是不区分大小写。
备注:以下只列出常用的,详情请参考
http://www.h2database.com/html/features.html#database_url
Topic URL Format and Examples
使用TCP/IP的服务器模式(远程连接) jdbc:h2:tcp://[:]/[]
jdbc:h2:tcp://localhost/~/test
jdbc:h2:tcp://dbserv:8084/~/sample
jdbc:h2:tcp://localhost/mem:test
使用SSL/TLS的服务器模式(远程连接)
jdbc:h2:ssl://[:]/
jdbc:h2:ssl://localhost:8085/~/sample;
用户名和密码 jdbc:h2:[;USER=][;PASSWORD=]
jdbc:h2:file:~/sample;USER=sa;PASSWORD=123
调试跟踪项设置 jdbc:h2:;TRACE_LEVEL_FILE=
1.3.5 命令行工具
H2数据库提供了一组命令行工具,如果你需要了解这些工具,使用参数-?,如:
java -cp h2*.jar org.h2.tools.Backup -?
命令行工具有:
• Backup创建数据库备份
• ChangeFileEncryption 允许改变文件加密密码和数据库的加密算法
• Console 启动基于浏览器的H2控制台
• ConvertTraceFile转换 .trace.db 文件到JAVA应用和SQL脚本
• CreateCluster从一个独立的数据库服务创建集群
• DeleteDbFiles 删除所有的数据库文件
• Recover恢复损坏的数据库
• Restore从数据库备份中恢复数据库
• RunScript 运行数据库SQL脚本
• Script 为数据库备份或迁移导出SQL脚本
• Server 启动H2服务模式
• Shell命令行工具
这些工具也能在程序中通过调用相应的方法来使用,相关详细的调用说明,请参考JavaDoc文档http://www.h2database.com/html/tutorial.html#command_line_tools。
2. H2安装与server mode启动
2.1 H2安装与维护
2.1.1 下载安装文件
下载文件:h2-2014-04-05.zip
下载地址:http://www.h2database.com/html/download.html
2.1.2 安装并采用服务器模式启动
- 远程连接Linux服务器,这里进入到 usr/local/ 目录
- 上传安装文件至h2目录下;(可自行设定安装目录)
- 解压该安装文件:

- 确认已经安装了JDK,和已经配置了JAVA_HOME环境变量,例如:

- 进入到h2/bin目录,可以看到以下文件,其中h2.sh是以console方式启动,参考其新建h2_server.sh文件

- 编辑h2_server.sh,如下:
#!/bin/sh
dir=$(dirname "$0")
java -cp "$dir/h2-1.3.176.jar:$H2DRIVERS:$CLASSPATH" org.h2.tools.Server -tcpAllowOthers -webAllowOthers -webPort 8082 "$@"说明:
org.h2.tools.Server: 以服务器模式启动
-tcpAllowOthers: 允许远程机器通过TCP方式访问
-webAllowOthers: 允许远程机器通过浏览器访问
-webPort 8082: 默认的访问端口(8082为未被占用的端口,如果此端口已经被其他端口占用,则改为其他端口)
启动h2服务(如果没有执行权限则需要更改h2_server.sh文件权限)

通过远程浏览器来访问h2
访问地址:http://服务器ip:8082/
出现如下页面,并点击test connection会出现test successful说明h2部署成功

说明:
Jdbc:h2:tcp://服务器ip/test: test是数据库文件的名称,(默认路径/usr/local/h2/bin)
User name : sa h2默认的用户,密码为空
点击如图connect按钮,test数据库文件自动生成到/usr/local/h2/bin 目录下:test.h2.db
3. H2集群
3.1 集群综述
数据库支持简单的集群/高可用性机制。架构是:两个数据库服务运行在两台不同的计算机上,两台计算机有同样数据库的副本,如果两个服务器都处于运行状态,每个数据库操作都被在两台计算机上执行,如果一台服务器宕机(断电、硬件故障、网络故障等),另外一台计算机仍能提供服务,从这一刻开始,数据库操作仅在一台服务器上执行,直到另外一台服务器恢复运行。
集群仅能用于服务器模式(内嵌模式并不支持集群)。可以在数据库运行状态下恢复集群而不用停止剩余的服务器(通过使用CreateCluster工具重新创建),已连接的应用程序会自动断开,但是添加上AUTO_RECONNECT = TRUE参数的,将自动重连。(但是要求在第二个数据库恢复期间没有应用在改变第一个数据库的数据,因此恢复集群是一个手工的过程。)
初始化集群,使用下面的步骤:
• 创建数据库
• 使用 CreateCluster工具创建一个数据库副本并分到另外的地方,并且初始化集群,这样就得到了同样数据的两个数据库
• 启动两个数据库服务(每个数据库的副本)
• 现在可以通过应用客户端连接到数据库
3.2 创建集群
要了解集群如何工作,请尝试下面的例子,在这个例子里,两个数据库分别在同不同计算机上,分别在两台计算机上新建base目录,这里在bin目录下。
- 创建目录
mkdir h2Server1 # 主机1上
mkdir h2Server2 # 主机2上- 启动tcp服务
分别在两台主机上,以服务器模式启动数据库服务,
启动TCP服务指向第一个目录,你可以运行下面的命令:
主机1上启动shell脚本:
#!/bin/sh
dir=$(dirname "$0")
java -cp "$dir/h2-1.3.176.jar:$H2DRIVERS:$CLASSPATH" org.h2.tools.Server -tcpAllowOthers -tcpPort 9101 -webAllowOthers -webPort 8081 -baseDir h2Server1 "$@"主机2上启动shell脚本:
#!/bin/sh
dir=$(dirname "$0")
java -cp "$dir/h2-1.3.176.jar:$H2DRIVERS:$CLASSPATH" org.h2.tools.Server -tcpAllowOthers -tcpPort 9102 -webAllowOthers -webPort 8082 -baseDir h2Server1 "$@"然后,使用 CreateCluster 工具初始化集群,如果数据库不存在,将创建一个新的空数据库,在主机1上执行:
Java -cp h2-1.3.176.jar org.h2.tools.CreateCluster
-urlSource "jdbc:h2:tcp://172.16.21.139:9101/testCluster"
-urlTarget "jdbc:h2:tcp://172.16.21.131:9102/testCluster"
-user "sa"
-serverList "172.16.21.139:9101,172.16.21.131:9102"(说明:-urlSource和-urlTarget指明了哪个是主DB(所有select操作都从这个DB走),其它insert, delete, update操作分别向两个DB进行操作)。
• 现在应用或者H2控制台可以通过下面的JDBC的URL连接数据库:
jdbc:h2:tcp://172.16.21.139:9101,172.16.21.131:9102/testCluster
• 如果你停掉一个服务(通过杀进程),你会发现到其他机器继续工作,因此数据库仍能可以访问。
• 恢复集群,你需要先删掉宕机的数据库,然后重启宕机的数据库的服务,再重新运行CreateCluster集群工具。
3.3 检测运行状态下的集群
查找哪些节点当前正在运行,通过执行下面的SQL语句:
SELECT VALUE FROM INFORMATION_SCHEMA.SETTINGS WHERE NAME='CLUSTER'结果返回为 ” (两个单引号),说明集群模式被屏蔽,否则,集群服务器列表将被单引号包括着返回,如’server1:9191,server2:9191’。
另外,也可以通过使用Connection.getClientInfo()获取服务列表。
从getClientInfo()返回的属性列表中,包含在连接列表服务器的数量一numServers属性。为了得到实际的服务器, getClientInfo()也有属性server0..serverX ,其中serverX是服务器num再减去1 。
例如:为了获得在连接列表中第二服务器,可以通过使用getClientInfo(‘server1’)。注意: serverX属性只返回的IP地址和端口,而不是主机名。
3.4 集群限制
只读查询只针对第一个群集节点执行,但所有其他的语句在所有节点都会执行。目前还不支持针对事务的负载均衡。下面几个方法因为处在集群中不同节点,可能执行的结果会不同(操作会使两个数据库产生不一致的结果),必须谨慎执行:
RANDOM_UUID(), SECURE_RAND(), SESSION_ID(), MEMORY_FREE(), MEMORY_USED(), CSVREAD(), CSVWRITE(), RAND(),[当没有使用种子]. 这些方法不能直接使用在修改语句中 (如INSERT, UPDATE, MERGE),然而,你能够使用它们在只读语句中,他们的结果也能用在修改语句中。自动增长列和标识列不支持集群,当插入数据时,序列值需要手动创建。
在集群模式下,不支持SET AUTOCOMMIT FALSE语句,如果需要设置成为不自动提交,可以执行方法Connection.setAutoCommit(false)。
4. 稳定性与可用性
4.1 测试对比
测试场景,分为几种场景测试,分别对单节点单数据库方式与两台主机两个数据库分别多个线程插入查询增量的数据,进行性能分析,比较集群的性能损耗的,以及对集群的可用性,分别对两个server进行停止服务模拟宕机的情况,验证其可用性。
4.2 主机配置
1、 硬件配置:
- CPU:Intel(R) Core(TM) i5-4590 CPU @ 3.30GHz * 2(2核处理器)
- 内存:2G
- 磁盘:75G,RAID5磁盘阵列
2、 软件配置:
- 操作系统:CentOS Linux release 7.1.1503(Linux version 3.10.0-229.14.1.el7.x86_64)
- H2数据库:h2-1.3.176
- JDK: 1.7.0_79
4.3 单节点单数据库与集群对比
4.3.1 测试场景
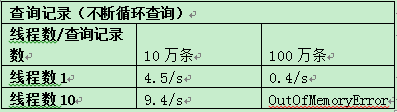
测试场景1:起单个数据库服务,测试单节点下,操作简单SQL的性能;分别起N(1, 10, 100)个线程并发新增N(1万, 10万, 100万, 1000万)条记录。
测试场景2:两台主机分别起两个数据库服务,并对其进行集群配置,操作简单SQL的性能;分别起N(1, 10, 100)个线程并发新增N(1万, 10万, 100万, 1000万)条记录。
4.3.2 测试步骤:
1.首先以服务器模式启动数据库服务,详情参考:4.1.2 安装并采用服务器模式启动。
2.每次都先清除数据,保持数据库一致,执行以下语句:
DROP TABLE IF EXISTS TEST_TABLE;
CREATE TABLE TEST_TABLE(id VARCHAR(36),name VARCHAR(100));3.通过jmeter,执行新增记录语句
INSERT INTO TEST_TABLE VALUES('测试id','测试name');4.3.3 测试结果:
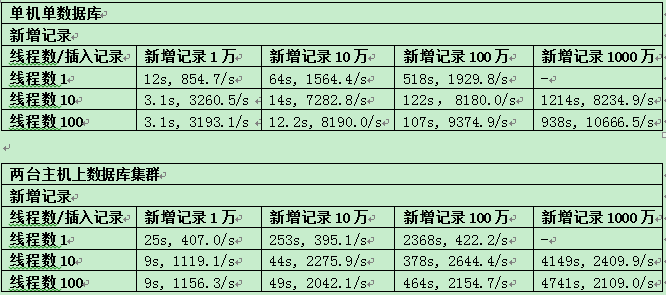
4.4 集群下查询验证
4.4.1 测试场景
测试场景:两台主机分别起两个数据库服务,起10个线程不断执行以下语句,查询不同的数据条数(10万、100万)。
1 0 threads , 10万 records:
SELECT * FROM TEST_TABLE LIMIT 10000主机1:
主机2:
1 0 threads , 100万 records:
SELECT * FROM TEST_TABLE LIMIT 100000主机1:

主机2:
4.5 可用性测试
4.5.1 测试场景
测试场景:两台主机分别起两个数据库服务,测试分别模拟其中一台宕机(停止服务)的情况。
4.5.1.1 测试场景1:
停掉target(server2) 数据库服务
1.集群情况下,停掉server2,然后执行以下语句,成功
INSERT INTO TEST_TABLE VALUES('测试1','测试1');
INSERT INTO TEST_TABLE VALUES('测试2','测试2');
INSERT INTO TEST_TABLE VALUES('测试3','测试3');2.执行SELECT * FROM TEST_TABLE,能查询出数据
此时数据只写入到server1:

Server2上并没有写入:

3.重启server2,此时可以看到server2数据自动重新写入

4.5.1.1 测试场景2:
停掉source(server1) 数据库服务
先重新执行:
DROP TABLE IF EXISTS TEST_TABLE;
CREATE TABLE TEST_TABLE(id VARCHAR(36),name VARCHAR(100));此时server1与server2数据库表都为空:


1.集群情况下,通过jmeter写入10万条数据。
2.写入数据过程中,停掉server1
通过访问server1控制台无法连接,确认无法提供服务。
通过jdbc:h2:tcp://172.16.21.139:9101,172.16.21.131:9102/testCluster集群方式连接server2,出现可以成功连接。
Jmeter仍能继续写入数据。
3.完成数据写入后
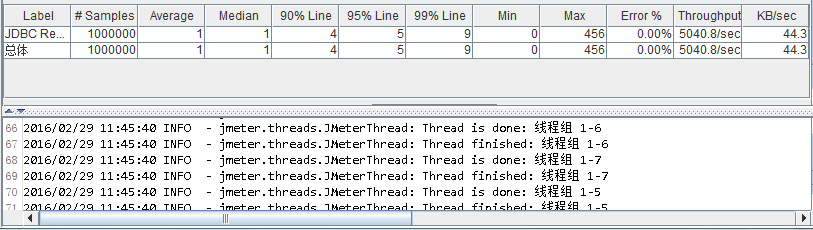
Server1:
Server2:

4.重启server1仍不会将server2中的记录同步过去server1,只能靠手工删除server1中的数据库,把server2的复制过去,重启集群服务。
4.7 结果分析
- 对于集群方式,update statement性能要比单机单数据库服务情况要下降50%-70%。
- 查询语句执行只在第一个节点,压力不能分担到第二个节点,因此并发查询数据量过大的情况下有出现内存溢出情况。
- Server2停掉后,server1能继续提供数据库服务。并在server2重启后,集群工具自动同步数据。
- Server1停掉后,server2能继续提供数据库服务,集群工具自动不会同步数据,此时只能靠手工删除server1中的数据库,把server2的复制过去,重启集群服务(这个结论感觉跟官方说明不太一样,但是验证的测试的结果是这样…问题在哪?)。
备注:
- 使用最新的1.4.x版本也测了一下,保存文件方式改变了。
- 集群的时候,server2,停掉后,server1能继续提供数据库服务,在server2删掉数据文件后重启,需要重新在用集群工具建立集群,此时需要注意urlSource 应为server1,urlTarget 应为server2。
- server1,停掉后,server2同样能继续提供数据库服务,在server1删掉数据文件后重启,需要重新在用集群工具建立集群,此时需要更换urlSource 应为server2,urlTarget 应为server1。就是说以最终保持服务的数据库为准,使用集群工具启动集群服务时,将把urlSource 的数据文件拷贝到urlTarget ,如果弄反了,会把空数据库文件覆盖了在使用的数据库文件(相当于把数据都清空了~~)。到这里可以看出,跟官网描述基本一致了。
- 数据进行同步过程中,会阻塞读写。