字典树应用——词频统计 (C++实现)
来学校交流学习的第一个正式的小项目作业就是软件工程老师所提出的词频统计了,具体要求如下。
要求:
写一个程序,分析一个文本文件中各个词出现的频率,并且把频率最高的10个词打印出来。文本文件大约是30KB~300KB大小。
解决思路:
刚看到这个问题,我脑海浮现的问题就是如何存储如此大量的数据呢,然后如何进行有效的统计。
我在想解决方案时,也有参考以前学姐学长们的例子,发现大多数好像都是用数组或者是链表来实现。
虽然老师所要求的文章大小并不算大,但是,推而广之考虑到文件大小更大的文章呢。所以单词量不是像原来所读取的那样少,若简单用数组链表实现的话,每匹配一个词就要把所有的单词遍历一遍显然是效率不高的,且读取以后要遍历多次进行单词的匹配,以便统计相同单词的个数。所以就考虑到一个效率的问题,恰好最近看到有关海量数据处理的相关文章,所以这里我首先就想到用字典树来存储数据。
字典树我就不详细介绍了,前一篇博文有详细介绍。Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。Trie的典型应用是统计和排序大量的字符串,所以经常被搜索引擎系统用于文本词频统计。
(以上仅是个人见解,有任何异议错漏欢迎提出,谢谢。)
整个开发时间历时两天左右,一天时间来学习字典树相关知识,另一天来实现该程序代码。
实现代码:
1.字典树的相关定义:
(dic.h)
using namespace std ;
class DicNode
{
public:
DicNode() ;
virtual ~DicNode() ;
public:
int count ;
bool word ;
DicNode* next[26] ;
} ;
class Dic : public AddWord
{
public:
Dic() ;
virtual ~Dic() ;
private:
DicNode* head ;
public:
bool addFilter(Filter* filter) ;
bool addWord (string word) ;
bool travel(WordSord* pool) ;
private:
void travel_inside(DicNode* p, string data, WordSord* pool) ;
vector filter_array ;
} ; (dic.cpp)
#include "dic.h"
DicNode::DicNode()
{
this->count = 0 ;
this->word = false ;
for (int i = 0 ; i < 26 ; ++i)
{
this->next[i] = NULL ;
}
}
DicNode::~DicNode()
{
for (int i = 0 ; i < 26 ; ++i)
{
if (this->next[i])
{
delete next[i] ;
this->next[i] = NULL ;
}
}
}
Dic::Dic()
{
this->head = new DicNode() ;
}
Dic::~Dic()
{
if (this->head)
{
delete this->head ;
this->head = NULL ;
}
}
bool Dic::addFilter(Filter* filter)
{
if (NULL == filter)
{
return false ;
}
this->filter_array.push_back(filter) ;
return true ;
}
bool Dic::addWord(std::string word)
{
DicNode* p = this->head ;
for (int i = 0 ; i < (int)word.length() ; ++i)
{
// ≈–∂œ «≤ª «“™±ª»•≥˝µÙ
for (int j = 0 ; j filter_array.size(); ++j)
{
if (this->filter_array[j]->existWord(word))
{
return true ;
}
}
// ◊™≥…–°–¥
if (word[i] >= 'A' && word[i]<= 'Z')
{
word[i] = word[i] - 'A' + 'a' ;
}
int index = word[i] - 'a' ;
if (NULL == p->next[index])
{
p->next[index] = new DicNode() ;
}
p = p->next[index] ;
if (i == word.length()-1)
{
p->word = true ;
p->count++ ;
}
}
return true ;
}
bool Dic::travel(WordSord* pool)
{
if (NULL == pool)
{
return false ;
}
string data ;
this->travel_inside(this->head, data, pool) ;
return true ;
}
void Dic::travel_inside(DicNode* p, string data, WordSord* pool)
{
if (NULL == p)
{
return ;
}
if (p->word)
{
//cout <count<< endl ;
pool->addString(data, p->count) ;
}
for (int i = 0 ; i < 26 ; ++i)
{
if (p->next[i])
{
string temp = data + char('a' + i) ;
travel_inside(p->next[i], temp, pool) ;
}
}
} 关键代码:
#include "file.h"
#include
using namespace std ;
bool File::readFromFile(string file, AddWord* object)
{
if (NULL == object)
{
return false ;
}
string lines ;
ifstream in(file.c_str()) ;
if (in)
{
string word = "" ;
while (getline (in, lines))
{
for (int i = 0 ; i < (int)lines.length() ; ++i)
{
if ((lines[i] >= 'a' && lines[i] <= 'z')
|| (lines[i] >= 'A' && lines[i] <= 'Z'))
{
word += lines[i] ;
}
else
{
if (word != "")
{
object->addWord(word) ;
}
word = "" ;
}
}
if (word != "")
{
object->addWord(word) ;
word = "" ;
}
}
if (word != "")
{
object->addWord(word) ;
word = "" ;
}
}
else
{
cout<< "open file" << file << " failed..." << endl ;
}
return true ;
} 3.字典树排序及输出
关键代码:
#include "word_sord.h"
using namespace std;
bool operator < (const word_node& l, const word_node& r)
{
if (l.count <= r.count)
{
return false ;
}
return true ;
}
WordSord::WordSord(int _size)
{
this->_size = _size ;
}
bool WordSord::addString(string word, int num)
{
if (this->_size <= 0)
{
return true ;
}
word_node _node ;
_node.count = num ;
_node.word = word ;
if ((int)this->array.size() < _size)
{
this->array.push_back(_node) ;
}
else
{
int min_index = 0 ;
int min_data = array[0].count ;
for (int i = 0 ; i < (int)array.size() ; ++i)
{
if (min_data > array[i].count)
{
min_data = array[i].count ;
min_index = i ;
}
}
if (num > min_data)
{
array[min_index] = _node ;
}
}
return true ;
}
bool WordSord::print_r()
{
sort(array.begin(), array.end()) ;
for (int i = 0 ; i < (int)this->array.size() ; ++i)
{
cout<4.主函数
//
// main.cpp
// dictree
//
// Created by Emily on 14-10-6.
// Copyright (c) 2014年 Emily. All rights reserved.
//
#include
#include "time.h"
#include "file.h"
#include "dic.h"
#include "word_sord.h"
#include
using namespace std ;
int main()
{
// ¥¥Ω®◊÷µ‰ ˜
Dic dic ;
clock_t start_time = clock();
// ∂¡»°Œƒº˛
File file ;
file.readFromFile("/Users/emily/Documents/dictree/dictree/1.txt" , &dic) ;
// ¥¥Ω®≈≈–Ú
WordSord sord(10) ;
// ±È¿˙◊÷µ‰ ˜
dic.travel(&sord) ;
// ¥Ú”°≥ˆ¿¥ ˝æ›
sord.print_r() ;
system("pause") ;
clock_t end_time = clock();
cout<<"Running Time is:"<(end_time-start_time)/CLOCKS_PER_SEC*1000<<"ms"< 项目文件图:
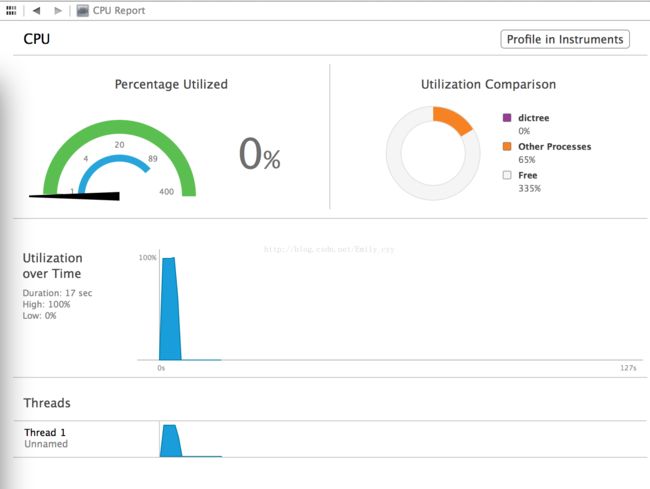
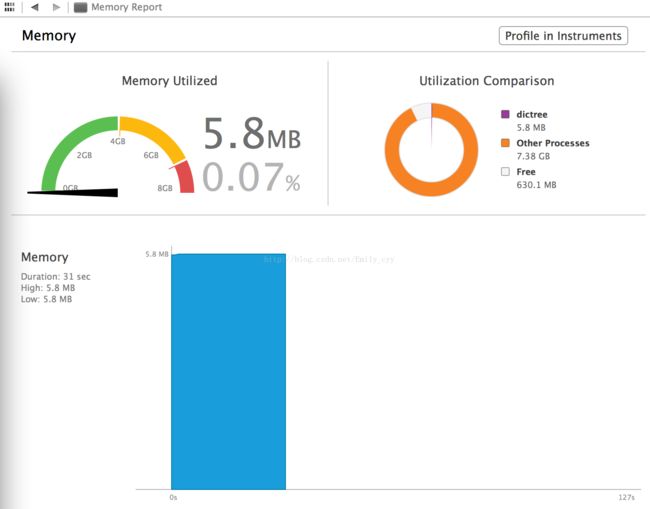
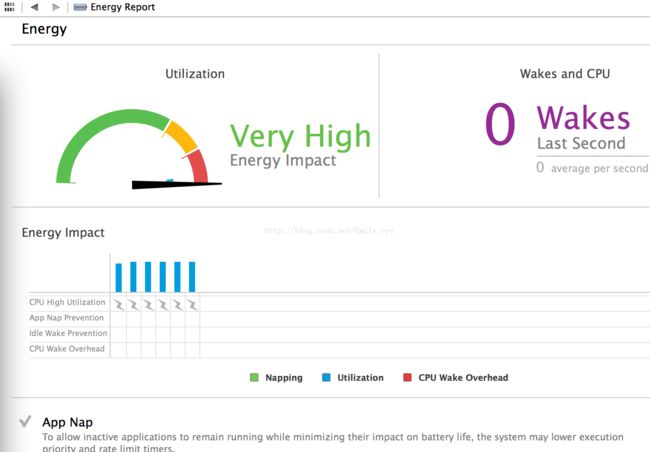
性能分析1(780KB左右):
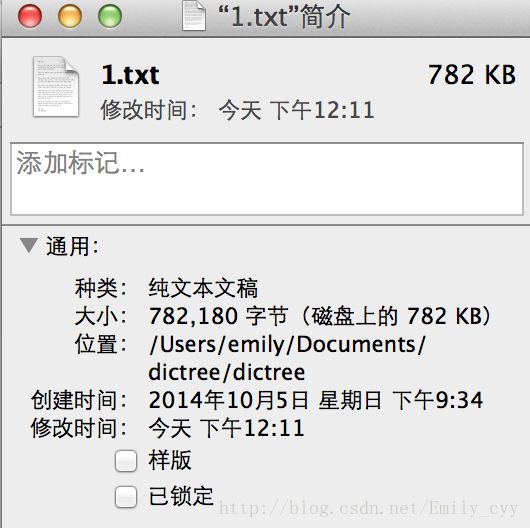
测试文档大小:
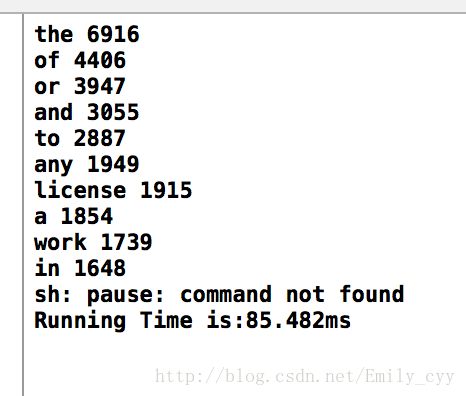
测试结果:
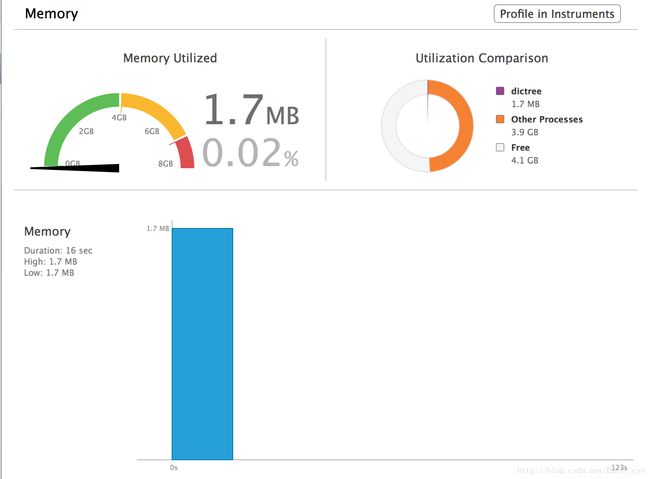
相关性能:
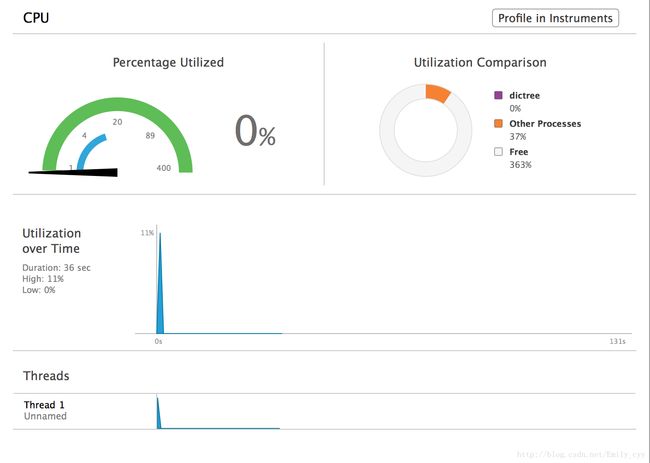
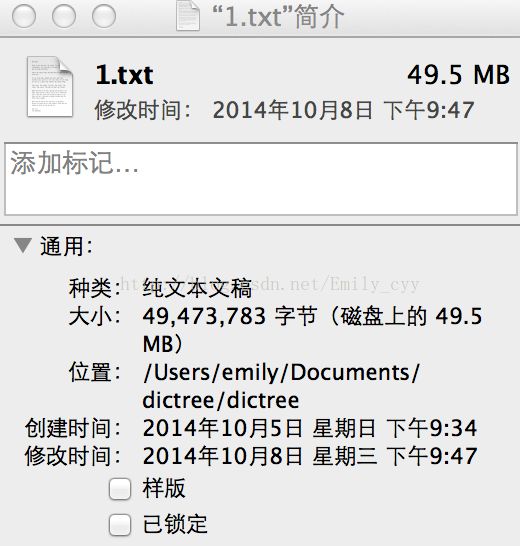
性能分析2(50MB左右):
测试文档大小
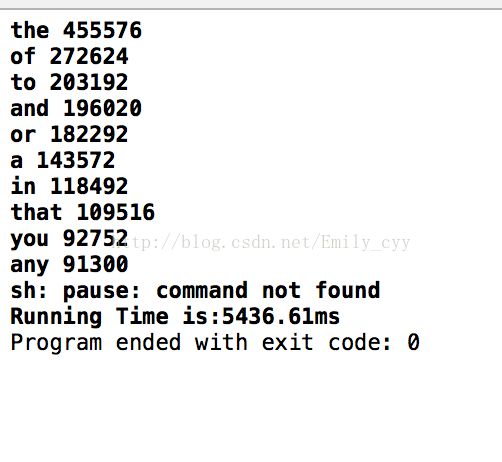
测试结果:
相关性能:
项目总结:
整个程序写下来,收获颇丰,一方面熟悉了解了新的数据结构——字典树,另一方面也认识到了使用合适的数据结构的重要性。因为这样会节省大量的程序运行时间和内存,使我们的程序更加高效。
所以,我的程序在统计文件大小偏小的时候,优势也许不是特别明显。但是,文件大小一旦大了,改程序的优势有明显体现。
项目改进:
美中不足的是,我未能完成对于结果的筛选,就是过滤掉高频词。不过,我有一定的想法,只是实现上还是有点问题,所以没有把代码贴上来。我的想法是,把一系列高频词再建一个树,当我们打印结果前,把统计好的单词依次再这个高频词树中查询,查到了就pass掉,没查到就打印,以此类推打印十个词出来。