论文阅读笔记:A novel retinal vessel detection approach based on multiple deep convolution neural networks
一种新颖的基于多重深度卷积神经网络的视网膜血管检测方法
关键词:视网膜血管分割、多重深卷积神经网络、图像分割
摘要
方法:在本文中,我们将检测任务作为一个分类问题,并使用基于深度卷积神经网络的多分类器框架来解决它。 在具有有限图像量的眼底图像上构建和训练多重深度卷积神经网络(MDCNN)。 MDCNN使用增量学习策略进行训练,以提高网络的性能。 最终的分类结果是从MDCNN结果的投票程序中获得的。
结果:MDCNN在DRIVE数据集上实现了较好的视网膜血管自动分割性能,在训练集和测试集上分别获得了95.97%和96.13%的准确率,0.9726和0.9737 的AUC分值。另一个公共数据集STARE也用于评估所提议的网络。实验结果表明,所提出的MDCNN网络在STARE数据集中的准确率为95.39%,AUC值为0.9539。我们进一步比较了我们的结果与几种最先进的方法基于AUC值。比较表明,我们的方案获得了第三好的AUC值。
结论:与现有方法相比,我们的方法具有更好的性能。此外,我们的方案没有预处理阶段,将输入的彩色眼底图像直接输入到CNN。
1.介绍
已发表的作品可分为两类,即图像处理和基于深度学习(DL)的方法。基于图像处理的方法涵盖了十几种基于图像处理和机器学习的方法[2-7]。在[2]中,作者使用2-D Gabor小波滤波器和线性分类器进行视网膜血管检测。作者基于所获得的特征向量确定每个像素(容器与否)的类别标签,所述特征向量由像素强度和多尺度Gabor小波系数组成。基于形态学的视网膜血管分割算法由Dash等人引入。在[3]中。作者最初使用对比度受限自适应直方图均衡(CLAHE)进行视网膜图像增强,然后通过测地线操作员实现血管分割。然后通过后处理阶段细化所获得的分割。 Zhao等人介绍了另一种视网膜血管分割算法。在[4]中,水平集和区域生长方法被组合起来用于有效的分割方案。正如在之前的方法[3]中应用的那样,基于CLAHE和各向异性扩散滤波应用图像增强。在[5]中,作者提出了一种基于剪切变换和不确定性滤波的视网膜血管分割方法[6]。最初将视网膜图像的绿色通道转化为中性结构域,然后提取剪切特征采用神经网络分类器将视网膜图像分类为血管或非血管类别。 Nergiz等人应用Frangi过滤器和结构张量。在[6]中有效的视网膜血管分割。然后将获得的张量场转换为3-D空间(能量,各向异性和取向)。然后将增强的3-D空间转换为4-D张量场。 Otsu阈值应用于最终分割操作。 Bankhead等 [7]提出了一种基于小波变换的视网膜血管检测的简单方法。作者使用阈值方法获得视网膜血管提取的小波系数。
卷积神经网络(CNN)是深度学习方法之一,已被广泛应用于文献[8-15]。 Sengur等人。将视网膜血管检测问题制定为分类问题并应用CNN [8]。采用的CNN架构分别具有两个卷积层,两个汇聚层,一个丢失层和一个丢失层。 Dasgupta等人。提出完全连接的CNN和结构预测方法来分割视网膜图像中的血管[9]。所提出的CNN架构具有联合loss 函数,其可以了解相邻像素的类标签依赖性。傅等人。提出了一种深层两阶段方案,用于在眼底图像中提取视网膜血管[10]。它最初应用了具有侧输出层的多尺度和多级CNN,以学习丰富的分层表示。然后,使用条件随机场来模拟像素之间的长程相互作用。 Maninis等。提出了对血管和视盘分割的深度视网膜图像理解[11]。 Maji等人。在眼底图像中引入了视网膜血管检测的深度和集成学习框架[12],其中各种CNN的集合将视网膜图像分类到血管和非血管区域。在[13]中,Liskowskiand等人。提出了一种基于深度神经网络的视网膜血管分割监督检测算法。它被认为是一组预处理阶段,分别是对比度归一化,白化和几何变换以及伽马校正。拉希里等人。提出了视网膜血管分割的深度学习集合[14],并采用了无监督的分层特征学习,使用两级稀疏训练的去噪堆叠自动编码器。
本文将视网膜血管检测任务定义为一个分类问题,并采用多重深卷积神经网络(MDCNN)作为投票分类器进行求解。提出的MDCNN采用增量策略进行训练,以提高其性能和训练速度。实验结果表明,MDCNN在DRIVE和STARE数据集上实现了较好的视网膜血管自动分割性能,明显优于目前最先进的视网膜血管自动分割技术。
2.提出的方法
2.1网络结构
与传统的分类方法相比,CNN能够通过自适应其多层前馈结构自动提取不同的特征。在该模型中,CNN的输入是一个ROI patch,其大小为64×64×1,输出是ROI中像素的分类结果。我们使用卷积、线性修正单元(ReLu)、池化、反卷积、softmax和像素分类等六种层次来构建CNN网络。具体的网络结构如表1所示。

在卷积层中,设xl -1 (m)为L-1层的第m个输入特征,Wl(m,n)为连接输出层第n个特征与输入层第m个特征的滤波器权值,bl(n)为偏置。第l卷积层的xl(n)值计算为:

这里*是卷积运算,而f是sigmoid函数。随机初始化滤波器Wl(m,m)的权值,然后通过反向传播算法进行更新。
经过校正的线性单元(ReLu)层对输入的每个元素执行阈值操作,其中任何小于零的值都被设置为零。ReLu定义为;

池化层用于减小特征映射的空间大小。它能有效地减少网络参数个数,避免过拟合问题。池化层l中的xl(n)值计算如下:
![]()
其中pool(•) 是一个采样函数。
反卷积层与卷积层有相似方程,对特征图进行上采样。利用全连接层对特征图进行平面化,并将其与输出层连接,输出层将输入乘以一个权重矩阵,然后添加一个偏置向量。softmax层对全连接层的输入应用softmax函数,定义softmax函数为:
![]()
其中y是类标签,w是权重。
像素分类层返回ROI中像素的分类结果。
2.2多重深度卷积神经网络
一个多DCNNs框架是由具有相同结构的多个网络级联而成的:
![]()
其中N为框架中DCNN的总数。在我们的实验中,它被选为5,这是用train-and-error方法确定的。
MDCNN采用增量学习策略进行训练,以提高网络性能。下一个DCNN使用与前一个相同的样本进行训练,并通过学习前一个DCNN中表现不好的样本来增强。这样,下一个DCNN将克服前一个的差性能。
![]()
其中Sample(k)和Sampl(k+1)分别是第k个和第k+1个DCNN的样本,IncreSample(k)是第k个DCNN被错误分类的样本。
2.3按投票方式分类
通过对多个DCNNs结果进行投票,最终确定像素归属。
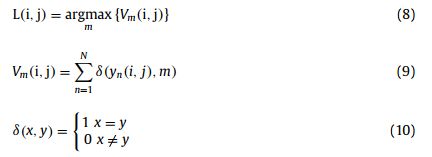
其中L(i,j)为(i,j)处像素的最终分类标签,Vm(i,j)为不同类别的投票结果,yn(i,j)为第n个DCNN模型的分类结果。
3.实验结果
3.1数据集
用于血管提取的数字视网膜图像(DRIVE)数据集包含总共40个眼底图像,并且分为训练和测试集[4]。 训练和测试集包含相同数量的图像(20)。 使用每个颜色平面8比特以768×584像素捕获每个图像。 每个图像上的视场(FOV)是圆形的,具有大约540个像素的直径,并且使用FOV来裁剪所有图像。 视网膜结构分析(STARE)数据库由20个彩色视网膜图像组成[4]。 这些视网膜图像被数字化为每个颜色通道8位,700×605像素。 这两个数据集用于分析视网膜血管分割相对于地面实况图像的性能,并且包括正常和异常视网膜图像。
3.2视网膜血管检测实验
在本节中,我们将使用DRIVE数据集来训练所提议的网络。学习效率由0.01逐渐下降到0.001。将学习率设为分段函数,下降周期为5个周期,下降因子为0.005。采用五种结构相同的神经网络构造了该模型。所有CNN网络都经过100个epoch的训练,batch size为256。
所有的实验都在一台2×6核Intel的服务器上运行,Xeon处理器和128GB内存。该服务器配备了两个NVIDIA Tesla K40 gpu,每一个都有12GB的内存。训练该模型大约需要4个小时。在预测阶段,将输入图像分割成64×64×1的patch,送到模型中检测血管像素。一张图像平均需要114秒。
利用精确度曲线对检测性能进行评价。此外,还利用接收算子曲线(ROC)和ROC下面积(AUC)来测量检测性能。准确度指标和ROC常用于评估不同视网膜血管分割算法的性能。
如表2所示,所提出的方法的在DRIVE和STARE测试集的精确度分别为96.13%和95.39%,AUC分别为0.9737和0.9539。ROC曲线绘制在图1-3的不同集合上。图4显示了我们提出的方法的可视化结果。

Fig. 1. DRIVE训练集上的ROC曲线

Fig. 2. DRIVE测试集上的ROC曲线

Fig. 3. STARE数据集上的ROC曲线

图4.我们提出的方法对从DRIVE测试数据集中随机抽取的样本的可视化检测结果:(a)原始图像(b)相应的ground truth(c)检测结果。
我们进一步将结果与使用AUC值的几种最先进的方法进行比较。如表3所示,我们的方案为DRIVE dataset获得了第三好的AUC值。Dasgupta等人[9]的结果比我们的好,差异为0.007,桥良等人的研究[16]的AUC值次之,与我们提出的方法的差异仅为0.001。
4.总结
略